IMX
In een federatief datastelsel is het efficiënt benutten van informatie uit verschillende bronnen een behoorlijke uitdaging. Bronregistraties bevatten vaak complexe, hoog-genormaliseerde gegevens, uitgedrukt in sectorgebonden terminologie. Er is dan ook vaak specifieke domeinkennis vereist om gegevens correct te kunnen interpreteren en combineren binnen een bepaalde context. Gebruikerstoepassingen daarentegen, vereisen vaak een veel eenvoudiger en doelgerichter informatiemodel, gericht op het snel kunnen raadplegen van relevante en begrijpelijke informatie, zonder direct geconfronteerd te worden met de complexiteit van de achterliggende databronnen. Dit is waar orkestratie een cruciale rol speelt.
IMX is een set standaarden, ondersteund door een referentie-implementatie, die het mogelijk maakt om gegevens op een model-gedreven manier met elkaar te combineren en beschikbaar te stellen als een nieuw informatieproduct. De referentie-implementatie biedt daarbij een orkestratie-oplossing, die helpt om het combineren van gegevens en de interactie met achterliggende bronnen op een betrouwbare en efficiënte manier invulling te geven. Gegevens blijven daarbij herleidbaar naar hun authentieke bron(nen).

Model Mapping
De IMX Model Mapping standaard specificeert een taal waarmee een vertaalspecificatie (mapping) kan worden opgesteld om vanuit bestaande bronmodellen te transformeren naar een beoogd doelmodel (productmodel). Deze mappingtaal is opgesteld conform een aantal belangrijke basisprincipes:
- Machine-leesbaar: Door de mapping uit te drukken in een machine-leesbaar (YAML-gebaseerd) formaat wordt het o.a. mogelijk om een orkestratie-oplossing aan te sturen en automatisch herkomst vast te leggen, zonder dat er specifieke programmatuur nodig is.
- Implementatie-onafhankelijk: De taal is volledig onafhankelijk van technische implementaties, dataformaten of modelleringsstandaarden. Dit maakt een brede toepassing van de mapping mogelijk.
- Declaratief: De vertaalregels worden beschreven vanuit de intentie van de mapping, zonder expliciet te beschrijven welke stappen hiervoor uitgevoerd dienen te worden. Dit geeft implementaties de vrijheid om zelf de meest optimale strategie te kiezen om gegevens te raadplegen en te combineren.
- Model-gedreven: Om onafhankelijk te blijven van technische datamodellen en bijbehorende dataformaten, wordt de mapping uitgedrukt op logisch niveau. Een logisch datamodel definieert de structuur van gegevens en hun onderlinge relaties, maar is onafhankelijk van de technische implementatie ervan. Dit draagt bij aan de onafhankelijkheid van de mapping ten opzichte van implementaties.
- Stapelbaar: Met stapelbaar wordt bedoeld dat het productmodel van een model mapping ook weer als bronmodel kan dienen in een daarboven gelegen orkestratie. Zo kan de ene organisatie een halffabrikaat leveren, wat weer door een andere organisatie als bron gebruikt kan worden binnen een andere orkestratie-context.
Zowel bron- als doelmodel dient te zijn gemodelleerd op logisch niveau. Dit correspondeert met het MIM beschouwingsniveau 3.
De mappingtaal leunt sterkt op het functional programming paradigma en ondersteunt o.a. de volgende patronen om gegevens te combineren en transformeren:
- Pad-gebaseerde selectie van nodes in een model
- Joinen op unieke sleutels of andere kenmerken (zoals geografische overlap)
- Herschikken structuur (platslaan, of juist nesten)
- Hernoemen attributen en relaties
- Aggregatie/combinatie van waarden
- Functies voor converteren/combineren van waarden
Specificatie: https://docs.geostandaarden.nl/imx/modelmapping/

Lineage Model
Wanneer gegevens worden gecombineerd tot een nieuwe informatieproduct is het van belang dat inzichtelijk blijft welke authentieke brongegevens zijn gebruikt, en welke modificaties (bijv. algoritmes) er zijn gebruikt om tot het eindproduct te komen. Hierdoor is transparant, en kan worden verantwoord, op welke manier gegevens tot stand zijn gekomen. Het IMX Lineage Model is een logisch informatiemodel, waarin de herkomst van gegevens op een gestandaardiseerde manier kan worden uitgedrukt. Dit model is gebaseerd op de internationale open PROV-O ontologie.
Specificatie: https://geonovum.github.io/IMX-LineageModel/
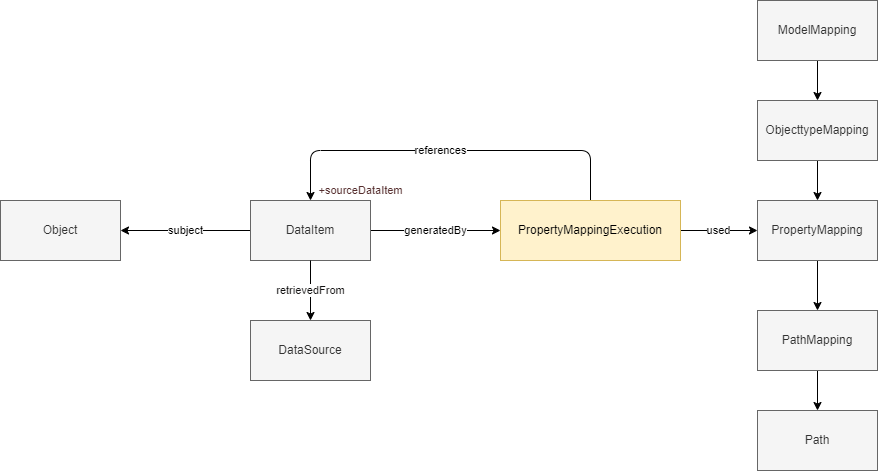
Orkestratie engine
De IMX orkestratie engine is een open source referentie-implementie die op basis van bron- en doelmodellen, gecombineerd met een model mapping, automatisch een orkestratie-service in de lucht brengt. Deze service stelt gegevens als API beschikbaar conform het beoogde doelmodel, waardoor gebruikers-applicaties slechts met 1 enkele service hoeven te interacteren en geen complexe nabewerking hoeven te doen op de brongegevens. Daarnaast houdt de engine tijdens het orkestratie-proces de herkomstgegevens bij en stelt deze beschikbaar conform het IMX lineage model.
De orkestratie-service haalt alle benodigde gegevens realtime op bij de bronnen, waardoor geen kopie benodigd is en gegevens altijd actueel en betrouwbaar zijn. Onder de motorkap worden daarbij diverse optimalisaties toegepast, om dit proces zo efficiënt als mogelijk uit te voeren, waaronder:
- Fijnmazige selectie: Op basis van de selectie van de gebruiker worden alleen de daadwerkelijk benodigde gegevens bij de bronnen opgevraagd. Niet meer, niet minder.
- Query planning: De engine berekent op basis van de gestelde vraag, de mapping en tussentijdse resultaten, wat het meest efficiënte plan is om gegevens bij de bronnen te raadplegen. Sommige stappen kunnen parallel en anderen juist niet, omdat er een onderlinge afhankelijkheid is.
- Batching: Als meerdere gelijksoortige objecten benodigd zijn, en de bron batching ondersteunt, worden deze verzoeken gebundeld tot 1 enkele batch-bevraging.
- De-duplicatie: Als een gegeven al eerder bevraagd is, en op een andere plek nogmaals benodigd is, wordt deze niet opnieuw geraadpleegd.
De orkestatie-engine is backend-onafhankelijk, wat betekent dat er verschillende soorten backend gekoppeld kunnen worden. Een aantal voorbeelden zijn: REST API’s conform de NL API Design Rules, OGC API Features, GraphQL, JSON-bestanden, etc. De implementatie biedt de mogelijkheid om zelf adapters toe te voegen om specifieke API-soorten te kunnen ondersteunen.
Project: https://github.com/imx-org/imx-orchestrate
Beproevingen en onderzoeksvragen
De IMX-beproeving in Digilab heeft aangetoond dat de technologie effectief is in het orkestreren van data uit verschillende bronnen zonder de noodzaak van data-kopieën.
Vanaf augustus ‘24 tot begin volgend jaar (2025) loopt er een vervolgonderzoek, dat zich richt op de uitbreiding van de IMX-methodologie naar niet-geo-registraties. Doel is om door middel van model-gedreven orkestratie gegevens uit verschillende registraties te combineren zonder de noodzaak voor data-kopieën. Belangrijke aspecten zijn het verbeteren van beveiligingsstandaarden (zoals authenticatie en autorisatie) en het aansluiten bij linked data. Dit onderzoek moet bijdragen aan bredere toepasbaarheid en draagvlak binnen de overheid, wat een toekomstbestendige oplossing biedt voor datadeling en integratie binnen het FDS.
Andere uitdagingen die in de toekomst nader onderzocht zouden kunnen worden:
- Welke standaarden en capabilities zouden bronnen aan moeten voldoen om beter geschikt te zijn voor orkestratie?
- Op welke manier past orkestratie binnen proces-geörienteerde applicaties?
- Hoe om te gaan met kwaliteits-afwijkingen in een orkestratie-proces?
- Hoe om te gaan met onbeschikbaarheid in een orkestratie-proces?