Lock-Unlock
 |
Dit is de samenvatting van en perspectief vanuit het federatief datastelsel op het onderzoeksproject Lock-Unlock. Deze samenvatting geeft een globaal beeld van de resultaten van het onderzoeksproject en ligt de focus op de voor het FDS belangrijkste uitkomsten. Er is daarbij geprobeerd vakjargon te vermijden. Het Lock-Unlock project heeft echter veel meer opgeleverd dan wat in deze FDS-samenvatting aan bod komt. De hiernavolgende hoofdstukken bevatten de volledige onderzoeksresultaten, met gebruik van de juiste vaktechnische termen.
Voor wie meer wil weten en lezen, bekijk het volledige Lock-Unlock rapport dat gepubliceerd is op labs.kadaster.nl.
Scope van het Lock-Unlock onderzoeksproject
In het Federatief Datastelsel (FDS) worden generieke functies ingericht met afspraken en standaarden waarmee data eenvoudig in samenhang kan worden gedeeld tussen organisaties uit verschillende sectoren. Linked Data standaarden zijn speciaal ontworpen om data in samenhang te ontsluiten. Daarin zijn de Linked Data standaarden met name gericht op open data. Voor afgeschermde data zijn er geen aangenomen standaarden en is er weinig onderzoek gaande. In het Lock-Unlock project heeft het Data Science Team van het Kadaster onderzocht welke mogelijkheden er zijn om in deze lacune te voorzien, zodat in het FDS ook afgeschermde Linked Data kan worden toegepast. Hiervoor is desk research uitgevoerd en zijn de gevonden mogelijke oplossingen in de praktijk beproefd door een werkende ‘demonstrator’ te realiseren. Daarbij is voortgebouwd op het project Integrale Gebruiksoplossing (IGO) waarmee in 2021 voor open data al de toegevoegde waarde van het toepassen van Linked Data is verkend.
In het Lock-Unlock project is tevens aandacht besteed aan het met Linked Data implementeren van wat in de visie van het FDS bekend staat als ‘ informatiekundige kern’ , het toepassen van identificerende gegevens (‘unieke sleutels’) om betrouwbaar data die betrekking hebben op Wie (personen en organisaties) en Waar (locatie) te combineren.
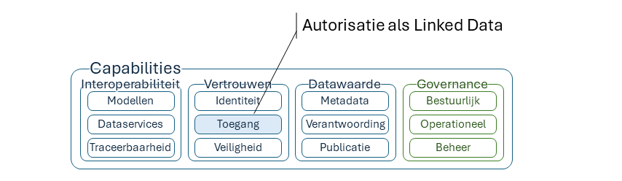
Noodzakelijke afscherming
Bij een federatieve bevraging zijn diverse vormen van afscherming van belang. Autorisatie oplossingen zouden de volgende afschermingspatronen moeten ondersteunen:
- Verticale subsets (de ‘kolommen’ in een tabel): bepaalde kenmerken/attributen van de daarin voorkomende objecten zijn afgeschermd. Voorbeeld: in een dataset met gegevens over kadastrale percelen mag je van percelen wel de koopsom opvragen, maar niet de eigenaar.
- Horizontale subsets (de ‘rijen’ in een tabel): bepaalde objecten (voorkomens) zijn afgeschermd, maar van de objecten waar je wel toegang toe hebt, mag je alle beschikbare kenmerken/attributen opvragen. Voorbeeld: je krijgt als Gemeente X wel alle perceelgegevens, maar alleen van die percelen die binnen jouw gemeente liggen.
- Afscherming relatie-richting: het opvragen van informatie in een bepaalde richting is mogelijk, maar het opvragen van de omgekeerde richting is niet mogelijk. Voorbeeld: je mag van een perceel de naam van de eigenaar opvragen, maar je mag niet op basis van de naam van een eigenaar opvragen welke percelen deze allemaal bezit.
- Aggregatie: gebruikers mogen geen toegang krijgen tot de gedetailleerde gegevens, maar mogen wel geaggregeerde gegevens opvragen. Voorbeeld: niet de verkoopprijzen van een individueel perceel, maar wel de gemiddelde verkoopprijs binnen een postcodegebied.
- Vrije query mogelijkheden ondersteunen: de kracht van Linked Data is dat je zonder een vooraf gedefinieerd inrichtingsschema de data kunt bevragen. Die optie van makkelijk ‘vrij’ door de data kunnen zoeken, wil je blijven behouden.
Zie Lock-Unlock rapport: Afscherming
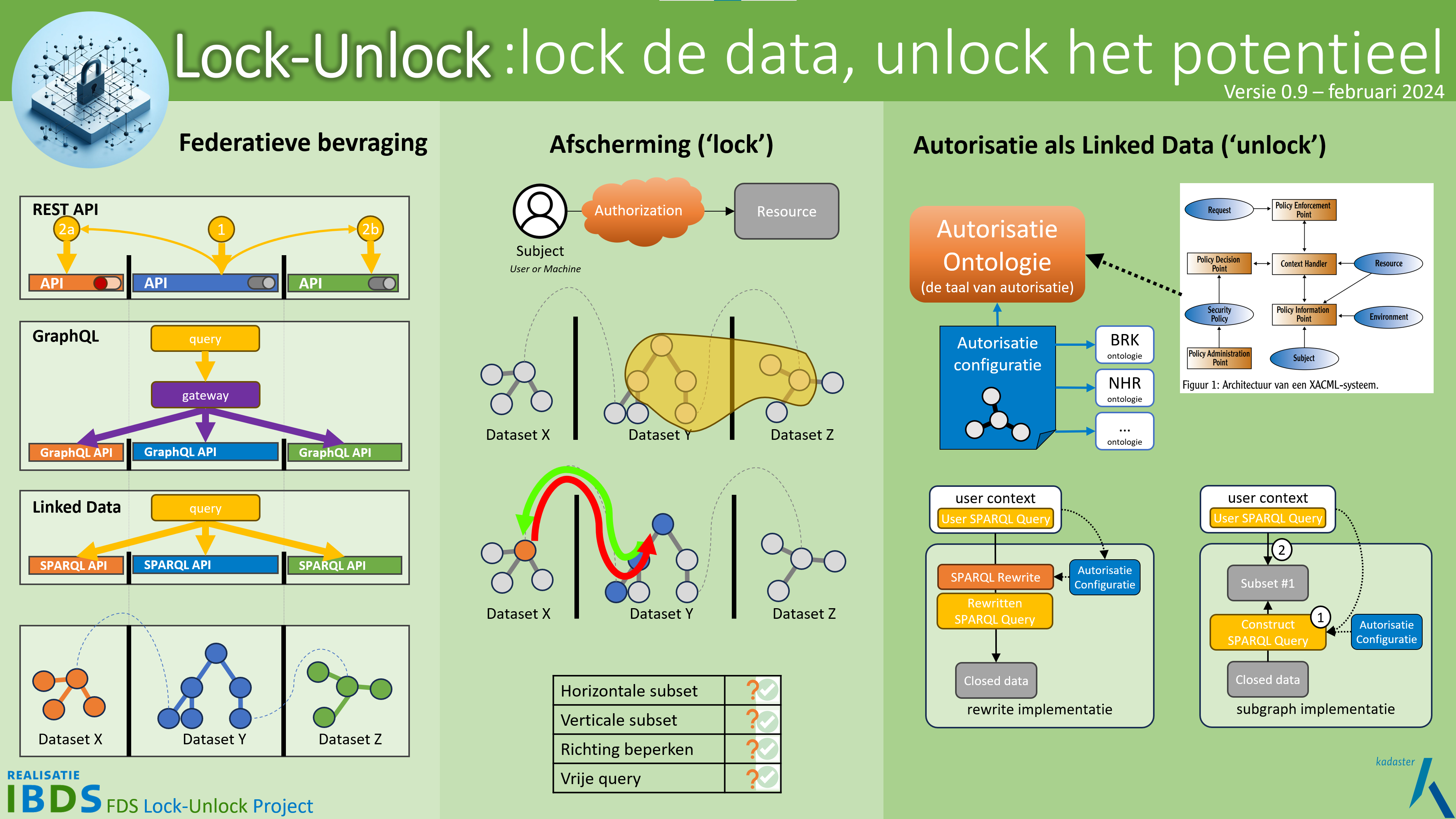
De onderzochte oplossing: het toepassen van een Linked Data ‘autorisatietaal’
In het project is voor de verschillende manieren van afschermen een autorisatietaal ontwikkeld waarmee op een gestandaardiseerde wijze de te implementeren autorisatie kan worden beschreven. Deze beschrijving is eveneens machineleesbaar en voldoet aan de Linked Data standaarden. De in deze taal opgeschreven autorisatieregels vormen daarmee zelf ook een Linked Data set die op de Linked Data manier kan worden bevraagd. Vervolgens is ook beproefd of autorisaties op basis van deze autorisatieregels daadwerkelijk afgedwongen zou kunnen worden. Werkt het ook echt?
Het is een innovatieve manier van het vastleggen van autorisaties die tot nu toe in de Linked Data wereld niet bestond en die de potentie heeft om tot een toekomstige standaard uit te groeien.
Zie Lock-Unlock rapport: Autorisatie als Linked Data
Conclusies op basis van de uitgevoerde praktijkproef
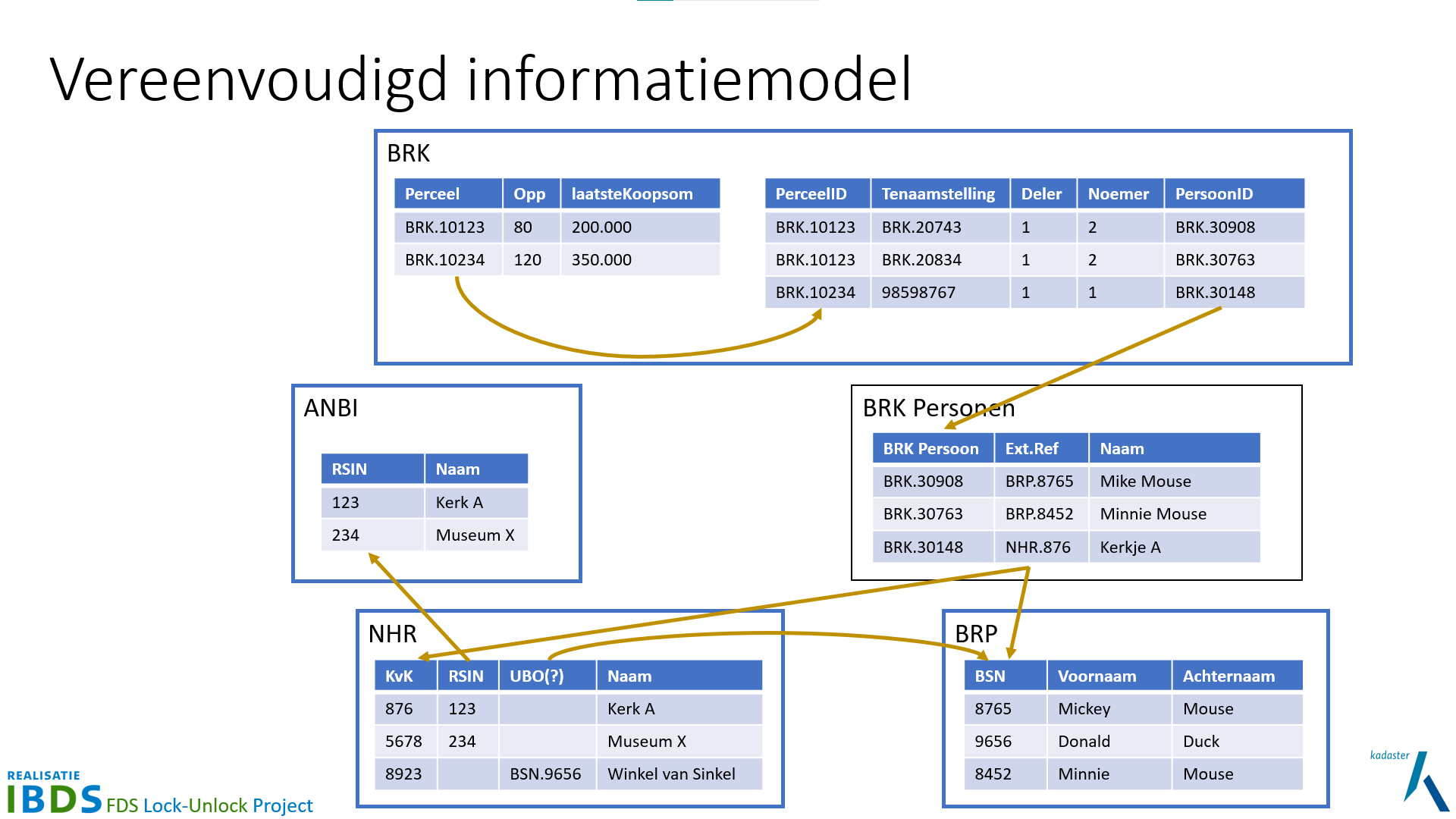
Voor de ontwikkelde autorisatietaal is een praktijkproef (‘proof of concept’) uitgevoerd waarbij deze taal in een lab-omgeving is toegepast om de hiervoor genoemde vormen van afscherming te realiseren. Er zijn twee implementaties gemaakt die verschillende strategieën beproeven in het toepassen van de autorisatieregels. Uiteraard gebruiken beiden dezelfde autorisatieregels in de ontwikkelde autorisatietaal. In de lab-omgeving zijn daartoe met zelf gegenereerde (synthetische) testdata en relevante onderdelen van de informatiekundige kern, het FDS gesimuleerd met een federatieve bevraging over meerdere basisregistraties. Er is gekozen voor een testopstelling van de basisregistraties BRK, de BRP, de BAG en het HR, aangevuld met een dataset die nog niet in het stelsel is opgenomen, de ‘ANBI’ dataset van de Belastingdienst met gegevens over algemeen nut beogende instellingen.
 |
|---|
| Vereenvoudigd Informatie Model als Linked Data (bron) |
Op basis van deze praktijkproef kunnen de volgende conclusies worden getrokken:
- De bedachte oplossing is uitvoerbaar. Het is in de praktijk mogelijk om (geavanceerde) autorisatieregels vast te leggen in Linked Data met behulp van een autorisatietaal die aansluit op al bestaande Linked Data concepten.
- Met deze autorisatietaal en de twee implementatiestrategieën kunnen de horizontale en verticale subsets afscherming gerealiseerd worden. (Voor het afschermen van de richting was te weinig tijd beschikbaar.)
- Als de gegevenscatalogus van een dataset volgens linked data standaarden is opgebouwd, kan deze gebruikt worden om in de autorisatietaal de autorisatieregels te beschrijven direct gekoppeld aan de elementen van de dataset(beschrijving) zelf.
- Er zijn meerdere implementatie strategieën mogelijk die gebruik maken van de autorisatietaal om de autorisatieregels af te dingen. Bij het onderzoek zijn er twee strategieën uitgewerkt en geïmplementeerd. De verschillende strategieën hebben verschillende voor- en nadelen.
- Ook in Linked Data is een goed gebruik van identificerende sleutels van belang om betrouwbare relaties tussen data uit verschillende datasets te kunnen leggen. Door van de betreffende data Linked Data te maken, is het toepassen van het concept van de informatiekundige kern wel veel eenvoudiger. Zo heeft de proef aangetoond dat speciale diensten voor ‘sleutelwisselingen’ (bijvoorbeeld van KvK-nr naar RSIN) niet nodig zijn omdat het Linked Data concept hiervoor standaard oplossingen biedt.
- Bij de eerdere IGO-proef is al gedemonstreerd, dat het op de Linked Data manier ontsluiten het ook voor niet professionele gebruikers mogelijk maakt om heel flexibele de data ‘te bevragen’. Hiermee is het een goede aanvulling op de standaard (REST) API manier om data te ontsluiten, omdat daarbij de vragen van tevoren gedefinieerd moeten zijn (ze zijn voorgeprogrammeerd). Met Lock-Unlock is aangetoond dat de data-aanbieder de door Linked Data geboden flexibiliteit, ook kan inperken, waardoor deze methode ook voor gesloten data kan worden toegepast.
Zie Lock-Unlock rapport: Conclusies
Onderwerpen voor nader onderzoek
Binnen de tijd die voor Lock-Unlock beschikbaar was, kon maar een beperkte diepgang worden bereikt en was het ook niet mogelijk om na te gaan hoe de onderzochte Linked Data manier past binnen de overige mogelijke FDS-standaarden. Voor de volgende onderwerpen is daarom nader onderzoek gewenst:
- Het is ook bij Linked Data mogelijk om het bevragen van de data gedetailleerd te loggen en de logbestanden vervolgens voor analyse te gebruiken. Bijvoorbeeld om achteraf vast te stellen of een bepaalde vraag wel legitiem was. Hoe deze manier van loggen zich verhoudt tot de beoogde manier om in het FDS de verwerking van data te registreren (op basis van de ‘verwerkingenlogging standaard), moet nader worden onderzocht.
- Hetzelfde geldt voor de relatie tussen in Lock-Unlock ontwikkelde Linked Data autorisatietaal en andere manieren om ‘policy based acces control’ te implementeren.
- Er was geen tijd meer beschikbaar om de afscherming op relatie – richting te beproeven. Het is wenselijk om hiervoor een vervolgonderzoek uit te voeren.
- Hoewel voor de wel onderzochte afschermingspatronen de benodigde toegangsbeperking werd geboden, is diepgaander onderzoek nodig om met meer zekerheid vast te stellen dat dit niet omzeild kan worden. Dit is lastig te meten en ook daarvoor is meer onderzoek nodig. • De oplossingen zijn in lab-condities beproefd op kleine test datasets. Aspecten die van belang zijn bij grootschalige toepassing, zoals performance, vielen buiten de scope van het onderzoek. Hoewel er geen indicaties zijn dat opschaling niet mogelijk is, zijn verdere beproevingen in een daarvoor geoptimaliseerde proefomgeving nodig om ook hierover meer zekerheid te krijgen. Dit heeft vooral impact en relatie tot performance van federatieve bevragingen én daar bovenop de toevoeging van de autorisaties daarin en daarvan.
- Het heeft voordelen om de relaties waaruit de informatiekundige kern is opgebouwd met behulp van Linked Data te verduurzamen (als een ‘upper ontology’ in Linked Data vaktaal). Het lijkt de moeite waard om de kosten en baten hiervan verder te verkennen.
Zie Lock-Unlock rapport: Aanbevelingen