Op deze pagina kun je het totaaloverzicht vinden van alle kennis die we hebben ontwikkeld. Deze kennis is volop in ontwikkeling, dit betekent dat het dus nog niet af is. Daar hebben we jullie voor nodig!
Deze omgeving is speciaal ingericht om content met elkaar aan te passen en te vormen op basis van de laatste ontwikkelingen, als team federatief datastelsel hebben we daarom een 0.1 versie ontwikkeld die we vervolgens op verschillende manieren met jullie willen aanvullen en verscherpen. Deze documenten kennen daarmee nog geen formele status. Mocht dit wel al het geval zijn dan kunnen jullie dit op de pagina zelf ook zien.
Kortom, lees je iets waar je op wilt reageren of aan wilt bijdragen? Onder welkom vind je meer info over contributies aanleveren. Benieuwd waarom we hiervoor hebben gekozen? Lees hier de toelichting over deze werkomgeving.
1 - Concept data-ecosysteem Nederlandse overheid
Conceptuele beschrijving van data-ecosysteem voor de Nederlandse overheid
Inleiding
Deze pagina beschrijft een algemeen concept van het data-ecosysteem voor de
Nederlandse overheid. Doel van deze pagina is een context aan te reiken om
de positie van rollen, functies en stelsels op gebied van datadelen, te duiden
ten opzichte van het Federatief Datastelsel in ontwikkeling.
Afhankelijk van de beschrijvingscontext gebruiken we in deze beschrijving het
begrip‘data’ of het begrip ‘gegevens’. Qua betekenis maakt het geen verschil,
de begrippen zijn uitwisselbaar.
Met het begrip ‘organisatie’ bedoelen we op deze pagina een publieke organisatie
van de overheid. Private organisaties duiden we aan met de term ‘bedrijf’.
Data-ecosysteem omschrijven we in deze context als een samenwerkend geheel
van actoren, technologieën en processen om data te verzamelen, op te slaan, te
verwerken, te analyseren en te delen, met het doel om waarde te creëren uit data
ten behoeve van de Nederlandse maatschappij.
De Nederlandse overheid vraagt een data-ecosysteem dat optimaal is afgestemd
op de wijze waarop zij is ingericht en functioneert. De inrichting in
bestuurslagen volgens het ‘huis van Thorbecke’ is de organisatorische basis.
De bestuurslagen, het Rijk, de Provincies, de Waterschappen en de Gemeenten,
hebben ieder hun eigen verantwoordelijkheden. Gezamenlijk vormen ze echter het
geheel van de Nederlandse overheid. De functionele basis komt voort uit de
beleidscycli waar de bestuurslagen individueel en gezamenlijk invulling aan
geven, van beleidsontwikkeling en -vaststelling tot beleidsuitvoering en
-evaluatie.
Naar analogie hiervan vraagt de digitale overheid een digitale basis die
alle bestuurslagen en alle beleidssectoren dient. Die gezamenlijke basis is
federatief opgebouwd. Elke organisatie is verantwoordelijk voor de eigen
digitale informatievoorziening en conformeert tegelijkertijd aan generieke
afspraken en standaarden.
Op hoofdlijnen bestaat de digitale basis uit:
Een zachte infrastructuur van afspraken en standaarden waar elke organisatie,
indien van toepassing, aan conformeert;
Systemen en datastelsels die zich federatief kunnen ontwikkelen binnen ketens
en domeinen;
Een algemeen verbindend stelsel van stelsels, dat specifieke domeinstelsels in
samenhang kan koppelen.
Zo functioneert een ecosysteem dat de beleidscyclus optimaal ondersteunt door
vertrouwd delen en gebruiken van data. Dit resulterend in effectief beleid op
complexe maatschappelijke vraagstukken en voor adequate publieke dienstverlening
die daarmee annex is.
Zonder data geen beleid en geen uitvoering
Afbeelding A: Datastromen Nederlandse overheid
De afbeelding ‘Datastromen Nederlandse overheid’ is afgeleid van een klassieke
overheidsbeleidscyclus en aangevuld met typering en herkomst van de daarin
voorkomende data en datastromen.
De Nederlandse overheid heeft data nodig om invulling te kunnen geven aan haar
taken. Dit betreft zowel data voor beleidsvorming bij complexe maatschappelijke
vraagstukken als data die nodig is om uitvoering te geven aan beleid door middel
van concrete dienstverlening aan de burgers en bedrijven in de maatschappij.
Data voor uitvoering en dienstverlening is ‘operationeel’ van aard en heeft
betrekking op zaken waarin specifieke personen, bedrijven en/of objecten een rol
spelen. Bijvoorbeeld data die nodig is om een rijbewijs af te geven, of om een
door iemand aangekochte auto over te schrijven op diens naam. Voor dergelijke
operationele diensten bestaat altijd een wettelijke grondslag.
Voor beleidsvorming is data nodig over (grootschalige) populaties die een rol
spelen in het betreffende maatschappelijke beleidsvraagstuk. Denk aan data over
uitstoot van bepaalde stoffen door gemotoriseerd verkeer binnen Nederland. Het
spreekt voor zich dat statistische analyses daarin belangrijk zijn. De data voor
dergelijke analyses komen enerzijds voort uit de maatschappij, waarin
bijvoorbeeld een organisatie als CBS een belangrijke bijdrage levert. Anderzijds
vormen de eerder genoemde operationele data een belangrijke bron. De wettelijke
kaders voor beleidsvorming zijn onder andere opgetekend in de Grondwet,
institutionele wetten, de Algemene Wet Bestuursrecht, Ministeriële regelingen en
Koninklijke besluiten. Een belangrijk principe bij gebruik van data voor
beleidsvorming, is beleidsmatige rechtvaardiging en proportionaliteit.
De operationele data die de overheid verzamelt en produceert bij de uitvoerende
taken kunnen dus een belangrijke bron van informatie vormen voor
maatschappelijke vraagstukken. Tegelijkertijd kunnen operationele data die
voortkomen uit dienstverlening ook heel bruikbaar zijn bij andere vormen van
dienstverlening. De
Nederlandse Overheid Referentie Architectuur (NORA) stelt
expliciet bij de (implicaties van)
architectuurprincipes:
Maak zo veel mogelijk gebruik van gegevens die reeds beschikbaar zijn in
plaats van deze gegevens opnieuw te verzamelen of te creëren.
In bepaalde gevallen is zelfs sprake van verplichting. Voor efficiënte en
effectieve uitvoering van haar taken is de Nederlandse overheid derhalve enorm
gebaat bij het eenvoudig en verantwoord kunnen delen van ‘haar eigen’ data.
Gegevens interpreteren en gebruiken in context
Organisaties gebruiken gegevens voor uitvoering van hun publieke taak. Die
gegevens ontstaan door registratie van handelingen en besluiten van de
organisatie zelf en door inwinning. Inwinnen gebeurt door gegevens op te vragen
bij betrokken personen en bedrijven, of door situaties waar te nemen en die te
registreren. Maar ook kan een organisatie gegevens voor hergebruik verkrijgen
van een of meer collega-organisaties.
Het verkrijgen en gebruiken van gegevens gebeurt altijd binnen een bepaalde
context. Omstandigheden zoals doel, achtergrond, plaats en tijd van inwinning en
gebruik, zijn van invloed op hoe de gegevens begrepen moeten worden.
De context van een gegeven kan heel specifiek zijn, maar kan ook algemener van
aard zijn. Zo worden binnen het zorgdomein gegevens gebruikt over patiënten.
Binnen het onderwijsdomein gebruikt men gegevens over studenten. In beide
gevallen gaat het om gegevens over personen. Eenzelfde persoon kan een rol
spelen in beide domeinen, bijvoorbeeld als hij student is en ziek wordt,
waardoor hij als patiënt een behandeling moet ondergaan. De gegevens van de
persoon als student en tevens patiënt hebben een meer algemene context als het
gaat om kenmerken als naam, adres en leeftijd. Een meer specifieke context geldt
voor kenmerken als ‘genoten vooropleiding’ en ‘bloeddruk gemeten voor
behandeling’.
De gegevenskenmerken met de algemenere context kunnen in beide domeinen worden
gebruikt. Ze kunnen (indien toegestaan) worden verkregen uit een domein met een
algemenere context. Het stelsel van basisregistraties kan gezien worden als een
meer ‘algemeen domein’. Gegevenskenmerken met specifieke context worden
aanvullend geregistreerd binnen het betreffende specifiekere domein.
Gegevens met een specifieke context zijn vooral of voornamelijk relevant binnen
een specifiek domein of keten, terwijl gegevens met een algemenere context
eerder geschikt zijn voor (her)gebruik in andere contexten. De algemenere
gegevens kunnen daardoor ook geschikt zijn als basisgegeven en breed gedeeld
worden.
Afbeelding B: Voorbeeld datagebruik in sectoren
Zoals hiervoor al aangegeven, kan een organisatie gegevens ook voor hergebruik
verkrijgen van een collega-organisatie. Het is een belangrijk beginsel dat
organisaties van de overheid gebruik maken van gegevens die al binnen de
overheid bekend zijn. In het algemeen wordt dit aangeduid als hergebruik of
gezamenlijk gebruik.
Hiervoor is het echter wel noodzakelijk om de context van gegevens te kennen.
Zowel de context van waaruit een gegeven is ingewonnen als de context waarin het
gegeven gebruikt gaat worden. In de algemene kenmerken van een persoon kunnen
bij de inwinning bijvoorbeeld formele aanschrijftitels zijn opgenomen. Maar in
correspondentie met die persoon kunnen afhankelijk van de omstandigheden
(context) andere minder formele aanschrijftitels wenselijk zijn. Zonder kennis
van de context kan het bijvoorbeeld gebeuren dat bij hergebruik van het gegeven
in een informele context, de persoon ongewenst wordt aangeschreven met zijn
formele titulatuur.
De context plaatst een gegeven dus in het juiste perspectief waardoor het
mogelijk wordt de (her)bruikbaarheid ervan te interpreteren in een
andere context. Bij het bepalen van de herbruikbaarheid gaat het op hoofdlijnen
om drie vragen:
Is het gegeven in semantische zin bruikbaar in de nieuwe context?
Is het juridisch toegestaan om het gegeven in de nieuwe context te gebruiken?
Is het ethisch verantwoord om het gegeven in de nieuwe context te gebruiken?
Patronen van gegevens delen
Bij gezamenlijk gebruik worden doorgaans gegevens uit verschillende bronnen
gebundeld tot een bruikbaar geheel. Herkenbare patronen daarbij zijn cumulatie,
consolidatie en compilatie.
Cumulatie en consolidatie
Cumulatie en consolidatie komen voor als organisaties dezelfde type gegevens
verzamelen. Ze leggen deelverzamelingen aan die elkaar aanvullen maar elkaar
misschien ook overlappen. Dit zien we bijvoorbeeld bij lokale of regionale
organisaties. Elke lokale organisatie beheert een deelverzameling van het
landelijke totaal.
Cumulatie is het samenbrengen of optellen van afzonderlijke deelverzamelingen.
Het benadrukt de ‘opeenstapeling van data’ zonder dat er een specifieke nadruk
ligt op consistentie of integratie.
Consolidatie gaat verder dan cumulatie, omdat het niet alleen gaat om het
samenvoegen van data, maar ook om het creëren van een ‘geïntegreerd en consistent
geheel’. Bij consolidatie worden deelverzamelingen geschoond, gecombineerd en
gestructureerd om een uniforme verzameling te vormen.
Dit proces zorgt voor consistentie en integriteit van de data en verbetert daarmee de bruikbaarheid ervan.
Inconsistenties kunnen ook achteraf tijdens gebruik van de data nog worden opgemerkt
en opgelost.
Compilatie
Bij compilatie gaat het om samenbrengen van data uit verschillende bronnen voor
een specifiek doel, bijvoorbeeld het maken van een rapport of het voorbereiden
van een analyse. Afhankelijk van de noodzaak om data samen te brengen, te
structureren en/of te verrijken, kan het proces van compilatie gebruik maken van
cumulatie en consolidatie, naast aanvullende regels voor het afleiden van
gegevens. Bij compilatie ligt de nadruk vaak op het ‘organiseren en verrijken
van de data in een samenhangende vorm’ die kan worden gepresenteerd of verder
geanalyseerd.
Een gecompileerde verzameling bestaat vaak uit data van verschillende soorten,
welke aan de hand van overeenkomstige sleutelgegevens worden samengevoegd en
vaak verrijkt met afgeleide gegevens. Binnen ketens is dit een veel toegepast
patroon voor operationele data in de uitvoering van publieke
dienstverlening.
Een andere belangrijke vorm van compilatie betreft statistische data ten
behoeve van beleidsontwikkeling. Hiervoor worden gegevens over bepaalde
populaties samengevoegd, geaggregeerd en voorzien van gemeten eenheden.
Bijvoorbeeld aggregatie van voertuigdata op het kenmerk ‘soort voertuig’. Daar
kan vervolgens het aantal voorkomens per soort voertuig aan worden toegevoegd.
Samenhang patronen voor gezamenlijk gebruik van data
Samenvattend vormen cumulatie, consolidatie en compilatie een logische volgorde
in de patronen bij gezamenlijk gebruik van data:
Cumulatie kan de eerste stap zijn waarbij gegevens uit meerdere bronnen worden
verzameld.
Consolidatie zorgt ervoor dat de gecumuleerde gegevens worden geïntegreerd in
een consistent en bruikbaar geheel, waarbij inconsistenties worden opgelost.
Compilatie komt vaak na consolidatie en houdt in dat de gestructureerde
gegevens worden samengesteld voor een specifieke toepassing, zoals gebruik in
een andere context of voor analyse en rapportage.
Datadomeinstelsel
Delen van data vergt afspraken tussen aanbieders en afnemers. Vaak begint dat
met een paar organisaties die samen willen werken. Er ontstaat een klein
afsprakenstelseltje. Meer organisaties krijgen interesse en sluiten aan op het
afsprakenstelseltje. Verdere uitbreiding gepaard met professionalisering op
gebied van interoperabiliteit, standaardisatie, organisatorische inrichting,
generieke functies en anderszins, laten prille datadeelrelaties zo uitgroeien
tot een datadomeinstelsel (DDS).
De afbeelding toont in samenhang de procesmatige en organisatorische componenten
van een datadomeinstelsel in het algemeen.
Afbeelding C: Concept datadomeinstelsel
Een datadomein bestaat bij de gratie van organisaties die de data inzamelen,
produceren en bewaren. Zij zijn bronhouder. De
bronhouder is degene die toegang verleent tot de data. Elke
dataverzameling valt onder de verantwoordelijkheid van de bronhouder binnen wiens
context de verzameling is/wordt opgebouwd en onderhouden.
Organisaties met de rol van ‘data-aanbieder’ zorgen ervoor dat data van
bronhouders worden verwerkt tot dataproducten waar
concrete behoefte aan bestaat. De aanbieder
cumuleert, consolideert en/of compileert gegevens tot een dataproduct binnen
het domein. De aanbieder zorgt eveneens voor het maken, publiceren
en aanbieden van de datadiensten waarmee het dataproduct kan worden afgenomen.
Organisaties met de rol van ‘data-afnemer’ kunnen op de datadienst
aansluiten. De onderhavige data laten ze op verantwoorde wijze binnen
de eigen context gebruiken.
Merk op dat bronhouder, data-aanbieder en data-afnemer
rollen zijn waar organisaties invulling aan kunnen geven. Een organisatie kan
een of meerdere rollen vervullen m.b.t. zowel dezelfde data als verschillende
data.
M.b.t. de totaalverantwoordelijkheid voor het datadomein kunnen generieke
afspraken worden gemaakt over de (formele) inrichting ervan. Zo’n
inrichting kan ook bij wet worden bestendigd, zoals dat bij landelijke
voorzieningen wel het geval is.
Stelsel van stelsels
Een datadomeinstelsel is, zoals de term het al aangeeft, bedoeld voor de
deelnemers in het betreffende datadomein. Om data te kunnen delen tussen
domeinen, moeten de datadomeinstelsels interoperabel zijn met elkaar. Deze
interoperabiliteit is echter niet vanzelfsprekend. Er is een stelsel nodig dat
de datadomeinstelsels met elkaar verbindt.
Afbeelding D: Concept Stelsel van Datadomeinstelsels
De datadomeinen beschikken over de kennis om data binnen het domein te
verbinden, te delen en te gebruiken. Een verbindend stelsel heeft niet de taak
en niet het vermogen om specifieke sector- of domeinvraagstukken op te lossen.
Het zorgt in plaats daarvan voor een generieke zachte infrastructuur, bestaande
uit afspraken en standaarden die datadomeinstelsels kunnen toepassen om
onderling vertrouwd data te kunnen delen. Het stelsel van stelsels ondersteunt
dit met generieke besturingsfuncties en eventueel generiek toepasbare
voorzieningen. Zo maakt het domein- en sector-overstijgend delen van data
mogelijk en vervult daarmee een brugfunctie.
De huidige bij wet bepaalde basisregistraties vormen al een verbindende factor
tussen verschillende overheidstaken, -processen en -registraties. Ze kennen elk
een ingericht stelsel van partijen en afspraken over inwinnen, vastleggen,
kwaliteit, toezicht, rolverdeling, beschikbaar stellen, etc. Ze vormen daarmee
een ‘algemeen’ datadomeinstelsel, zie ook afbeelding B op deze
pagina.
De ontwikkeling van een ‘stelsel van stelsels’ kan daarmee zeker voortgaan op
wat reeds voorhanden is binnen het stelsel van basisregistraties, maar het zal
zich daar niet toe beperken. De basisregistraties vormen een belangrijke basis
bij het benutten van het datapotentieel voor maatschappelijke opgaven. Maar
daarnaast is er nog veel onbenut potentieel in sector- en ketenregistraties. De
NORA beschrijft sowieso al zo’n
145 sectorregistraties. Om de potentie van deze
data ook te benutten zal veel meer over sectoren en domeinen heen ontsloten
moeten worden.
Federatief Datastelsel (FDS)
De interbestuurlijke datastrategie is gericht op het effectiever laten
functioneren van het data-ecosysteem van de Nederlandse overheid. Daarvoor is
het volgende beleidsdoel geformuleerd:
‘Als overheid benutten we het volle potentieel van data bij maatschappelijke
opgaven, zowel binnen als tussen domeinen, op een ambitieuze manier die
vertrouwen wekt.’
Als één van de middelen om dat doel te bereiken benoemt de strategie de
systeemfunctie ‘Federatief Datastelsel’ (FDS). Een federatief ingericht stelsel
past goed in het ‘Huis van Thorbecke’.
Een data-federatie beschouwen we als een samenwerking tussen de leden op basis
van wetten en collectieve afspraken over het delen en gebruiken van elkanders
data. De leden van de federatie zijn en blijven verantwoordelijk voor de
kwaliteit van de data die ze inbrengen. Het hergebruik van ingebrachte data valt
onder de verantwoordelijkheid van de hergebruikende organisatie. De leden
conformeren aan het collectieve kader van stelselafspraken en relevante
wetgeving.
De systeemfunctie ‘Federatief Datastelsel’ positioneren we in het concept
data-ecosysteem als ‘Stelsel van stelsels’. Het realisatieprogramma FDS (rFDS)
is gericht op ontwikkeling en implementatie van de ‘zachte infrastructuur’ die
nodig is om de datadomeinstelsels te verbinden en daarmee het data-ecosysteem te
laten functioneren.
Achtergrond van FDS, vertaald naar ambitie van FDS. Verder een korte schets van de beoogde werking van het FDS.
Het Federatief Datastelsel is geënt op de ‘Interbestuurlijke datastrategie‘,
d.d. oktober 2021 en op het ‘Toekomstbeeld Basisregistraties’, d.d. 16 december
2021.
Interbestuurlijke datastrategie
Het belangrijke beleidsdoel van de interbestuurlijke datastrategie luidt als
volgt:
‘Als overheid benutten we het volle potentieel van data bij maatschappelijke
opgaven, zowel binnen als tussen domeinen, op een ambitieuze manier die
vertrouwen wekt.’
Een met maatschappelijke opgaven meegroeiend Federatief Datastelsel is een
belangrijk instrument voor het realiseren van deze beleidsdoelstelling, zoals
ook wordt weergegeven met de bijgaande afbeelding uit het rapport
‘Interbestuurlijke datastrategie’.
Meegroeiend Federatief Datastelsel
Toekomstbeeld basisregistraties
Belangrijke kernpunten uit het toekomstbeeld basisregistraties zijn onder
andere:
FDS maakt hoogwaardige data binnen de overheid – over organisatie- en
domeingrenzen heen – beschikbaar om:
dienstverlening aan burgers en bedrijven te verbeteren en
sneller en beter in te spelen op maatschappelijke opgaven.
Op basis van formele afspraken werken deelnemers van FDS samen om
hoogwaardige gegevens voor meervoudig gebruik beschikbaar te stellen.
FDS stelt de volgende principes centraal:
“decentraal als kan, centraal als moet” en
“afspraken gaan boven standaarden, standaarden gaan boven voorzieningen”.
FDS versterkt de positie van burgers en bedrijven door het verankeren van
principes als privacy, transparantie en accountability en
beleidsuitgangspunten als het voeren van regie op de eigen gegevens.
FDS stelselafspraken worden transparant ontwikkeld en vastgelegd en zijn
daardoor toetsbaar. Dit bevordert het maatschappelijk draagvlak voor het
gebruik van stelseldata.
FDS ondersteunt verantwoord meervoudig gebruik van data. Dit kan met
afspraken, standaarden en technische- en organisatorische functies worden
ingevuld. Daarbij zijn nog implementatiekeuzes mogelijk.
Het toekomstbeeld onderscheidt verschillende categorieën van data. Dat geeft
richting aan de verdere ontwikkeling en positionering van basisregistraties en
andere registraties zoals domein- of ketenregisters. Classificatie van soorten
registers bepaalt welk niveau van stelselafspraken van toepassing moet zijn.
Dit voorkomt dat alle stelseldata aan de strengste eisen moeten voldoen en
houdt zo de ontwikkeling van FDS beheersbaar en betaalbaar.
Ambitie Federatief Datastelsel
De uitdaging voor FDS is om eenvoudig en vertrouwd delen van data door de
overheid mogelijk te maken.
Daarmee wil FDS bereiken dat:
De samenleving, burger en ambtenaar vertrouwen hebben in datadeling binnen het
Federatief Datastelsel; het is verantwoord, met aandacht voor publieke waarden
en aansluitend op de ontwikkelingen in de EU.
De aanpak van maatschappelijke vraagstukken is effectiever doordat meer
hoogwaardige data voor meervoudig gebruik beschikbaar zijn.
Dit zal resulteren in:
(Ten opzichte van het huidige Stelsel van Basisregistraties.) Een federatie
met meer datahouders, rijker aanbod van stelseldata, meer
gebruikers(organisaties) en intensief gebruik van stelseldata, conformerend
aan de aansluitvoorwaarden.
Samenhangende stelselfuncties die zorgen voor de sturing op en de beoogde
werking van het Federatief Datastelsel als vertrouwenssysteem van datagebruik.
Structurele (door)ontwikkeling van het Federatief Datastelsel via
(maatschappelijke) use cases en een innovatiewerkplaats voor experimenteren en
beproeven.
Structurele governance en financiering voor beheer en doorontwikkeling van het
stelsel.
Overzicht en inzicht in beschikbare data door een flinke uitbreiding van
ontsloten open en beschermde data via datacatalogi.
Samenvattend is het de ambitie van FDS om Nederlandse overheidsorganisaties op
eenvoudige en verantwoorde wijze hun data met elkaar te laten delen ten bate van
maatschappelijke vraagstukken en publieke dienstverlening. Zodat de Nederlandse
overheid meer maatschappelijke waarde kan genereren uit de (data)middelen
waarover ze op grond van haar wettelijke taken beschikt.
Hoe het FDS gaat werken
‘Het Federatief Datastelsel’ is een afsprakenstelsel in opbouw. Het project
Realisatie Federatief Datastelsel ontwikkelt functies om aanbieders en afnemers
van data uit alle beleidsdomeinen op een juridisch en ethisch verantwoorde
manier data te laten delen. De functies zijn ingebed in een afsprakenstelsel dat
waar nodig is verankerd in wetgeving. Het afsprakenstelsel kan verder worden
aangevuld met concrete standaarden en voorzieningen. Data, data-aanbieders,
data-afnemers en en datadiensten in het stelsel, kunnen zo worden voorzien van
een ‘FDS-label’ dat duidelijk maakt dat zij voldoen aan het FDS-afsprakenkader
(waaronder bijvoorbeeld FDS aansluitvoorwaarden). Stelselfuncties zoals
‘toezicht houden’ zorgen ervoor dat deelnemers structureel conformeren, ook na
eventuele wijzigingen binnen het stelsel. Dit alles levert een vertrouwensbasis
waarbinnen deelnemers aan het stelsel verantwoord data kunnen delen met andere
deelnemers.
Om data te delen maken stelseldeelnemers in de rol van data-aanbieder deze data
binnen het stelsel beschikbaar. Dat gebeurt door het leveren van datadiensten.
De data-aanbieder publiceert de metadata over de data en diensten die hij
beschikbaar stelt, zodat een (potentiële) data-afnemer kan bepalen of dit voor
hem bruikbaar is.
Voor het feitelijke datadelen zorgen de deelnemers zelf dat ze kunnen beschikken
over de benodigde infrastructurele en functionele voorzieningen. Deze
voorzieningen zijn zodanig ontwikkeld en ingericht dat ze conformeren aan de
relevante stelselafspraken en -standaarden. Gebruik van eventuele generieke
FDS-voorzieningen is geen verplichting, tenzij dat voor specifieke situaties
binnen het stelsel is afgesproken en als zodanig vastgelegd in
FDS-afsprakenkader.
3 - Scope van FDS
Het Federatief Datastelsel (FDS) richt zich op publieke gegevens uitwisseling op nationaal niveau, ingebed in Europese kaders.
FDS ontwikkelt zich tot een afsprakenstelsel dat het datapotentieel van
verschillende sector-, domein- of thematisch georiënteerde datastelsels in
overeenstemming met publieke waarden voor publieke doelen beschikbaar maakt.
Stelsel van stelsels
Met de beschrijving van het Concept data-ecosysteem Nederlandse overheid
schetsen we de algemene context waarin het FDS zal functioneren als het
verbindende stelsel van datadomeinstelsels (DDS).
Het Stelsel van Basisregistraties kunnen we beschouwen als een samenstel van
DDS-en. Daarnaast kennen we een variëteit aan keten- en sectorale registraties
die we ook als (producten van) DDS-en kunnen beschouwen. Ook de ontwikkelingen
op dit gebied staan niet stil. Zo lopen er diverse initiatieven die zijn gericht
op ontwikkeling van nieuwe datadomeinstelsels, o.a. in domeinen als GEO,
mobiliteit, zorg, etc.
FDS is gericht op de uitwisselbaarheid (of interoperabiliteit) van data tussen
deze bestaande en zich ontwikkelende DDS-en. Hiermee voorkomt FDS dat de DDS-en
de nieuwe silo’s gaan worden.
Het realisatieprogramma (R-FDS) ontwikkelt daarvoor de (zachte) infrastructuur
van afspraken, standaarden en werkwijzen die de interoperabiliteit (of
uitwisselbaarheid) tussen de DDS-en en hun participanten moet waarborgen. FDS
vervult daarmee een brugfunctie en is het verbindende stelsel van stelsels.
De domeinoverstijgende datadeel-relaties worden ondersteund door adequate
beschrijving van de data (de metadata) waaronder de benoeming van de
sleutelgegevens die nodig zijn om gegevens uit verschillende registraties te
kunnen combineren.
Wettelijke grondslag
Uitgewisselde gegevens binnen FDS moeten juridisch en ethisch verantwoord
meervoudig gebruikt kunnen worden in publiek belang. FDS borgt daarmee de
publieke waarden en biedt tegelijk de data-afnemers het vertrouwen en de
zekerheid dat zij hun publieke dienstverlening op data uit het stelsel kunnen en
mogen baseren. Data in het stelsel moet daarom een wettelijke grondslag hebben.
FDS is derhalve gericht op publieke databronnen en hergebruik van de data door
Nederlandse organisaties met een wettelijke taak. Met het oog op dat hergebruik
moet gezorgd worden dat stelseldata door afnemers voor hún wettelijke taken
gebruikt kunnen worden. Momenteel wordt onderzocht welke aanpassingen hiervoor
nodig zijn in wet- en regelgeving.
4 - Uitgangspunten van FDS
De uitgangspunten voor het basisconcept van het Federatief Datastelsel.
Grip op data
Een belangrijk uitgangspunt binnen de Europese kaders voor ontwikkelen van
dataruimten, is de zogenoemde ‘data soevereiniteit’. Ruwweg stelt dit
uitgangspunt dat deelnemers aan datastelsels zeggenschap behouden over hun eigen
data en het delen ervan met andere deelnemers.
FDS beschouwen we als het Nederlandse publieke datastelsel. Het maatschappelijk
belang is leidend bij het datadelen via FDS. De publieke waarden dienen daarbij
dus geborgd te zijn. Die waarden en de daaruit voortvloeiende beginselen zijn in
wet- en regelgeving en in overheidsbeleid verankerd. De stelseldeelnemers hebben
de plicht en verantwoordelijkheid om daarnaar te handelen. De
FDS-stelselmechanismen leveren de deelnemers aan het stelsel voldoende grip op
de data om deze op verantwoorde wijze met elkaar te kunnen delen.
Deze sturing vanuit het overkoepelende maatschappelijke belang, begrenst dus de
autonomie van de individuele stelseldeelnemers. Dit is een belangrijk verschil
t.o.v. data-ecosystemen met een private ‘datamarkt’, waarin deelnemers op basis
van economische motieven zelf bepalen met wie en onder welke condities zij data
delen.
Decentraal wat kan en centraal wat moet
In het federale stelsel conformeren de leden zich aan collectieve afspraken,
standaarden en eventueel voorzieningen. Het uitgangspunt is om voorzieningen
alleen verplicht te stellen als dat functioneel noodzakelijk is om de doelen van
FDS te realiseren. Verplicht te gebruiken zijn bepaalde centrale voorzieningen
alleen als dat in wetgeving of de collectieve afspraken zo is opgenomen.
Met collectieve afspraken wordt o.a. bedoeld de richtlijnen, convenanten en
standaarden die worden benoemd in een formeel vast te stellen en te onderhouden
FDS-afsprakenkader.
Afspraken boven (open) standaarden boven voorzieningen
FDS gaat uit van het beginsel ‘afspraken gaan boven standaarden en standaarden
gaan boven voorzieningen’. De nadruk ligt niet op realisatie en beheer van
(generieke) IT-voorzieningen, maar op ontwikkelen en toepassen van generieke
afsprakenkaders en standaarden.
Het principe houdt in dat voor stelseldoelen die volledig behaald kunnen worden
met een of meer bindende stelselafspraken, geen stelselstandaard of
stelselvoorziening wordt ontwikkeld. Als stelselafspraken alleen niet toereikend
zijn, kan (ook) een stelselstandaard worden afgesproken. Pas als ook een
stelselstandaard niet toereikend is, kan een generiek toepasbare
stelselvoorziening worden ontwikkeld.
Voor standaarden hanteert FDS de eis dat dit open standaarden zijn.
Data bij de bron
Het werken conform ‘data bij de bron’ is een belangrijk beginsel bij de
realisatie van de digitale overheid en daarmee ook voor de realisatie van het
Federatief Datastelsel.
De Nederlandse overheid streeft naar goed hergebruik van data. De hergebruikte
data wordt door de afnemer/gebruiker echter nog vaak als kopie opgeslagen.
Veelal gebeurt dit omdat het voor bepaalde functionaliteit of door in capaciteit
beperkte infrastructuur, noodzakelijk is. De technologische vooruitgang zorgt er
inmiddels voor dat infrastructuur in veel mindere mate een beperkende factor is.
Daarnaast zijn er technologische paradigma’s die zich richten op het sturen van
functionaliteit naar de brondata om die daar uit te voeren en het resultaat
retour te sturen. Dit opent mogelijkheden om het kopiëren van data te beperken
en deze direct bij de bron te gebruiken.
Data bij de bron leidt tot hogere datakwaliteit, meer veiligheid en betere
bescherming van privacy;
Geen fouten door onnodige kopieerslagen;
Data op één plek is beter te beveiligen en biedt betere bescherming van
privacy;
Makkelijker data kunnen corrigeren, omdat het maar één keer hoeft te gebeuren;
De overheid kan makkelijker inzicht geven in het gebruik van data;
De totale hoeveelheid data binnen de overheid vermindert (dataminimalisatie).
Naar verwachting zal distribueren en kopiëren van data om uiteenlopende redenen
nooit helemaal verdwijnen. Het streven is wel om het zoveel mogelijk te
beperken. FDS zal daarom voorzien in de mogelijkheid om gewaarmerkte kopieën in
het stelsel onder te brengen. Er zijn twee situaties waarin een kopie geldt als
gewaarmerkt:
Als deze aantoonbaar onder controle is van de partij die ook de bron
ontsluit;
Als deze noodzakelijk is voor het betrouwbaar genereren van afgeleide
dataproducten.
Binnen FDS betekent werken volgens data bij de bron dat de bron rechtstreeks
(via een API) wordt bevraagd op de gegevens die nodig zijn voor de uit te voeren
taken. Via de API ontvangt de afnemer, het antwoord op de gestelde vraag. De
afnemer krijgt (een kopie van) de data die nodig is of het antwoord op een
algoritmische bewerking van de data (bijvoorbeeld een ja op de vraag of iemand
ouder is dan 18 jaar). Dataminimalisatie is hierbij een belangrijk doel. Het
verzenden van complete kopie-datasets zoals in de huidige situatie nog gebeurt,
zal daarmee zoveel mogelijk worden voorkomen.
Het streven naar het principe ‘data bij de bron’ zal de nodige bereidheid tot
verandering vergen van de betrokken organisaties in het digitale
overheidsdomein. Vanuit FDS sturen we o.a. op het geven van inzicht in de
wettelijke grondslag(en) en mogelijke gebruikscontexten van de data in het
stelsel. Verder stimuleren we door actieve promotie het concept en de toepassing
ervan, in samenwerking met het programma ‘Data bij de bron’.
FDS is gericht op het optimaal en vertrouwd kunnen delen van data. Hiervoor is
een raamwerk nodig dat vertrouwen creëert en waarborgt. Het fundament van het
vertrouwensraamwerk is wetgeving, die de verantwoordelijkheid en inrichting
regelt voor functies en mechanismen in het stelsel die waarborgen bieden voor de
volgende aspecten:
veilig en verantwoord gebruik van data,
waarborgen van privacy,
rechtmatige en gerechtvaardigde toegang tot data,
transparantie over aanbod en gebruik van data,
faciliteren van certificeringen en audits,
toezicht en audits,
…
Deze mechanismen moeten het vertrouwen van de deelnemers in het stelsel
vergroten. De uitwerkingen van stelselfuncties zullen resulteren in het
vertrouwensraamwerk.
5 - Basismodel
Het basismodel van het Federatief Datastelsel
Inleiding
Deze pagina beschrijft het basismodel van het Federatief Datastelsel (FDS), dat
als stelsel van stelsels deel uitmaakt van het Concept data-ecosysteem Nederlandse overheid.
Het vervangt de eerder opgestelde
‘houtskoolschets’
die is gepubliceerd tijdens de stelseldag in november 2022.
Dit basismodel vormt het vertrekpunt voor de verdere uitwerking van FDS in een
doelarchitectuur. Het is niet ‘in beton gegoten’, maar tegelijkertijd is het wel
een ankerpunt dat niet voortdurend kan veranderen. Daarom is dit een abstract en
zo kort mogelijk verhaal met doorverwijzingen naar diepgaandere uitwerkingen.
Concreet bestaat het basismodel uit een compact diagram met een korte
aanvullende beschrijving. Eventuele wijzigingen aan het concept moeten
weloverwogen worden aangebracht, rekening houdend met de gevolgen ervan voor de
diepere uitwerkingen.
Context
Complexe maatschappelijke opgaven vragen steeds vaker om samenwerking binnen en
tussen sectoren, in ketens en netwerken waarin gegevens gezamenlijk worden
gebruikt. De Interbestuurlijke Datastrategie
beschrijft een strategie gericht op een beter gebruik van het datapotentieel van
en door de Nederlandse overheid. Niet alleen beter gebruik, maar ook juridisch
en ethisch verantwoord gebruik. Een effectief functionerend Federatief
Datastelsel (FDS) wordt daarbij gezien als een essentieel middel op nationaal
niveau, ingebed in Europese kaders.
De vraag naar stelseldata wordt ingevuld doordat een Data-afnemer een of
meer datadiensten afneemt van een of meer data-aanbieders. Voor de afnemer
geldt evenals voor de aanbieder dat hij structureel en aantoonbaar voldoet aan
de FDS-deelnamevoorwaarden.
Om aan te sluiten op datadiensten van een data-aanbieder, maakt de
data-afnemer gebruik van een toepassing die conform de afspraken en
standaarden van het stelsel is ontworpen en geïmplementeerd.
Het data-aanbod krijgt gestalte doordat Data in het stelsel wordt
ingebracht vanuit (organisaties in) datadomeinstelsels (zie ook
Data-ecosysteem Nederlandse overheid.
Voor de aanbieder geldt evenals voor de afnemer dat hij structureel en
aantoonbaar voldoet aan de FDS-deelnamevoorwaarden.
Beschikbare data wordt door een Data-aanbieder aangeboden door middel van
datadiensten.
FDS heeft mechanismen om te borgen dat data betrouwbaar en vertrouwd in het
stelsel kan worden gedeeld en dat dit juridisch is toegestaan en ethisch is
verantwoord. Daarvoor wordt het stelsel opgebouwd aan de hand van een
architectuurraamwerk, waaruit de inrichting van de stelselfuncties
wordt afgeleid. De stelselfuncties bestaan uit afspraken over data,
data-aanbod en data-vraag, met waar nodig nadere afspraken over het toepassen
van standaarden en het gebruiken van stelselvoorzieningen.
Op hoofdlijnen beschrijving van data als begrip en de eisen die het stelsel aan het data-aanbod verbindt.
‘Data’ is afkomstig uit het Latijn en betekent zoveel als ‘gegevens’ of
‘feiten’. Het Latijnse enkelvoud is ‘datum’. De verwarring die hierbij kan
ontstaan met het welbekende tijdsbegrip is evident. We gebruiken daarom de term
‘data’ voor zowel het enkelvoud als voor het meervoud van ‘gegeven’. Uit de
context moet blijken of het om het meervoud gaat of om het enkelvoud.
Elke digitale weergave van handelingen, feiten of informatie en elke
compilatie van dergelijke handelingen, feiten of informatie, ook in de vorm van
geluidsopnames of visuele of audiovisuele opnames.
De datastrategie is gericht op het (beter) dienen van het publiek belang, door
het datapotentieel waar de overheid al over beschikt, breder in te zetten voor
maatschappelijke opgaven. Stelseldata (her)gebruiken voor verschillende doelen
in verschillende contexten is daarom een belangrijk doel. Om herbruikbaarheid te
bevorderen, stelt FDS eisen aan de data die in het stelsel worden opgenomen.
Deze eisen hebben invloed op de inhoud van de datadiensten waarmee het
data-aanbod in het stelsel voor de data-afnemers wordt ontsloten. De
belangrijkste eisen die FDS stelt aan stelseldata zijn:
In deze paragraaf gaat het om herbruikbaarheid in semantische zin. De
beschrijvingen van data en datadiensten moeten inzicht geven in de mogelijke
herbruikbaarheid van de betreffende data. Om verantwoord hergebruik van data in
een andere context te kunnen bepalen, is minimaal inzicht vereist in:
Betekenis, context en doel van de her te gebruiken data;
Condities voor (her)gebruik;
Context en doel van het nieuwe gebruik.
Zo moet bijvoorbeeld duidelijk zijn wat de betekenis is van de data en waarvoor
deze oorspronkelijk is ingezameld en gebruikt. Lees voor meer Metadata,
Metadata van aanbod en de Publicatie van
metadata.
Data zijn in betekenisvolle samenhang ontsluitbaar
Voor het betekenisvol combineren (of compileren) van data moet deze voorzien
zijn van uniek identificerende kenmerken, ook wel sleuteldata genoemd. Relaties
tussen data worden gelegd via deze sleuteldata. Met sector-overstijgend data
delen als uitgangspunt is het noodzakelijk dat data uit verschillende sectoren
is voorzien van overeenkomstige sleuteldata. FDS onderhoudt een afsprakenkader
dat beschrijft welke sleuteldata minimaal aanwezig moet zijn, om te kunnen
koppelen met andere data. Dit afsprakenkader is bekend onder de naam
‘Informatiekundige Kern’ (IK). De relaties tussen sectoren blijken vooral gelegd
te kunnen worden op basis van ‘wie’ en/of ‘waar’, ofwel de identificerend
kenmerken van natuurlijke personen, organisaties en locaties. Binnen sectoren
zijn de onderwerpen en objecten waar de sector over gaat belangrijke factoren
voor het leggen van relaties. Denk aan voertuigen in de mobiliteitssector,
studieprogramma’s in de onderwijssector, etc. De IK bestaat uit afspraken over
de identificatie van natuurlijke personen, niet-natuurlijke personen en
locaties. Dit betreft de identificerende eigenschappen van BRP, HR en BAG.
Doordat data-aanbieders in FDS conformeren aan de IK-afspraken kunnen ze
datadiensten aanbieden die op informatiekundig betrouwbare manier data
combineren. Als twee verschillende datasets dezelfde unieke sleutel gebruiken
(bijv. BSN 999.99.999 van een persoon), is het simpel vast te stellen dat het
gaat om data over dezelfde persoon. De bij deze sleutel behorende datakenmerken
uit beide datasets zijn dan eenvoudig te combineren tot een samengesteld beeld
over de betreffende persoon. Naast afspraken over standaard identificerende
sleutels voorziet FDS ook in afspraken over alternatieve sleutels. Stel dat een
data-aanbieder niet mag of kan beschikken over een BSN, maar de data die hij wil
aanbieden leent zich wel voor het leggen van relaties op persoonsniveau. In dat
geval kan wellicht een alternatieve sleutel worden toegepast. Denk aan postcode
en huisnummer voor een adres, of geboortedatum, voornamen en achternamen voor
een persoon. Bij gebruik van alternatieve sleutels kan altijd een risico bestaan
dat een sleutel niet 100% uniek is. Ook over het mitigeren van dit risico zijn
afspraken nodig, evenals over hoe te handelen bij eventuele maatschappelijke
gevolgen bij ongewenst koppeling van data. De IK zal ook nog afspraken uitwerken
over de invulling van ondersteunende functies. Dergelijke functies moeten de
implementatie van de afspraken eenvoudiger maken. Te denken valt aan:
Opzoeken van sleutels;
Wisselen van sleutels naar alternatieve sleutels. Denk aan het omwisselen van
identificatie op basis van KVK-nummer naar identificatie op basis van RSIN
voor een niet-natuurlijk persoon.
Gebruik van pseudoniemen bij persoonsgegevens.
7 - Stelselrollen
Op hoofdlijnen hoe de rollen m.b.t. het aanbieden en afnemen van data binnen het Federatief Datastelsel zijn ingericht.
Aanbod en vraag
FDS verbindt de vraag naar stelseldata met het aanbod ervan.
De vraag naar stelseldata heeft betrekking op data die is ingewonnen ten behoeve
van de uitvoering van een wettelijke taak. De inwinnende partij heeft in het
huidige stelsel van basisregistraties de rol van ‘bronhouder’. FDS heeft geen
invloed op de organisatorische en procesmatige inrichting van het inwinnen en
bijhouden van de data. In de beschrijving van het Data-ecosysteem van de
Nederlandse overheid positioneren we de bronhouder in de
domeinen waarbinnen de data wordt ingezameld en gebruikt (paragraaf
‘Datadomeinstelsel’).
FDS positioneren we als stelsel van
stelsels waarbinnen data
domeinoverstijgend wordt aangeboden. Vanuit die rol stelt FDS eisen aan de
data die onderdeel van het stelselaanbod zijn of worden.
De primaire rollen in FDS zijn de data-aanbieder en data-afnemer. Aan de
primaire rollen koppelt FDS rol-specifieke taken, verantwoordelijkheden en
bevoegdheden. De toekenning hiervan is afgestemd op de specifieke doelen van FDS
en is alleen van toepassing op handelingen binnen het FDS afsprakenkader. Een
organisatie kan als deelnemer in het stelsel, zowel aanbieder zijn als afnemer.
FDS eist dat het altijd volkomen duidelijk is vanuit welke rol een
stelseldeelnemer handelt.
Data-aanbieder
De data-aanbieder is een stelselrol die wordt ingevuld door een organisatie met
een wettelijke taak. De data-aanbieder is
deelnemer in het stelsel. Hij maakt de data die tot het stelsel is toegelaten,
beschikbaar en bruikbaar door er dataservices op te ontwikkelen en aan te
bieden, zodat data-afnemers ze kunnen gebruiken. Deze rol is vergelijkbaar met
de rol van ‘verstrekker’ in het huidige stelsel van basisregistraties.
De organisatie die de rol vervult kan tegelijkertijd ook de rol van bronhouder
hebben, maar het kan ook een andere organisatie zijn. Voor FDS geldt het
uitgangspunt dat de data-aanbieder verantwoordelijk is voor een bepaald
data-aanbod, ongeacht of hij wel of niet de bronhouder is. De data-aanbieder
staat garant voor het waarmaken van de opgegeven specificaties van de
datadiensten (en de daarin vrijkomende data) die hij aanbiedt.
De data-aanbieder biedt de data aan op grond van een wettelijke taak. Hiermee is
het verantwoord datadelen vanuit het publiek belang juridisch afdwingbaar.
Data-afnemer
De data-afnemer is een organisatie met een wettelijke taak, welke als deelnemer
is aangesloten op het stelsel. De data-afnemer creëert maatschappelijke waarde
door het toepassen van FDS- en niet-FDS-datadiensten voor het uitvoeren van zijn
publieke taak: het leveren van digitale diensten aan burgers, bedrijven en
overheden.
De data-afnemer moet kunnen aantonen dat hij de af te nemen gegevens binnen de
kaders van zijn wettelijke taak gebruikt.
8 - Stelselfuncties
De stelselfuncties van FDS
Voor een goede werking van het stelsel onderscheiden we een beperkte set aan
organisatorische en technische stelselfuncties. Deze functies zorgen ervoor dat
gebruikers het stelsel als een geheel ervaren en dat ze het data-aanbod in FDS
zo eenvoudig mogelijk kunnen gebruiken.
De stelselfuncties worden bij voorkeur decentraal ingevuld op basis van
afspraken, standaarden en/of voorzieningen, waarbij het uitgangspunt ‘Afspraken
boven standaarden boven voorzieningen’ van toepassing is.
Onderstaand diagram toont de verschillende stelselfuncties binnen FDS.
Beschrijving van wat FDS, het Federatief Datastelsel, inhoudt en betekent
Context
Het Federatief Datastelsel (FDS) is zowel de realisatie van het Toekomstbeeld Stelsel van
Basisregistraties als de realisatie van de Interbestuurlijke Datastrategie, waar het één van de
onderkende systeemfuncties is. De realisatie van beide beleidsvisies is belegd bij het programma
Realisatie Interbestuurlijke Datastrategie. Dit programma heeft de
beide visies samgengebracht onder het volgende gemeenschappelijke beleidsdoel: ‘Als overheid
benutten we het volle potentieel van data bij maatschappelijke opgaven, zowel binnen als tussen
domeinen, op een ambitieuze manier die vertrouwen wekt .” (Bron
Meerjarenaanpak Interbestuurlijke Datastrategie
). Voor het realiseren van dit doel zijn in de Meerjarenaanpak Interbestuurlijke Datastrategie op
globaal niveau een aantal functies onderkend (daar “systeemfuncties” genoemd). Eén van deze
systeemfuncties is het Federatief Datastelsel (afgekort “FDS”).
Algemene scope Federatief Datastelsel
Op de IBDS website is een informatiepagina over het FDS gemaakt. Op deze pagina staat algemene informatie over wat het FDS inhoudt en zijn de antwoorden op de meest gestelde vragen te vinden. Hieronder wordt aanvullende informatie op die pagina toegelicht:
Bij de realisatie van het Federatief Datastelsel (FDS) staan de volgende elementen uit het hiervoor
genoemde beleidsdoel centraal:
Overheid
Data
Zowel binnen als tussen domeinen
Vertrouwen
Dit maakt het FDS tot een publiek (= overheid) stelsel dat het datapotentieel van verschillende
sectorale datastelsels (= binnen en tussen domeinen) in overeenstemming met publieke waarden (=
vertrouwen) voor publieke doelen (= maatschappelijke opgaven) beschikbaar maakt. [Datastelsel] wordt
in dit verband als synoniem beschouwd voor de termen [data space] en [data ecosysteem].
Het FDS gaat uit van het ontsluiten en betekenisvol verbinden van decentrale databronnen zodat deze
volgens het principe van ‘data bij de bron’ op een verantwoorde manier voor
overheidsdienstverlening kunnen worden toegepast. Het principe heeft een sterke relatie met data
soevereiniteit. Door gebruikers, bijvoorbeeld via API’s, rechtstreeks toegang tot de data te geven
in plaats van ze als kopie uit te wisselen, houden de partijen die data via het stelsel aanbieden
zicht op deze data. Ze weten welke partijen toegang tot de data hebben en waarvoor ze deze willen
gebruiken. De op het stelsel aangesloten data-afnemende organisaties kunnen op hun beurt
rechtstreeks de aangeboden data consumeren en deze naar eigen behoefte met andere data combineren.
Dit uiteraard voor zover ze daartoe geautoriseerd zijn en dit ook
informatiekundig en ethisch verantwoord is.
Het FDS is dus een datastelsel dat datadeelrelaties van data-aanbieder rechtstreeks naar
data-afnemer faciliteert. Hiermee verschilt het FDS van datadeeloplossingen waarin data van
verschillende aanbieders fysiek, als kopie, wordt samengebracht in voorzieningen zoals [data
warehouses] en [data lakes] en waarbij een derde, intermediaire, partij tussen de [data-aanbieders]
en de [data-afnemers] is geplaatst.
Waarin verschilt het FDS van andere datastelsels
Een bijzonder kenmerk van het Federatief datastelsel is dat het andere datastelsels verbindt. Dit
maakt het mogelijk om data uit verschillende datadeelstelsels bij maatschappelijke opgaven te
gebruiken. Daarvoor vult FDS de generieke digitale infrastructuur van de overheid aan met
technische- en organisatorische stelselfuncties die het mogelijk maken om op een verantwoorde manier
het totale overheidsdatapotentieel beter te benutten. Om dit beheersbaar te houden geldt daarbij het
principe: decentraal wat kan, centraal wat moet. De functies van het FDS blijven beperkt tot wat
noodzakelijk is om effectief en efficiënt bovensectoraal data ‘vanuit de bron’ te delen, oftewel om
duurzaam technische, semantische en juridische interoperabiliteit tussen onder het FDS-regime
aangeboden datasets te realiseren. Het FDS biedt daarvoor meer dan interoperabiliteitsafspraken en –
standaarden. Het FDS-afsprakenkader bevat daarnaast afspraken over de minimaal te realiseren
inhoudelijke kwaliteit van (meta)data en datadiensten, net zoals bij het huidige stelsel van
basisregistraties. Deze inhoudelijke eisen leiden er toe dat niet alle overheidsdata geschikt is
voor opname in het FDS. Het FDS is bedoeld voor data die volgens het principe ’eenmalig inwinnen -
meervoudig gebruiken’ betrouwbaar een eigenschap (beschrijvend kenmerk) van iets of iemand
(identificerend kenmerk) vastlegt. Belangrijk zijn dus niet alleen de databronnen maar ook
betekenisvolle relaties tussen deze bronnen - de koppelingen. Ook hieraan stelt het FDS hoge
kwaliteitseisen.
Dit geheel zorgt ervoor dat afnemers goed kunnen bepalen of ze voor hun dienstverlening zonder nader
onderzoek op een FDS-compliant databron kunnen bouwen en wordt het zelfs mogelijk om dit gebruik
wettelijk te verplichten.
Naast het sectoraal/domeinoverstijgende aspect en de op meervoudig gebruik afgestemde hoge
datakwaliteitseisen, maakt het publieke karakter het FDS bijzonder. Bij het datadelen binnen de
FDS-context moeten de continuïteit van de publieke taakuitvoering en het in acht nemen van publieke
waarden zijn verzekerd. Daarvoor gelden specifieke normen zoals de algemene beginselen voor
behoorlijk bestuur. Het naleven daarvan moet niet alleen zijn geborgd, maar voor het maatschappelijk
vertrouwen in de werking van het FDS, moet dit ook kunnen worden aangetoond. Het FDS vereist daarom
niet alleen dat de toepassingsmogelijkheden en de kwaliteit van de data duidelijk zijn, maar ook dat
transparant kan worden gemaakt wat er in werkelijkheid is gebeurd: welke data, met wie, voor welk
doel, wanneer is gedeeld. Het kunnen borgen van de publieke waarden en het belang van de
continuïteit van de publieke dienstverlening, zal er bovendien toe leiden dat vanuit het FDS
specifieke aansluitvoorwaarden worden opgelegd die bepaalde datasets, al dan niet tijdelijk,
uitsluiten. Zo is er vooralsnog vanuit de Interbestuurlijke Datastrategie voor gekozen om alleen
organisaties, datasets en datadiensten tot het FDS toe te laten die verbonden zijn met een
wettelijke taak. Dit betekent dat het FDS geen zuiver private datasets1 ontsluit. Dit is
overigens geen verbod op delen. Partijen kunnen nog steeds via bilaterale of sectorale
arrangementen, los van het FDS-afsprakenkader, private data (blijven) delen of uitwisselen volgens
een eigen, sectoraal, afsprakenstelsel. Het FDS vervangt geen sectorale afsprakenstelsels, maar
levert het fundament dat het mogelijk maakt om eenvoudiger (want gestandaardiseerd) data met andere
sectoren te delen, zoals geïllustreerd in de hierna volgende figuur:
Bij het federatieve karakter van het FDS waarbij op basis van gelijkwaardigheid wordt gedeeld, hoort
ook dat er aan de aanbiedende kant eveneens specifieke eisen kunnen worden gesteld. Zo kunnen
aangesloten sectoren en organisaties er voor kiezen om een deel van hun aanbod niet via het FDS te
delen, bijvoorbeeld omdat deze data alleen binnen de sector of het eigen bedrijfsproces waarde
heeft, of omdat het zeer gevoelige data betreft die een hoger beveiligingsniveau nodig heeft dan het
FDS ondersteunt. De gekozen scope van het FDS vormt ook geen permanente, infrastructurele, barrière.
Via aanpassing van de aansluitvoorwaarden kan later alsnog de reikwijdte van het FDS worden
verruimd.
Wat gaat het FDS bieden
Het Federatief Datastelsel is nog in opbouw. Het project Realisatie Federatief Datastelsel (R-FDS)
ontwikkelt functies om data-aanbieders en data-afnemers uit verschillende domeinen op een
verantwoorde manier data te laten delen. Deze functies zijn ingebed in een afsprakenstelsel dat waar
nodig is aangevuld met standaarden en voorzieningen. Dit geheel maakt het mogelijk om
data-aanbieders, data-afnemers, datasets en datadiensten te certificeren (een ‘FDS label’) te geven
waarmee het duidelijk wordt dat deze aan het FDS-afsprakenkader (de FDS aansluitvoorwaarden )
voldoen. Dit is inclusief de afspraken over het toezicht op de naleving. Hiermee wordt een
vertrouwensbasis gecreëerd die het voor partij A in sector X mogelijk maakt om verantwoord data van
partij B in sector Z te gebruiken, zonder dat A daarvoor alle bijzonderheden van partij B en sector
Z hoeft te kennen. Het omgekeerde geldt ook. Voor beide volstaat dat ze deel uitmaken van het
overkoepelende FDS en ze er daarom op kunnen vertrouwen dat ze genoeg gemeenschappelijk hebben om
bilateraal data te gaan delen. Voor het eigenlijke delen kunnen ze hun eigen IT-voorzieningen
gebruiken, mits die de conform de daarvoor geldende afspraken de FDS-standaarden hebben
geïmplementeerd. Stelseldeelnemers kunnen daarbij gebruik maken van ondersteunende FDS-voorzieningen
zoals de FDS-stelselcatalogus, maar dit is niet verplicht. De verplichting beperkt zich tot het
naleven van de FDS-afspraken en het implementeren van de daaraan gekoppelde standaarden. Het FDS is
dus geen ICT-systeem of datapakhuis, maar het is ook geen volledig virtueel stelsel. Het is
opgebouwd uit op afspraken en standaarden gebaseerde organisatorische en technische
stelselfuncties die het volgende mogelijk maken:
Een overzicht van de inhoud van het FDS
Streven is dat alle elementen van het FDS (alle ‘assets’): datasets, dataset inhoud, datadiensten,
data-aanbieders, data-afnemers en de onderlinge relaties hiertussen in de vorm van metadata op een
gestandaardiseerde manier worden beschreven. Daarmee ontstaat er inzicht in de inhoud van het FDS en
kan dit overzichtelijk worden weergegeven. Deze in- en overzichtsfunctie wordt ook wel
‘catalogus’2 genoemd . De FDS-catalogus wordt opgebouwd uit de metadata die de stelselpartijen
zelf conform de stelselstandaarden hebben gepubliceerd. De metadata is dus op zichzelf ook weer een
FDS-dataset die als open data volgens de FDS-standaarden voor eenieder wordt ontsloten (open
metadata). Dit maakt de inhoud van het federatief stelsel transparant en biedt partijen de
mogelijkheid deze metadata naar eigen inzicht te gebruiken, bijvoorbeeld door ze te integreren in
een thematische catalogus gericht op een specifieke doelgroep. N.b. dat de metadata open is, wil
uiteraard niet zeggen dat dit ook geldt voor de data en datadiensten die m.b.v. die metadata worden
beschreven.
Het betekenisvol leggen van datadeelrelaties
Dit betreft de afspraak dat een tot het stelsel toegelaten databron in elk geval via één van dde
identificerende gegevens uit de kern van het stelsel benaderbaar is.
Deze kern bevat data voor de identificatie van natuurlijke personen, niet-natuurlijke personen en
locaties. Met behulp van deze data kunnen op een informatiekundige betrouwbare manier gegevens
kunnen worden gecombineerd (‘gekoppeld’) omdat door het toepassen van de tot de kern behorende
gestandaardiseerde id’s zoals het BSN, het KVK-nr en het BAG verblijfsobject-id, eenvoudig kan
worden vastgesteld dat het dezelfde burgers, bedrijven of locaties betreft waarvan kenmerken worden
gecombineerd. Onderdeel van deze afspraak is ook dat de betreffende datahouder de kwaliteit van de
gelegde koppelingen inzichtelijk maakt en een proces heeft ingericht om deze kwaliteit te bewaken.
Behalve met afspraken over het toepassen van gemeenschappelijke identificerende sleutels ondersteunt
het FDS het leggen van relaties met diensten die de noodzakelijke variëteit in het sleutelgebruik
makkelijker hanteerbaar maken. Dit betreft onder andere het beschikbaar maken van datadiensten voor
het wisselen van sleutels, zoals het omwisselen van identificatie op basis van BSN naar
identificatie op basis van familienaam, huidige voornaam en geboortedatum (en vice versa); diensten
die helpen om administratieve data aan coördinaat gebaseerde geo-data te relateren en eenduidige
afspraken over het omgaan met ‘restpopulaties’, zoals buitenlandse vastgoedeigenaren die niet in
BRP/RNI zijn opgenomen en situaties dat in de kern opgenomen sleutels niet kunnen worden toegepast
omdat de gebruikscontext teveel verschilt.
Het betrouwbaar identificeren van de stelseldeelnemers
Om de legitimiteit van datadeelrelaties te kunnen valideren, moeten de partijen in de relatie, de
data-aanbieder en de data-afnemer en de door hen gebruikte datadiensten, op een betrouwbare manier
geïdentificeerd kunnen worden. Binnen het FDS geldt de afspraak dat de identificatie beperkt blijft
tot het niveau van organisatie. Voor de implementatie wordt aangesloten op afspraken, standaarden en
voorzieningen die vanuit het GDI-domein Toegang beschikbaar worden gesteld. Deze worden zo nodig
aangevuld met afspraken die specifiek op datadelen vanuit de bron betrekking hebben.
Het autoriseren van datadeelrelaties
Dat een relatie informatiekundig betrouwbaar kan worden gelegd, betekent niet dat deze ook mag
worden gelegd. Binnen het FDS geldt de afspraak dat een data-aanbieder alleen data aan een
data-afnemer beschikbaar stelt als hij heeft vastgesteld dat deze daartoe gerechtigd is. Om dit
geautomatiseerd te kunnen vaststellen, moet de gestelde datavraag aan een aantal op FDS-niveau
vastgestelde voorwaarden voldoen. Deze, nog uit te werken, voorwaarden hebben zowel betrekking op de
vorm van de vraag (de technische standaard) als de inhoud (de inhoudelijke standaard). Deze
voorwaarden maken het mogelijk in samenhang met de hierna genoemde registratiefunctie (het ’loggen’)
achteraf te kunnen controleren of het gegevensdelen tussen de verschillende stelseldeelnemers
volgens de regels is verlopen en burgers inzicht te geven in wie waarvoor zijn gegevens binnen het
stelsel heeft gebruikt.
Het legitimeren van nieuwe datadeelrelaties
Voorwaarden voor datadeling zijn de uitkomst van een proces waarbij de belangen voor het wel en niet
delen zorgvuldig tegen elkaar zijn afgewogen. Deze afweging is tijdgebonden. Datadeling die eerst
noodzakelijk was, kan door nieuwe technische mogelijkheden overbodig worden als volstaan kan worden
met alleen een antwoord op een specifieke vraag (dataminimalisatie). Maar het is ook mogelijk dat
waar er eerst geen zwaarwegend belang voor datadeling was, dat er nu, al dan niet tijdelijk, wel is.
Het FDS voorziet in (organisatorische) functies om dit afwegingsproces te faciliteren en de
resultaten daarvan op een gestandaardiseerde manier in de ‘verwerkingenregisters’ van de
stelseldeelnemers vast te leggen. Deze stelselfunctie wordt de Poortwachter3 genoemd .
Het registreren (loggen) van datadeling
Dit betreft drie hoofdafspraken die bedoeld zijn om transparant te maken wat er werkelijk is gedeeld
en de legitimiteit daarvan te kunnen controleren:
De afspraak dat data-aanbieders op een gestandaardiseerde manier registreren (loggen) welke data,
wanneer, aan welke organisatie, op basis van welke geclaimde grondslag, op welke manier (via welke
dienst) beschikbaar is gesteld.
De afspraak dat data-afnemers eveneens op een gestandaardiseerde manier loggen welke data,
wanneer, van welke organisatie, op basis van welke grondslag, of welke manier (via welke dienst)
is afgenomen. Hierbij geldt voor data die niet als ‘open data’ is geclassificeerd binnen het FDS
de aanvullende afspraak dat afnemende organisaties ook op persoonsniveau inzichtelijk moeten
kunnen maken wie de betreffende informatie heeft gebruikt.
De afspraak dat bij een stelseldatabron die is opgebouwd uit data uit andere stelseldatabronnen er
in de logging ook de relatie naar die oorsprong kan worden gelegd zodat er een sluitende ‘audit
trail’ van het datagebruik kan worden opgebouwd: Het transparant maken van het datagebruik.
Het FDS voorziet in afspraken en standaarden die het mogelijk maken om de op de stelselmanier
gelogde datadelingen te aggregeren tot een virtuele dataset die op zich ook weer als een
stelseldatabron ontsloten kan worden voor monitoring ter ondersteuning van de stelselgovernance
(bijvoorbeeld in geval van doorbelasting), het stelseltoezicht, het stelselbeheer en de
stelselbeveiliging. Daarnaast maakt deze gestandaardiseerde wijze van logging het mogelijk om op
geaggregeerd en individueel niveau aan burgers, bedrijven en ‘de maatschappij’ het datagebruik
inzichtelijk te maken en het opbouwen en bijhouden van de door de AVG voorgeschreven
‘verwerkingenregisters’ deels te automatiseren.
Aansluitondersteuning, validatie en certificering
Data-aanbieders en data-afnemers sluiten aan op het FDS doordat ze zich aanmelden en daarbij zelf
verklaren dat ze zich conformeren aan het FDS-afsprakenkader en dat ze hierop ook kunnen worden
aangesproken. Bij de data-aanbieders geldt deze verklaring ook voor de kwaliteit van de binnen de
FDS aangeboden datasets en datadiensten. Het aangesloten zijn komt tot uiting in het verkrijgen van
een FDS-label. Dit label is onderdeel van de metadata en kent verschillende, nog uit te werken,
kwaliteitsklassen (rankings). Vertrekpunt is dat partijen zelf hun niveau van stelselconformiteit
beschrijven en verifiëren (self description en self assessment). Het stelsel biedt daarvoor kaders,
referentietoepassingen en validators. Het aansluiten zelf wordt ondersteund met testomgevingen,
testdata en testtools en met kennis (handleidingen, best practices, faq’s etc.) geleverd vanuit het
FDS Expertisecentrum .
Gebruikersondersteuning
Het FDS kent 3 nog in te vullen en in te richten functies om de stelseldeelnemers te ondersteunen:
De Marktmeester die ondersteunt bij het matchen van vraag en aanbod.
De Expertisefunctie, die kennis levert over de inhoud en het toepassen van de FDS-afspraken,
standaarden en voorzieningen.
De Helpdesk die ondersteuning biedt voor partijen die een ‘stelselprobleem’ hebben of die
gebruikers op weg helpt die niet zelfstandig de weg kunnen vinden naar de partij die voor de
betrokken data- en of datadienst verantwoordelijk is.
Besturing van het FDS
Er is een behoefte aan regie en hiervoor is in het ontwerp van het stelsel de functie van Regisseur
voorzien. Hoe deze functie in een federatief stelsel effectief kan worden ingevuld, moet nog worden
uitgezocht. Een belangrijk element daarbij wordt het scherp krijgen van de verhouding tussen
doorzettingsmacht op stelselniveau en de ministeriële verantwoordelijkheid voor de sectoren waaruit
via het FDS databronnen worden ontsloten. Onderdeel van de uitwerking van de stelselregie is ook het
zorgen voor een redelijk en praktisch hanteerbaar financieringsarrangement voor het gebruik, het
beheer en de doorontwikkeling van het FDS.
Beheer en exploitatie van het FDS
Het strategisch, tactisch en operationeel beheer van de componenten van het FDS zal goed geregeld
moeten worden, maar de exacte invulling moet nog worden uitgewerkt. Op strategisch en deels tactisch
niveau is het beheer van het stelsel onderdeel van de regisseurrol, maar op operationeel niveau zal
er ook beheer van de in projectfase ontwikkelde stelselfuncties nodig zijn.
Toezicht en handhaving
Het ontwerp van het FDS kent de functie Toezichthouder. Van deze functie staat vast dat hij nodig
is, maar ook hier geldt dat de invulling nog uitgewerkt moet worden. Een belangrijk uitzoekpunt is
of er behoefte is aan een daadkrachtige onafhankelijke FDS-toezichthouder: een toezichthouder die
het instrumentarium heeft om zelf een goed beeld van de naleving van afspraken te krijgen en in te
grijpen als dit niet naar behoren gebeurt. Dergelijk ’toezicht met tanden’ is mogelijk noodzakelijk
voor het borgen van de publieke waarden die het FDS moet dienen.
Het faciliteren van koppelingen tussen aangesloten stelsels /dataspaces
Het beeld bestaat dat het FDS functies moet gaan leveren om het leggen van deze koppelingen te
vereenvoudigen, maar welke dat zijn moet nog worden uitgewerkt. Aandachtspunten zijn onder andere
verschillende standaarden voor authenticatie en autorisatie binnen te koppelen datastelsels en het
gebruik van verschillende identificerende nummers. Daarnaast zijn er mogelijk functies nodig om de
kwaliteit en het gebruik van deze koppelingen te kunnen monitoren.
Conformiteit met algemene EU dataregelgeving
Deelnemers aan het FDS kunnen ervan uitgaan dat ze met het implementeren van de FDS-afspraken en
standaarden ook voldoen aan de algemene datadeeleisen die vanuit EU-regelgeving worden opgelegd. Ze
kunnen zich dus focussen op het uitwerken en implementeren van de EU-dataregelgeving die specifiek
voor hun sector/domein geldt. Deze zekerheid bieden is een doel bij de realisatie van het FDS, maar
het is nog niet duidelijk of dit een afzonderlijke stelselfunctie vergt of dat het een aspect is bij
de inrichting van de andere FDS-functies.
Het raamwerk welke de structuur vormt voor de Stelselfuncties en bouwblokken die deze realiseren.
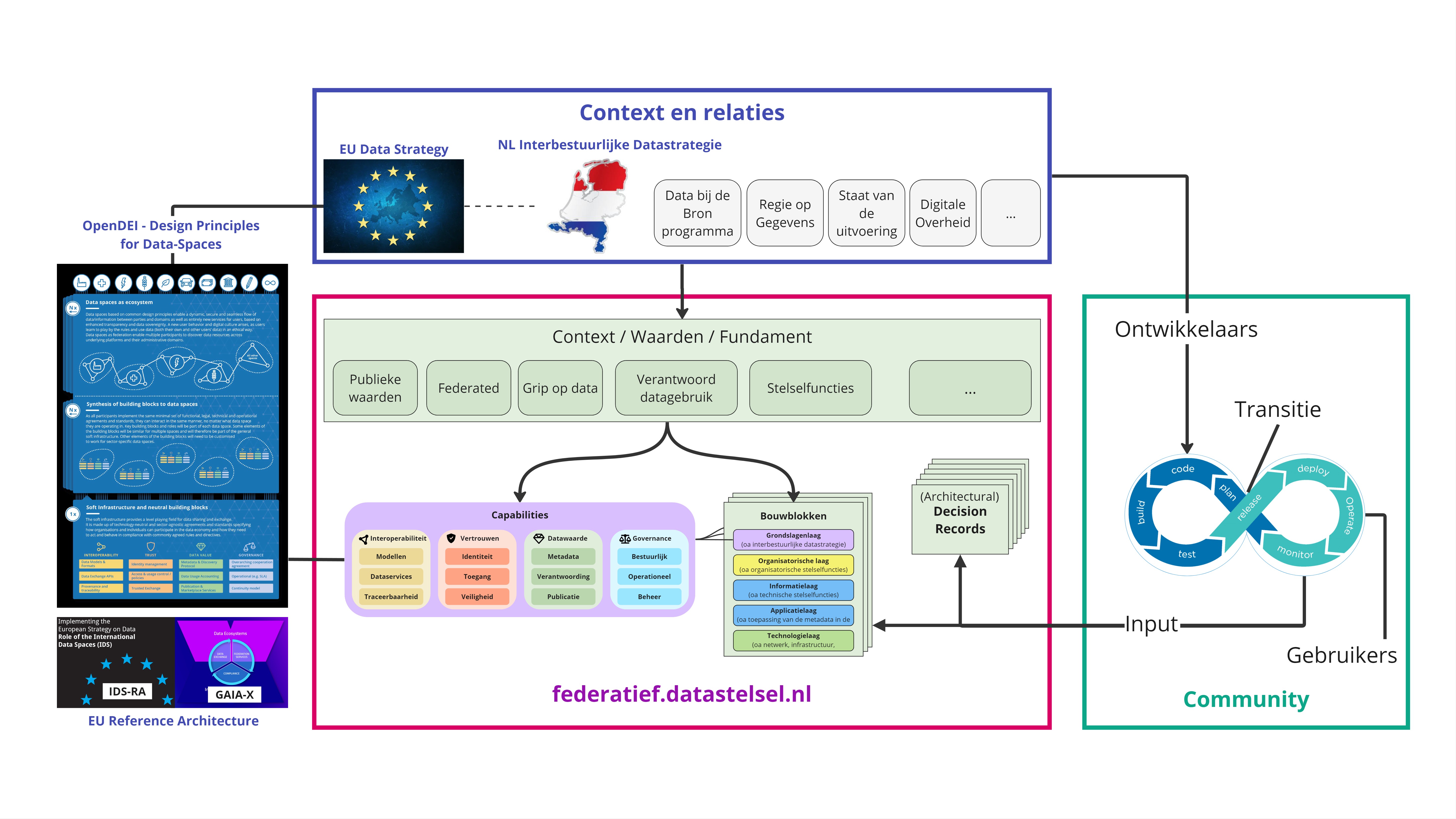
Ter ondersteuning van onze strategie van samenwerken
helpt het om een eenvoudig en begrijpelijk raamwerk (framework) als kapstok te gebruiken. Het
raamwerk ondersteunt vooral de ontwikkeling van het federatief datastelsel door gericht te zijn op
samenwerking en verbinding. Het biedt structuur aan wat we doen, waar we aan werken en biedt
mogelijkheden om verbindingen met onze omgeving te maken.
Een belangrijke verbinding die we willen maken, is naar Europa en Europese ontwikkelingen. Daarom
maken we gebruik van het Position Paper: Design Principles for Data
Spaces. Hierin heeft de OpenDEI Workforce een
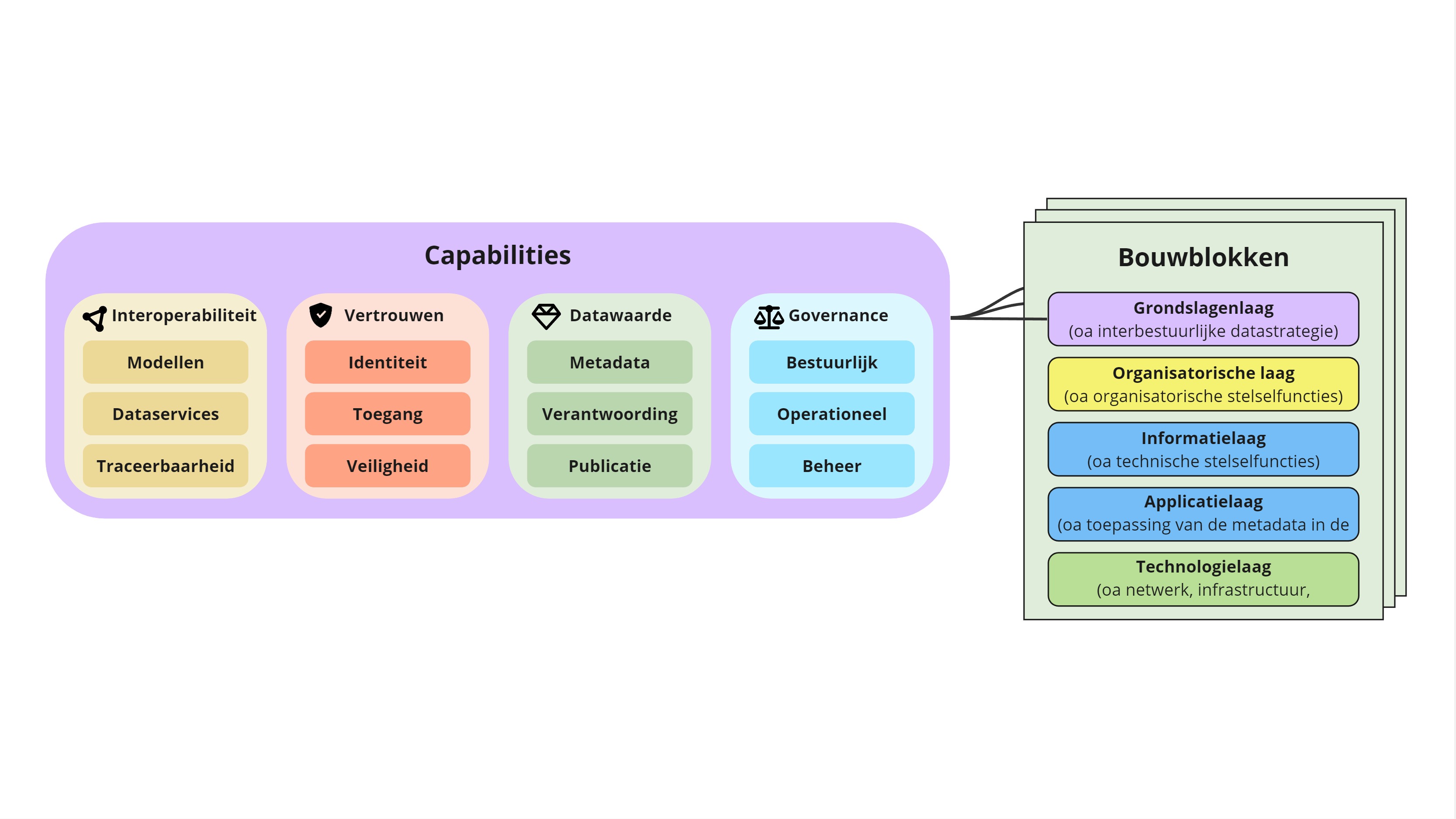
schema van ‘building blocks’ opgesteld dat door veel Europese initiatieven gebruikt wordt. Ook wij
willen deze gebruiken door deze ‘building blocks’ als ‘capabilities’ te zien die het federatief
datastelsel zou moeten ontwikkelen, hebben, zijn. Verdere overwegingen zijn te vinden in het besluit
00001 Basisstructuur. De uitwerking van de
Stelselfuncties is te vinden via het menu en/of in de documentatie.
Naast de verbinding naar Europa willen we ook graag verbinding kunnen maken naar andere
architecturen. Dat biedt ook structuur voor veel onderwerpen die ‘van verschillend niveau’ zijn.
Vrijwel alle architecturen onderkennen daarom verschillende lagen. Zo ook wij. In ons raamwerk
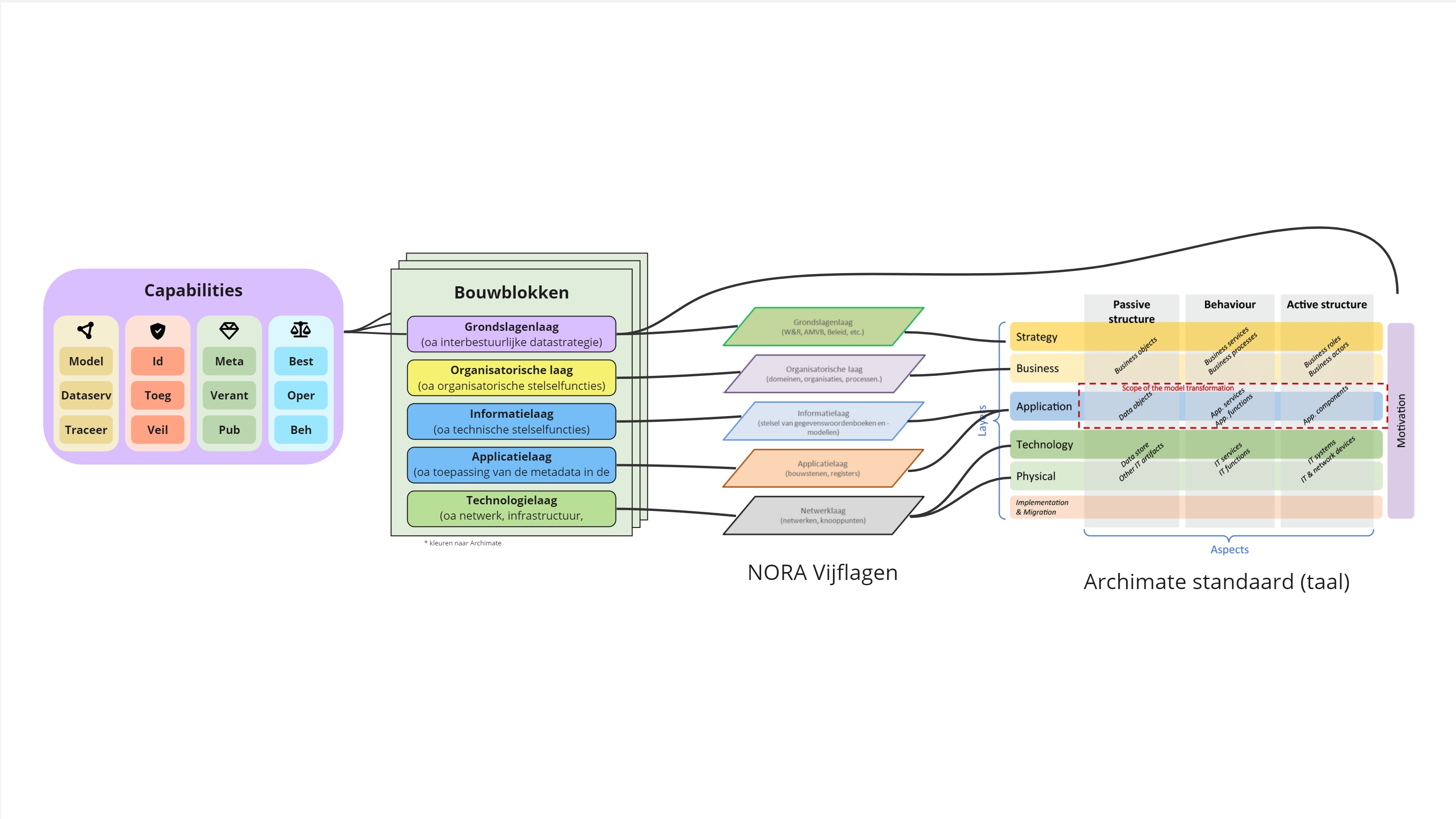
(basisstructuur) zien wij vijf lagen, waarbij de capabilities die hierboven genoemd worden zich
vooral in de bovenste laag bevinden. De vijflagen van ons raamwerk zijn te verbinden met
veelgebruikte lagenmodellen als NORA en Archimate.
De kern van het raamwerk is het capabilities model in combinatie met het vijf lagen model. Dit kan
beschouwd worden als de ’landkaart’ waarop alle activiteiten, aspecten, onderwerpen, technologieën
en ontwikkelingen te projecteren zijn. Je weet dan altijd waar het zich bevindt en hoe zich dat
verhoudt tot de rest.
Om de verbinding en relaties tot andere lagen modellen te maken, hebben we deze naar NORA en
Archimate al duidelijk ingetekend:
De kern van het raamwerk bevindt zich in een grotere context welke … behoorlijk omvangrijk en
indrukwekkend is:
De Europese datastrategie is gericht op het versterken van de positie van de Europese vrije markt
door effectief gebruik van data in stelsels met een gelijkwaardig speelveld voor alle deelnemers.
FDS is gericht op een datastelsel van en voor de Nederlandse overheid op basis van wettelijke
grondslagen. De scope van FDS stemt daarmee niet volledig overeen met de Europese insteek. De vier
principes verschillen dan ook in relevantie voor FDS.
Het eerste principe, datasoevereiniteit, stelt dat deelnemers volledige zeggenschap moeten
houden over ‘hun’ data. FDS is gericht op beter gebruik van overheidsdata ten behoeve van
maatschappelijke opgaven die in ieders belang zijn. Het maatschappelijk belang overstijgt het
individuele belang van een datahouder, maar wel onder de juiste condities. En die condities worden
bepaald op basis van de wettelijke kaders en de afspraken in het stelsel. Voor FDS is dit vertaald
naar het uitgangspunt ‘Grip op data’.
Het tweede principe gelijk speelveld, is gericht op o.a. het wegnemen van ongewenste
monopolistische macht over data. Dit principe past in zoverre bij FDS dat de data die de overheid
verzamelt op maatschappelijke gronden, in principe van ieder lid van die maatschappij is. Dat
betekent echter niet dat ieder lid van de maatschappij recht op toegang heeft tot die data. Het
speelveld van FDS-deelnemers is beperkt tot organisaties met een publieke taak, die de data mogen
verzamelen, delen en/of gebruiken op grond van Nederlandse wet- en regelgeving.
Het derde principe betreft de zachte infrastructuur van afspraken en standaarden. Dit
principe is volledig van toepassing op FDS en is ook opgenomen als een van de uitgangspunten.
Het vierde principe, publiek-private governance, is zeker van toepassing. Niet als het
gaat om de relaties tussen overheid en private organisaties. Maar wel als het gaat om de besturing
van specifieke domeindatastelsel en het verbindende stelsel van stelsels dat FDS beoogt te zijn.
Principes Nederlandse overheid
Aangezien het FDS een datastelsel van de Nederlands overheid is, is het logisch dat FDS de principes
van de Nederlandse overheid volgt. Die principes vinden we in de Nederlandse Overheid Referentie
Architectuur (NORA) en bij de doelarchitectuur van de Digitale Overheid (DO).
De NORA beschrijft vijf kernwaarden van
overheidsdienstverlening die door de NORA gebruikersraad zijn vastgesteld als uitgangspunt voor
kwaliteitsdoelen en architectuurprincipes.
De kwaliteitsdoelen beschrijven de gewenste kenmerken van de overheidsdienstverlening uit het
perspectief van de samenleving die van de diensten gebruik wil of moet maken.
De 17 NORA-architectuurprincipes geven richting aan het ontwerpen van de overheidsdiensten en de
bijpassende voorzieningen. Overheden werken samen in ketens en netwerken om tot optimale
dienstverlening te komen. Het delen van data is daarvoor essentieel. Domeindatastelsels en het
domein overstijgende FDS zijn daarbij een belangrijke schakel.
NORA biedt zo een kader voor de doelarchitectuur van de digitale
overheid
met een realisatiehorizon tot 2030. De doelarchitectuur is een concretisering van de NORA: enerzijds
door in meer detail aan te geven hoe de digitale overheid er in 2030 uit zal zien en anderzijds door
delen van de referentiearchitectuur te vertalen naar doelarchitectuur. Bij de uitwerking is ook
gebruik gemaakt van architecturen die zijn opgesteld voor overheidssectoren en voor thema’s en
programma’s binnen de digitale overheid, waaronder ook IBDS/FDS.
De doelarchitectuur DO wordt in verdere details uitgewerkt in de 4 domeinarchitecturen: Toegang,
Interactie, Gegevensuitwisseling en Infrastructuur. Voor FDS zijn met name de domeinen
Gegevensuitwisseling en Toegang heel relevant.
Evenals de doelarchitectuur DO en de domeinarchitecturen, volgt FDS de NORA-architectuurprincipes.
Niet alle principes zijn even relevant voor FDS, daarom richt FDS vooral op de principes van de
informatie laag. Principe NAP10 - Neem gegevens
als fundament - is een principe dat bij
uitstek relevant is voor FDS. Aan alle bij dit principe beschreven implicaties geeft FDS op
enigerlei wijze een invulling, van ‘bevorderen hergebruik’ tot ‘vaststellen kwaliteit van gegevens’.
Een van deze implicaties verwijst naar een andere belangrijke set van principes, namelijk de
toepassing van de FAIR dataprincipes. De domeinarchitectuur Gegevensuitwisseling benoemt dit zelfs
als eerste principe. De FAIR-principes zien we bij FDS dan ook als heel belangrijk.
FAIR
Deze principes zijn oorspronkelijk ontstaan n.a.v. de behoefte aan beter beheer en hergebruik van
data voor wetenschappelijk onderzoek. Ze zijn in 2016 officieel geïntroduceerd als artikel in een
uitgave van ‘Scientific data’. De FAIR principes zijn
gericht op het vindbaar, toegankelijk, interoperabel en herbruikbaar maken van data. Metadatering
speelt daarbij een voorname rol. Waar aanvankelijk bedoeld voor wetenschappelijke data, hebben de
principes al snel in brede kring erkenning gekregen. Vanuit het instituut
GoFAIR wordt gewerkt aan de ontwikkeling van een standaard
profiel van interpretatie en implementatie
van de FAIR-principes voor de Nederlandse overheid. De FAIR-principes zijn heel relevant voor FDS.
De FDS-deelnemers dienen deze principes te implementeren, maar het is aan FDS om dit te ondersteunen
met duidelijke afspraken en adequate standaarden op gebied van metadatering en publicatie daarvan.
12 - Begrippen
Veel gebruikte begrippen van FDS
Deze pagina toont de termen en omschrijvingen van de belangrijkste begrippen
voor FDS. Hiervoor maken we gebruik van begripsdefinities die zijn omschreven
door gremia die voor FDS kaderstellend zijn en/of kunnen fungeren als
belangrijke bron van inspiratie. Waar nodig passen we omschrijvingen aan naar de
context van FDS.
Interoperabel raamwerk, gebaseerd op gemeenschappelijke governance principes, standaarden, praktijken en ondersteunende diensten, dat betrouwbare en vertrouwde gegevenstransacties tussen deelnemers mogelijk maakt.
Een landelijk dekkende registratie met een wettelijke grondslag, waarin gegevens over individuele en identificeerbare objecten, subjecten en/of locaties worden vastgelegd.
Een document met erkende afspraken, specificaties of criteria over een product, een dienst of een methode, vastgesteld door een voor FDS erkende standaardisatie autoriteit.
Op deze pagina gaan we specifiek in op de afspraken die betrekking hebben op kwaliteit van de data.
1. Aanleiding
Het stelsel van basisregistraties wordt doorontwikkeld tot een Federatief Datastelsel. Dit is een
afsprakenstelsel waarin afspraken vastgelegd worden. In dit document gaan we specifiek in op de
afspraken die betrekking hebben op de kwaliteit van de data. Deze zijn gebaseerd op het geleerde
vanuit het stelsel van basisregistraties aangevuld met hetgeen hierover sindsdien in NORA-verband is
uitgewerkt.
Deze afspraken gaan over zowel de kwaliteit van de data, de metadata als de dataset en worden in de
afspraken benoemd als ‘data’ Uit de afspraak kan afgeleid worden of het om de volledige dataset of
een specifiek onderdeel van de dataset gaat.
Opgemerkt wordt dat de kwaliteit van de services, die zorgen dat de data gedeeld worden op een
verantwoorde wijze, buiten scope van dit document vallen. Deze wordt behandeld in een separaat
traject.
Deze afspraken zullen in de toekomst worden uitgebreid met onderwerpen die nog uitgewerkt moeten
worden, bijvoorbeeld het toezicht op de datakwaliteit binnen het stelsel.
Er worden in deze kwaliteitsafspraken geen afspraken gemaakt over collectieve normen op het stelsel
of verhogen van kwaliteit in het stelsel omdat deze vaak des sectors zijn.
2. Doel
Doel van dit document is tweeledig:
Vastleggen van de FDS-afspraken over datakwaliteit;
Duiding geven aan de veranderingen ten opzichte van de kwaliteitsvoorschriften in het stelsel van
basisregistraties.
Zodra deze nieuwe afspraken vastgesteld zijn, kan de Baseline kwaliteitszorg Stelsel van
Basisregistraties, waarin de afspraken momenteel vastgelegd zijn, vervallen.
3. Essentie
De kwaliteit van data gebruikt in (overheids)processen is bepalend voor de kwaliteit van de
dienstverlening.
De tijdgeest heeft het belang van datakwaliteit voor breder gebruik en dienstverlening een grote
impuls gegeven. Daar waar er bij de start van het stelsel van basisregistraties een aantal
(kwaliteits)processen en functies verplicht ingericht moesten worden, kan er in deze tijd meer
uitgegaan worden van een algemeen en breder belang van goede kwaliteit waar partijen, graag aan
bijdragen en ieder passend bij hun positie haar verantwoordelijkheid kent en neemt.
Het belangrijkste uitgangspunt in dit beleid is gebaseerd op het streven dat de datakwaliteit
geschikt moet zijn voor bovensectoraal gebruik (fit for purpose). Voor de juiste balans tussen vraag
naar kwaliteit door een data-afnemer en het bieden van kwaliteit door een data-aanbieder moeten een
tweetal functies worden ingericht:
Inzicht en transparantie over datakwaliteit Daarmee zijn de data-afnemers in staat een goede
inschatting te maken in hoeverre het aanbod geschikt is voor gebruiksbehoeften en doelen.
Behouden en verbeteren van datakwaliteit
Daarmee zijn de data-afnemers in staat het gebruik blijvend te baseren op het aanbod. Ook wordt
hiermee duidelijk op welke wijze gewenste verbeteringen van de datakwaliteit kenbaar gemaakt en
opgepakt worden.
4. Rollen, taken en verantwoordelijkheden
In het basisconcept FDS is een data-aanbod- en datavraagkant beschreven. Deze worden verbonden door
stelselmechanismen.
Voor datakwaliteit zijn de volgende rollen van belang, deze zijn niet allemaal benoemd in het
basisconcept:
Bronhouder: een partij of een samenwerkingsverband van partijen die verantwoordelijk is voor het
inwinnen, bijhouden en consolidateren van de data en de borging van de kwaliteit daarvan (deze
rol ligt buiten het basisconcept); gegevensuitwisseling verloopt tussen de data-aanbieder en
data-afnemer. Deze rol is vergelijkbaar met die uit het stelsel van basisregistraties.
Data-aanbieder: is verantwoordelijk voor het ontsluiten van aangeboden data middels dataservices
en het volgens de FDS-afspraken en -standaarden publiceren van de te verwachten en feitelijk
gerealiseerde datakwaliteit. Deze rol lijkt grotendeels op de rol verstrekker uit het stelsel van
basisregistraties.
Data-afnemer: is verantwoordelijk voor het juiste gebruik en het bij de data-aanbieder melden van
kwaliteitsissues (‘terugmelden’). Deze rol is vergelijkbaar met die van afnemer uit het stelsel
van basisregistraties.
Beleidsopdrachtgever voor de dataset: is verantwoordelijk voor de formele vaststelling van de
kwaliteitsspecificaties van de aangeboden data en de eisen voor monitoring en rapportage. Deze
rol zorgt ervoor dat daarbij de FDS-afspraken en eisen worden meegenomen. Deze rol is
vergelijkbaar met die uit het stelsel van basisregistraties.
Toezichthouder van de dataset: houdt toezicht op de kwaliteitseisen zoals benoemd in wet- en
regelgeving van deze dataset/sector.
Toezichthouder FDS: houdt toezicht op het Federatief Datastelsel als geheel. Deze rol wordt nog
uitgewerkt en zal zich met betrekking tot de kwaliteitsafspraken richten op nakoming van de
afspraken benoemd in dit document.
Toegelicht met een voorbeeld:
Dit betekent bijvoorbeeld voor het delen van data over civieltechnische kunstwerken in de waterketen
dat de rollen als volgt ingevuld worden:
Rol
Invulling
Bronhouders:
21 Waterschappen
Data-aanbieder:
Het Waterschapshuis
Data-afnemer:
Provincie Y
Beleidsopdrachtgever:
Ministerie I&W
Toezichthouder dataset:
Het Waterschapshuis
Organisaties kunnen zowel de rollen bronhouder als data-aanbieder hebben afhankelijk van de
inrichting van taken voor een bepaalde dataset. Daarnaast kan deze organisatie ook een data-afnemer
zijn.
De afspraken over kwaliteit zoals in dit document beschreven, worden vooralsnog jaarlijks
geëvalueerd met de werkgroep Datakwaliteit die advies uitbrengt aan het Tactisch Overleg. Op termijn
gaan deze afspraken over in de datafederatie overkoepelende organisatorische stelselrollen
‘toezichthouder’ en ‘regisseur’.
5. Afspraken datakwaliteit gewenste situatie
Voor het inzicht in de kwaliteit en de kwaliteitsborging van data in het FDS worden afspraken op het
niveau van het stelsel gemaakt. Deze zijn hierna per onderwerp beschreven.
5.1. Inzicht en transparantie datakwaliteit
Data-afnemers krijgen op een uniforme wijze inzicht in de datakwaliteit van het data-aanbod waarmee
ze in staat worden gesteld om invulling te geven aan het juiste gebruik. De data-aanbieder is
verantwoordelijk voor de publicatie.
Uniformering beschrijving
De datakwaliteit voor FDS wordt eenduidig beschreven zodat het voor
een data-afnemer duidelijk is om te bepalen wat dit voor zijn toepassing betekent, bijvoorbeeld als
data van verschillende aanbieders gecombineerd wordt of om eisen te stellen aan verbeterde
datakwaliteit. De standaard om dit op een uniforme wijze te doen is het toepassen van het
NORA-raamwerk Gegevenskwaliteit.
De afspraken die het Tactisch Overleg hierover op 2 juli 2024 geaccordeerd heeft zijn:
Data-aanbieders gebruiken in externe communicatie de terminologie uit het NORA-kwaliteitsraamwerk
voor zover relevant voor de dataset.
Data-aanbieders passen in externe communicatie zoveel als mogelijk de door de werkgroep
Datakwaliteit ontwikkelde zinsjablonen toe, voor zover relevant en toepasbaar op de dataset.
Als minimumeis gaat het om de kwaliteitsdimensies Compleet, Juistheid en Actualiteit. Daarnaast
worden waar relevant en mogelijk de andere (voorgeschreven) dimensies en/of attributen binnen de
dimensies beschreven. Hierbij wordt in inzicht gegeven in zowel de gerealiseerde kwaliteit als de
streefnorm.
Voorbeelden van enkele basisregistraties zijn te vinden op de website van
NORA. De tabel met
dimensies, attributenen sjabloonzinnen zijn vindbaar op deze
pagina
Transparantie datakwaliteit, rapportage
De rapportagefrequentie waarbij inzicht wordt gegeven in
de kwaliteit is afhankelijk van de dataset, het soort gegeven en eerdere kwaliteit.
Over identificerende gegevens in het stelsel met betrekking tot personen, organisaties en locaties
wordt jaarlijks gerapporteerd. Dit sluit aan op de frequentie zoals deze in het Stelsel van
basisregistraties in gebruik is.
Voor gegevens met een koppeling met identificerende gegevens over personen, organisaties en
locaties wordt de kwaliteit jaarlijks gerapporteerd. Wanneer de gerealiseerde kwaliteit structureel
meerdere jaren zeer hoog is mag volstaan worden met elke 3 jaar. Jaarlijks rapporteren sluit aan op
de huidige praktijk, het minder frequent rapporteren is nieuw ten opzichte van het stelsel van
basisregistraties en is enkel bedoeld als verlichting van de werkzaamheden.
Voor gegevens zonder koppeling naar identificerende gegevens over personen, organisaties en
locaties worden vanuit FDS geen verplichtende afspraken gemaakt. Dat ligt binnen de scope van de
sector, waarbij het aan de data-aanbieder en data-afnemer te bepalen is wat gepast en wenselijk is.
Datasets die nieuw deelnemen in het federatief datastelsel geven bij toetreding inzicht in de
datakwaliteit van de dataset met nadruk op de koppeling met identificerende gegevens van personen,
organisaties en locaties.
Jaarlijks worden de resultaten stelselbreed gebundeld en gepubliceerd. Het ministerie van BZK heeft
hierin een coördinerende rol.
5.2. Behouden en verbeteren datakwaliteit
Met de hiervoor opgenomen afspraken over uniformering van de beschrijving wordt op uniforme wijze
inzicht gegeven in de normen, beschrijvingen en behaalde resultaten. Deze kwaliteit moet behouden
blijven en waar mogelijk verbeterd worden. Hiervoor zijn de hierna volgende afspraken gemaakt
waardoor afnemers kunnen vertrouwen op de kwaliteit en bekend zijn met de wijze waarop gewenste
verbeteringen en de afwegingen daarvoor gemaakt worden.
Bepalen norm kwaliteitscriteria
Data-afnemers doen voorstellen voor (aanpassing van) de beoogde
kwaliteitscriteria van de dataset. De beleidsopdrachtgever stelt in overleg met de andere betrokken
rollen (bronhouder(s) en data-aanbieder) de normen vast en ‘organiseert’ de haalbaarheid van de
nakoming.
Dit kan bijvoorbeeld door een gebruiksoverleg te voeren. Andere manieren van afstemming zijn
mogelijk.
Monitoring op de kwaliteitsborging d.m.v. periodieke controles en gebaseerd op proportionaliteit
Met betrekking tot datakwaliteit is de bronhouder de partij die verantwoordelijk is voor de
kwaliteit van de data. Zij bewaakt en monitort deze, waarbij ze gebruik kan maken van door de
data-aanbieder beschikbaar gestelde signalen, analyses en rapportages.
Dit kan bijvoorbeeld door op basis van patronen in terugmeldingen of geconstateerde omissies de
volledige dataset hierop te bevragen of door (gerichte) bestandscontroles of kwaliteitsmetingen,al dan niet met een ketenpartner. Uitgangspunt hierbij is een sterker collectief stelsel. Daarnaast
kunnen audits als instrument ingezet worden (geen verplichting).
Verbeteren van datakwaliteit middels terugmelden gerede twijfel over de juistheid van een gegeven in de dataset
Afnemers en gebruikers kunnen bij toepassing van de data vermoeden en/of concluderen
dat data in de datasets niet juist zijn en geven hierover een signaal aan de data-aanbieder om de
kwaliteit van de datasets hoog te houden. Dit doen zij middels een terugmelding gerede twijfel over
de juistheid van een gegeven (hierna terugmelding). Ook burgers en ondernemers kunnen een melding
doen dat hun gegevens niet juist zijn.
De afspraken over terugmelden zijn:
Data-aanbieders bieden de (technische) mogelijkheid aan data-afnemers en data-gebruikers om
terugmeldingen te kunnen doen. Hoe zij dit doen mogen de data-aanbieders zelf bepalen.
Data-afnemers doen een terugmelding bij gerede twijfel over de juistheid van een gegeven; het is
afhankelijk van de geldende wet- en regelgeving of dit verplicht is voor deze dataset.
Een terugmelding wordt gedaan bij de data-aanbieder die de data heeft geleverd. Deze levert de
melding door aan de bronhouder.
De bronhouder maakt voor afnemers inzichtelijk dat er een terugmelding is gedaan; het is
afhankelijk van afspraken in de governance danwel wet- en regelgeving op welke wijze daar
invulling aan gegeven wordt.
Bronhouders borgen dat de terugmeldingen binnen redelijke termijn afgehandeld worden.
De data-aanbieder rapporteert in afstemming met de bronhouder(s) het aantal signaleringen en de
afhandeltermijnen.
De data-aanbieder en bronhouder maken afspraken welke partij de terugmeldingen op oorzaken en
patronen analyseert, zodat het mogelijk is procesafspraken ter verbetering van minder goed lopende
processen op te kunnen stellen en daarmee de kwaliteit van het stelsel te behouden en verbeteren.
Burgers en ondernemers die fouten constateren in hun eigen gegevens geven dit door op de wijze die
door de data-aanbieder is aangegeven. Dit betreft het uitvoering geven aan het correctierecht dat
in de AVG is opgenomen.
Bijlage 1
Samenvatting afspraken en standaarden datakwaliteit
Doel: Inzicht en transparantie over datakwaliteit
Daarmee zijn de data-afnemers in staat een
goede inschatting te maken in hoeverre het aanbod geschikt is voor gebruiksbehoeften en doelen.
Subdoel: Uniformering beschrijving
Afspraken:
Data-aanbieders beschrijven in externe communicatie de terminologie uit het NORA-
kwaliteitsraamwerk voor
zover relevant voor de dataset.
Data-aanbieders passen in externe communicatie zoveel als mogelijk de door de werkgroep
Datakwaliteit ontwikkelde
zinsjablonen
toe, voor zover relevant en toepasbaar op de data- set.
Dit geldt minimaal voor de kwaliteitsdimensies Compleet, Juistheid en Actualiteit. Waar relevant
en mogelijk worden ook de andere (voorgeschreven) dimensies en/of attributen binnen de dimensies
beschreven.
Er wordt voor zover mogelijk en relevant inzicht gegeven in zowel de gerealiseerde kwaliteit als
de streefnorm.
Subdoel: Transparantie datakwaliteit, rapportage
De rapportagefrequentie waarbij inzicht wordt
gegeven in de kwaliteit is afhankelijk van de dataset, het soort gegeven en eerdere kwaliteit.
Afspraken:
Over identificerende gegevens in het stelsel met betrekking tot personen, organisaties en locaties
wordt jaarlijks gerapporteerd. Dit sluit aan op de frequentie zoals deze in het Stelsel van
basisregistraties in gebruik is.
Voor gegevens met een koppeling met identificerende gegevens over personen, organisaties en
locaties wordt de kwaliteit jaarlijks gerapporteerd. Wanneer de gerealiseerde kwaliteit
structureel meerdere jaren zeer hoog is mag volstaan worden met elke 3 jaar. Jaarlijks rapporteren
sluit aan op de huidige praktijk, het minder frequent rapporteren is nieuw ten opzichte van het
stelsel van basisregistraties en is enkel bedoeld als verlichting van mogelijk administratieve
lasten.
Voor gegevens zonder koppeling naar identificerende gegevens over personen, organisaties en
locaties worden vanuit FDS geen verplichtende afspraken gemaakt. Dat ligt binnen de scope van de
sector, waarbij het aan de data-aanbieder en data-afnemer te bepalen is wat gepast en wenselijk
is.
Datasets die nieuw deelnemen in het federatief datastelsel geven bij toetreding inzicht in de
datakwaliteit van de dataset met nadruk op de koppeling met identificerende gegevens van personen,
organisaties en locaties.
Jaarlijks worden de resultaten stelselbreed gebundeld en openbaar gepubliceerd. Het ministerie van
BZK heeft hierin een coördinerende rol.
Doel: Behouden en verbeteren van datakwaliteit
Daarmee zijn de data-afnemers in staat het
gebruik blijvend te baseren op het aanbod. Ook wordt hiermee duidelijk op welke wijze gewenste
verbeteringen van de datakwaliteit kenbaar gemaakt en opgepakt worden.
Subdoel: Bepalen norm kwaliteitscriteria
Afspraken:
Data-afnemers doen voorstellen voor (aanpassing van) de beoogde kwaliteitscriteria van de dataset.
De beleidsopdrachtgever stelt in overleg met de andere betrokken rollen (bronhouder(s) en
data-aanbieder) de normen vast en ‘organiseert’ de haalbaarheid van de nakoming.
Subdoel: Monitoring op de kwaliteitsborging d.m.v. periodieke controles en gebaseerd op proportionaliteit
Afspraken: De bronhouder bewaakt en monitort de datakwaliteit, waarbij ze gebruik
kan maken van door de data-aanbieder beschikbaar gestelde signalen, analyses en rapportages.
Subdoel: Verbeteren van datakwaliteit middels terugmelden gerede twijfel over de juistheid van een gegeven in de dataset
Afspraken:
Data-aanbieders bieden de (technische) mogelijkheid aan data-afnemers en data-gebruikers om
terugmeldingen te kunnen doen. Hoe zij dit doen mogen de data-aanbieders zelf bepalen.
Data-afnemers doen een terugmelding bij gerede twijfel over de juistheid van een gegeven; het is
afhankelijk van de geldende wet- en regelgeving of dit verplicht is voor deze dataset.
Een terugmelding wordt gedaan bij de data-aanbieder die de data heeft geleverd. Deze levert de
melding door aan de bronhouder.
De bronhouder maakt voor afnemers inzichtelijk dat er een terugmelding is gedaan; het is
afhankelijk van afspraken in de governance danwel wet- en regelgeving op welke wijze daar
invulling aan gegeven wordt.
Bronhouders borgen dat de terugmeldingen binnen redelijke termijn afgehandeld worden.
De data-aanbieder rapporteert in afstemming met de bronhouder(s) het aantal signaleringen en de
afhandeltermijnen.
De data-aanbieder en bronhouder maken afspraken welke partij de terugmeldingen op oorzaken en
patronen analyseert, zodat het mogelijk is procesafspraken ter verbetering van minder goed lopende
processen op te kunnen stellen en daarmee de kwaliteit van het stelsel te behouden en verbeteren.
Burgers en ondernemers die fouten constateren in hun eigen gegevens geven dit door op de wijze die
door de data-aanbieder is aangegeven. Dit betreft het uitvoering geven aan het correctierecht dat
in de AVG is opgenomen.
Bijlage 2
Beleid huidige situatie (achtergrond)
Zoals aangegeven vervalt de baseline kwaliteitszorg Stelsel van Basisregistraties na het vaststellen
van de nieuwe afspraken. Deze zijn hier enkel vermeld om verschillen te duiden.
Baseline kwaliteitszorg Stelsel van Basisregistraties
In de baseline kwaliteitszorg Stelsel van
Basisregistraties
zijn de afspraken binnen het stelsel gebundeld. Deze baseline is enkele jaren geleden opgesteld met
als doel een handzaam overzicht van de afspraken, spelregels en instrumentarium die gehanteerd
worden te bieden. Daarnaast is deze baseline bedoeld om als groeidocument te fungeren als er nieuwe
afspraken gemaakt worden.
De baseline is onder andere gebaseerd op de voor kwaliteit relevante eisen uit de 12 eisen van de
basisregistraties:
eis 2 De afnemers hebben een terugmeldplicht
eis 9 Er is een stringent regime van kwaliteitsborging
Rol- en taakverdeling
In de stelselarchitectuur van het heden wordt gesproken over rol- en taakverdeling. Ten aanzien van
de kwaliteit is hierin afgesproken dat de bronhouder de kwaliteit van de gegevens borgt en daartoe
op eigen initiatief onderzoek doet of naar aanleiding van terugmeldingen van afnemers. Daarnaast is
de rolomschrijving van de toezichthouder als volgt gedefinieerd: “De toezichthouder is er
verantwoordelijk voor dat wordt toegezien of de basisregistraties conform eisen, afspraken en
wetgeving opereert”.
Daarnaast is over toezicht ook het volgende in de stelselarchitectuur opgenomen: Over het algemeen
is de registratiehouder verantwoordelijk voor het toezicht op de naleving van de bepalingen die in
de wet voor de basisregistratie zijn opgenomen. Een deel van deze verantwoordelijkheid kan ook bij
de bronhouders en/of verstrekker belegd zijn of bij een externe partij zoals een ministerie.
In de praktijk is de monitoring en het toezicht hierop meestal sectoraal ingericht vanuit de
bronhouder en/of het verantwoordelijke ministerie.
Kwaliteitstoetsing
Er wordt op verschillende manieren invulling gegeven aan de kwaliteitstoetsing. Dit vindt minimaal
intern plaats, bijvoorbeeld door een ENSIA-zelfevaluatie. In de stelselarchitectuur wordt de interne
kwaliteitstoetsing als volgt omschreven: “Om het vertrouwen van afnemers te verkrijgen en behouden,
is het noodzakelijk dat er ten aanzien van de authentieke registratie een expliciete, interne
regeling voor kwaliteitstoetsing bestaat. Deze interne regeling dient uiteraard ook regelmatig te
worden toegepast.”
Ten aanzien van externe kwaliteitstoetsing is in de architectuur het volgende opgenomen: “(…) neemt
niet weg dat wenselijk is regelmatig externe toetsing van de kwaliteit van de authentieke
registratie te laten plaatsvinden. Een dergelijke externe toetsing zal meestal plaatsvinden in de
vorm van een audit. Verantwoordelijk voor het laten uitvoeren van een audit is in principe de houder
van een registratie. Daarnaast kan bij de inrichting van de gebruikersorganisatie ten aanzien van
het beheer, ook aan de beheersorganisatie het recht worden verleend om (al dan niet op regelmatige
basis) audits op kwaliteit van de authentieke registratie te laten uitvoeren.” De term audit wordt
hierin breed gebruikt en wordt in een aantal registraties als daadwerkelijke audit uitgevoerd. Bij
andere registraties wordt hieraan invulling gegeven door een meting door een externe partij te laten
uitvoeren, bijvoorbeeld het CBS.
Kwaliteit per registratie
Binnen het Stelsel van Basisregistraties is per registratie beschreven wat de kwaliteitsnormen zijn.
Deze zijn met de gebruikers van de registratie bepaald. Ten aanzien van eis 9 (streng regime van
kwaliteitsborging) is in de architectuur het volgende opgenomen: Kwaliteitsborging dient transparant
te zijn over de volgende zaken: - wat de gerealiseerde kwaliteit is van een basisregistratie,
uitgedrukt met behulp van duidelijke indicatoren en afgezet tegen vastgestelde normen; - hoe de
basisregistratie de gerealiseerde kwaliteit heeft bepaald; - welke maatregelen een basisregistratie
treft om de kwaliteit te garanderen en verbeteren.
De beschrijving van kwaliteit blijkt tussen registraties maar beperkt vergelijkbaar en ook de normen
kunnen verschillen. Er zijn behoudens een enkele registratie geen normen voor koppelingen tussen de
registraties.
Verder zien we verschillen in de wijze waarop er per registratie met kwaliteit wordt omgegaan. Zo
zien we in een aantal registraties dat er centraal signaleringen gedaan worden om bronhouders te
attenderen op potentiële fouten. In sommige registraties wordt ook aandacht gegeven aan controle van
de feitelijke werkelijkheid (ten opzichte van de geregistreerde gegevens). Verder blijkt dat hoe
gemakkelijker de registratie het gebruikers maakt om potentiële fouten terug te melden, dit ook in
grotere mate gedaan wordt.
Kwaliteit in beeld
Jaarlijks worden er kwaliteitsmetingen gedaan door de registraties op de eigen normen. Deze worden
gecombineerd
gepubliceerd.
Daarnaast wordt in opdracht van het ministerie van BZK, de kwaliteit van de koppelingen tussen
registraties jaarlijks gemeten door het CBS. Ook hier wordt over
gerapporteerd. Indien nodig
worden verbeteringen voorgesteld.
14 - Ik ben FDS data-aanbieder
Als jij als data-aanbieder wilt deelnemen aan FDS doorloop je het stappenplan deelnemen FDS. Als je als deelnemer bent toegetreden, ga je je data publiceren. Welke data op welke plaatsen wordt gepubliceerd, lees je hierna.
In welk formaat kunt u uw informatiemodellen aanleveren?
Informatiemodellen worden volgens semantische standaarden gepubliceerd, dus als linked data. Zie ook
Metadata.
Het heeft de voorkeur dat de aanbieder de metadata publiceert volgens deze standaarden. U kunt uw metadata ook aan ons aanleveren in Excel en dan transformeren wij dat naar linked data.
Hoe wordt uw data gepubliceerd?
Vraag: En als ze het zelf doen?
Samen met experts van Stelselcatalogus vult u uw informatiemodel in. Dit model wordt omgezet in
linked data en gepubliceerd op de stelselcatalogus.nl.
Om je data aan te bieden heb je een beschrijving nodig van jouw informatiemodel. In overleg met de
experts van Stelselcatalogus nemen we het informatiemodel op in een standaard Excel. We helpen je
graag met het beschrijven van jouw informatiemodel. Neem hiervoor contact op met de voorziening (zie
contactgegevens)
Begrippenkaders
Voor wie is deze voorziening?
Deze voorziening is voor elke organisatie die een begrippenkader wil aanmaken of aanbieden.
In welk formaat kan je jouw begrippenkaders maken?
Begrippenkader worden opgesteld conform de Standaard voor beschrijving van Begrippen: de
NL-SBB
Hoe worden begrippenkaders aangemaakt?
Begrippenkaders worden aangemaakt met behulp van een online editor of kunnen als Linked Data worden
aangeboden. Hiervoor heb je een account nodig. Je kan een account aanvragen door te mailen naar
logiuscontactstelselcatalogus@logius.nl. Als je al beschikt over een SBB begrippenkader in Linked
Data kan je dat direct aanbieden. Als je nog geen NL-SBB begrippenkader hebt kun je dat opstellen
met behulp van onze online editor. Door middel van het invullen van velden in een webapplicatie kan
jij een begrippenkader aanmaken conform de NL-SBB standaard en wordt jouw kader automatisch
gegenereerd. Begrippenkaders worden na jouw goedkeuring gepubliceerd bij Logius. Begrippenkaders kan
je natuurlijk ook intern gebruiken.
Afhankelijk van de grootte van jouw datasets en jouw organisatie is enige mate van technische kennis
nodig. Indien nodig helpen wij je graag met het aanbieden van jouw data. Ga hiervoor naar
data.overheid.nl/datasets
De stelselfunctie kwaliteit ondersteunt het definiëren en verbeteren van de
kwaliteit van aangeboden gegevens en dataservices.
….deze stelselfunctie wordt nog nader uitgewerkt….
16 - Federatieve Toegangsverlening
Het project Federatieve Toegangsverlening (FTV) werkt aan een standaard voor toegangsverlening in het FDS.
Wat is toegangsverlening?
Toegangsverlening gaat over het controleren of verwerkingen toegestaan zijn, en onder welke
voorwaarden. Denk hierbij aan een gemeentemedewerker die met een zaaksysteem persoonsgegevens
opvraagt uit de Basisregistratie Personen (BRP) en daarin een aanpassing maakt. Dat mogen alleen
medewerkers van burgerzaken, met een geldige bevoegdheid, alleen vanaf een gemeentewerkplek, en
alleen van burgers die gevestigd zijn in de eigen gemeente.
Toegangsverlening, ook wel autorisatie, volgt op de processen van identificatie en authenticatie. In
deze processen worden zekerheden bepaald rondom ‘wie ben jij’. Toegangsverlening maakt hier gebruik
van en bouwt daarop verder om te bepalen ‘wat mag jij’.
Waarom dit project?
Toegangsverlening bestaat natuurlijk al: er wordt nu ook gecontroleerd voordat gegevens verwerkt
worden. Wat dit project beoogt is:
Een standaard werkwijze, de FTV-standaard (werktitel), beschrijven. Er is nu geen standaard,
waardoor elk systeem zijn eigen methode kan bedenken of kiezen, hetgeen extra werk oplevert en het
lastiger maakt om bij elkaar aan te sluiten.
Toegangsregels expliciet maken. Waar deze nu veelal verborgen zijn in software worden deze in FTV
op een standaardwijze buiten de software gebracht. De regels kunnen daardoor makkelijker
geschreven, beheerd en gecontroleerd worden.
Fijnmaziger toegang mogelijk maken. Door naast statische informatie zoals groepen en rechten ook
dynamische informatie zoals apparaat en tijdstip mee te nemen kunnen preciezere regels
geformuleerd worden.
Scope en context
In het kader van het FDS richt FTV zich specifiek op machine-naar-machinecommunicatie, en minder op
mens-naar-machine.
FTV hangt nauw samen met twee andere standaarden: Federatieve Service Connectiviteit
(FSC) beschrijft hoe verbindingen tot stand komen en beveiligd worden,
en Logboek Dataverwerkingen (LDV) waarmee de
toegestane verwerkingen vastgelegd worden als juridische verantwoording.
FTV zal een uitwerking zijn van bredere begrippen als externalized access management en Policy Based
Access Control (PBAC). Andere projecten die hieraan vooraf gingen zijn het position paper
Policy Based Access Control en Lock-Unlock
Status
Het vooronderzoek is afgerond en er wordt nu geschreven aan de FTV-standaard. In deze fase is er
behoefte aan betrokkenheid van projecten en programma’s die voor uitdagingen staan rondom toegang.
Dat kan zijn in de vorm van ervaring delen, meeschrijven en pilot projecten die de standaard willen
beproeven.
Hier lees je meer informatie over het project Logboek Dataverwerkingen (LDV)
De standaard Logboek Dataverwerkingen
biedt een basis om te zorgen dat de overheid precies de data logt die zij nodig heeft om
verantwoording af te leggen over haar taken. Niet meer, maar ook niet minder. En om te zorgen dat
organisaties data zodanig loggen dat zij zich niet alleen over een eigen handelen kunnen
verantwoorden, maar ook over hun gezamenlijk handelen als “de overheid”. Het project Logboek
Dataverwerkingen is onderdeel van het ministerie van BZK. De
Vereniging van Nederlandse Gemeenten (VNG) en Geonovum werken hieraan mee.
Waarom een standaard voor logging van gegevensverwerking?
De overheid wil voor burgers en bedrijven zo transparant mogelijk zijn in de omgang met hun
gegevens. Daarom is het bij de informatieverwerking in datasets belangrijk om voor elke mutatie of
raadpleging vast te leggen wie deze actie wanneer uitvoert, en waarom. Deze herleidbaarheid speelt
zowel een rol in het kader van de wetgeving op het gebied van privacy als ook het streven naar
openheid en transparantie bij de overheid. Voor een optimale samenwerking over organisaties en
bronnen heen is voor deze logging een algemene standaard nodig: de standaard
Logboek Dataverwerkingen.
De juridische basis
Het juridisch beleidskader
biedt het overzicht van de (juridische) verantwoording die de overheid over haar handelen moet
afleggen en is opgesteld ten behoeve van de standaard Logboek Dataverwerkingen. Er wordt toegelicht
hoe de standaard is opgebouwd vanuit het perspectief van verantwoording. Het doel daarvan is dat het
Logboek Dataverwerkingen een basis biedt om te zorgen dat de overheid precies de gegevens logt die
zij nodig heeft om verantwoording af te leggen over haar taken. Niet meer, maar ook niet minder. En
om te zorgen dat organisaties gegevens zodanig loggen dat zij zich niet alleen over een eigen
handelen kunnen verantwoorden, maar ook over hun gezamenlijk handelen als “de overheid”.
Aanleiding en context
Informatiehuishouding van de overheid moet op orde worden gebracht. De overheid werkt ten dienste
van burgers en bedrijven. De overheid verwerkt daarvoor informatie van deze burgers en bedrijven.
Het is belangrijk dat de informatiehuishouding van de overheid op orde is, zodat de overheid
transparant en aanspreekbaar is, en zich daarover goed kan verantwoorden. Eenduidige en integrale
verantwoording over dataverwerkingen door de overheid. Belangrijk is dat overheidsorganisaties op
een eenduidige manier met informatie omgaan en op een eenduidige manier informatie met elkaar
uitwisselen.
Het project Logboek Dataverwerkingen maakt deel uit van het actieplan
Data bij de Bron en onderzoekt met Digilab
in samenwerking met diverse overheidspartijen (ministeries, uitvoeringsorganisaties en gemeentes) of
we op basis van de tot nu toe opgedane inzichten een overheidsbrede standaard kunnen vaststellen.
Verbetering informatiehuishouding
Een belangrijk instrument om verbetering van de informatiehuishouding te bereiken is
standaardisatie. Op diverse aspecten is daarom standaardisatie nodig en worden deze ontwikkeld. Een
van deze aspecten is de wijze waarop overheden zich verantwoorden. Standaardisatie daarvan vormt
daarmee een puzzelstuk in het bredere geheel. Hiermee kunnen overheden hun dataverwerkingen op
dezelfde wijze verantwoorden en deze verantwoording onderling relateren, zodat de keten van
dataverwerkingen tussen organisaties compleet inzichtelijk kan worden gemaakt.
Globale opbouw
De standaard Logboek Dataverwerkingen beschrijft een manier om technisch interoperabele
functionaliteit voor het loggen van dataverwerkingen te implementeren, door voor de volgende
functionaliteit de interface en het gedrag voor te schrijven:
het vastleggen van logs van dataverwerkingen
het aan elkaar relateren van logs van dataverwerkingen
het aan elkaar relateren van dataverwerkingen over de grenzen van systemen
Door Dataverwerkingen te loggen volgens de standaard kunnen organisaties het datagebruik
verantwoorden. De standaard is gericht op verantwoording van Dataverwerkingen door Nederlandse
(overheids)organisaties, gelet op onder meer de Algemene Verordening Gegevensbescherming en de
Algemene Wet Bestuursrecht.
Doelgroep
De standaard heeft als doelgroep iedereen die zich bezighoudt met het implementeren van logging rond
dataverwerkingen en beschrijft alleen wat relevant is voor de implementatie.
De informatiekundige kern en de relatie met FDS
Dataverwerkingen kunnen over applicatiegrenzen heengaan. In sommige gevallen worden gegevens
opgevraagd bij andere applicaties of bij andere organisaties. Om grote en complexe dataverwerkingen
te overzien en uiteindelijk terug te herleiden, is het van belang om traceringsmetadata te loggen
naast de reguliere data die verwerkt is. Het model van traceringsmetadata in de standaard is
gebaseerd op de internationale standaard OpenTelemetry.
De logging van verwerking van data vindt plaats op basis van zogenaamde ‘value pairs’. Dit betekent
dat het data-element genoemd wordt en daarbij de waarde (bijvoorbeeld postcode = 1234AB). De
benaming van de te loggen data moet in overeenstemming zijn met de FDS-filosofie. Meer
achtergrondinformatie en voorbeelden over de Logius Praktijkrichtlijn is te vinden op
Algemene inleiding - Logboek Dataverwerkingen.
18 - Vergelijk van initiatieven voor connectiviteit
Uitkomsten van het onderzoek in Digilab naar het koppelen van datatoepassingen aan dataservices voor het uniformeren van de uitwisseling.
Het Federatief Datastelsel (FDS) wordt ontwikkeld als een ‘data-ecosysteem’ met als belangrijkste doel om maatschappelijke waarde te genereren uit het verantwoord delen van meervoudig bruikbare hoogwaardige data.
Voor de technische functies van het FDS geldt dat het stelsel deze zoveel als mogelijk invult met afspraken en standaarden en alleen als het niet anders kan, met (centraal verplichte) voorzieningen. Het FDS maakt gebruik van standaarden en ontwikkelt deze niet zelf.
Onderzoek
In 2024 is het ‘connectiviteit’ onderzoek uitgevoerd in Digilab naar het koppelen van datatoepassingen aan dataservices voor het uniformeren van de uitwisseling (ook bekend als de FDS demonstrator datadelen).
In het onderzoek is gekozen dit te doen met 3 ontwikkelingen die hierop aansluiten en in een praktische FDS demonstrator te tonen zijn.
FSC - “Federated Service Connectivity”
iShare - “Trust Framework for Data Spaces”
TSG - “TNO Secure Gateway”
Ieder van deze 3 heeft een eigen perspectief en raakt een aantal van de vraagstukken die spelen bij het FDS qua interoperabiliteit, vertrouwen en datawaarde. Uitgangspunt voor een vergelijk is de Nederlandse API strategie, in het bijzonder in relatie tot API-management.
Het vergelijk gaat uit van een toepassing die een dataservice gebruikt met vraagstukken zoals deelnemer registratie, controle op toegang en gebruik, pbac, delegatie, technische interoperabiliteit, beheer, service publicatie en logboeken.
Aspecten
Vanuit het perspectief van het FDS kijken we naar ontwikkelingen rond de volgende aspecten:
Samenwerking: De federatieve architectuur moet organisaties in staat stellen direct samen te werken, waarbij gegevens efficiënt en veilig tussen systemen kunnen worden uitgewisseld, liefst zonder afhankelijkheid van een centrale tussenpartij. We zoeken de grootste overlap met de FDS doelgroep.
Uniformering: Gegevensuitwisseling moet gebaseerd zijn op uniforme standaarden en liefst protocollen, zodat verschillende systemen op een consistente en voorspelbare manier kunnen communiceren, ongeacht de infrastructuur van de betrokken partijen.
Verdeling van verantwoordelijkheid: Elke partij blijft verantwoordelijk voor het beheer van zijn eigen data, met duidelijke afspraken over wie welke gegevens kan opvragen en delen. Dit bevordert autonomie en controle over data bij alle betrokken partijen.
Veiligheid: Het systeem moet garanderen dat gegevens veilig worden overgedragen en opgeslagen, met gebruik van versleuteling, authenticatie en autorisatie, zodat de vertrouwelijkheid en integriteit van gegevens beschermd zijn.
Beheerbaarheid: Toegang tot en gebruik van gegevens moet beheersbaar zijn, met heldere processen om toegangsrechten te verlenen en in te trekken. Dit vereist een duidelijk toegangsbeheer voor alle betrokken partijen.
Controleerbaarheid: Het systeem moet de mogelijkheid bieden om gedetailleerde logs bij te houden van wie toegang heeft gehad tot welke gegevens en wanneer, zodat audits en naleving van regelgeving mogelijk zijn.
Governance: Waar is (door)ontwikkeling belegd, hoe hebben gebruikers invloed. Welke governanceprocessen zijn er die bepalen hoe de systemen worden beheerd, wie verantwoordelijk is voor besluitvorming, en hoe wijzigingen en naleving van afspraken worden bewaakt.
Naburige initiatieven
Standaardisatie vanuit Europa
Europees is er sinds kort het initiatief tot Europese standaardisatie JTC 25 ‘Data management, Dataspaces, Cloud and Edge. In Nederland verzorgt het NEN de Nederlandse normcommissie ‘Datamanagement, dataspaces, cloud en edge’.
Simpl
Simpl is een open-source middleware-platform dat gegevens toegang en interoperabiliteit ondersteunt binnen Europese dataspaces.
Het initiatief komt vanuit het DIGITAL Europe Work programma. Simpl speelt een rol bij de oprichting van de Gemeenschappelijke Europese Dataspaces.
Solid
Solid Solid is een specificatie waarmee mensen hun data veilig kunnen opslaan in gedecentraliseerde datastores, zogenaamde Pods. Pods fungeren als veilige persoonlijke webservers voor data.
Deelnemers bepalen zelf wie toegang krijgt tot hun data in hun Pod. Ze beslissen welke data gedeeld wordt en met wie (individuen, organisaties, applicaties, enz.), en kunnen deze toegang op elk moment intrekken.
Solid-compatibele applicaties gebruiken standaard, open en interoperabele dataformaten en -protocollen om data in een Pod op te slaan en te benaderen.
Gaia-X
Gaia-X is een Stichting met een initiatief dat, gebaseerd op Europese waarden, een digitale governance ontwikkelt die toepasbaar is op elke bestaande cloud- of edge-technologiestack om transparantie, controleerbaarheid, overdraagbaarheid en interoperabiliteit over data en diensten te waarborgen.
FSC
Techniek
Standaardiseert de koppeling tussen organisaties door voor te schrijven hoe het managementverkeer en het dataverkeer verloopt tussen API’s van organisaties. Het is een peer-to-peer netwerk, waarbij het gebruik van de “directory” als centrale component optioneel is.
FSC biedt een veilige manier voor organisaties om met andere organisaties te delegeren. Het delegatie mechanisme maakt het mogelijk namens een organisatie data op te halen bij een bron en om API’s namens een andere organisatie aan te bieden. Daarnaast voorziet FSC standaardisatie voor audit en technische logging.
FSC werkt nu op basis van PKIOverheid certificaten en biedt ruimte voor verifiable credentials.
Gebruik
FSC is als voorloper NLX bij gemeente Utrecht in gebruik, Kadaster en gemeente den Bosch ondernemen proeven. RINIS biedt ondersteuning op FSC. In Digilab zijn er diverse koppelingen mee opgezet.
Vorm
FSC is een standaard gericht op federatieve verbindingen. De standaard richt zich op interoperabiliteit van REST APIs onafhankelijk van een implementatie. De standaard komt voort uit de common ground visie en heeft een open source referentie implementatie die productie-waardig is.
Federatief
Deze standaard wijzen we aan als standaard voor het Federatief Datastelsel voor gebruik tussen overheden. FSC is onderdeel van de GDI. Het voornemen is om FSC op te nemen in het Digikoppeling REST API profiel.
iShare
Techniek
iShare heeft een hub en spoke model.
Per dataspace is er een satellite, die in verbinding staat met een parent satellite.
De satellite is de plek waar alle deelnemers staan geregistreerd.
Machtigen/Delegeren gaat door middel van policies.
Een Entitled Party kan daarin aangeven welke service rechten hij delegeert aan een specifieke service consumer.
Deze policies kunnen in een authorization registry worden vastgelegd.
Het technische framework is nog in ontwikkeling evenals de test-tooling. De software op github is een voorbeeld, in de praktijk zijn verschillende versies in gebruik. De satellite is niet openbaar, de broncode is beschikbaar voor deelnemers aan iShare.
iShare biedt ondersteuning voor certificaten onder eIDAS en heeft aaknopingspunten voor andere authenticatiemechanismen.
Gebruik
Meest toonaangevende voorbeeld is DVU rond energiegebruik. RVO laat een omgeving door DICTU beheren met het beheer van de satelliet door KPN.
Andere voorbeelden in ontwikkeling zijn BDI, DMI en DSGO. In Digilab is het werkend gekregen, het vroeg echter veel eigen implementatie-keuzes.
Vorm
iShare is een op zich staand legal framework, het maakt gebruik van verschillende standaarden en heeft een focus op het protocol met verschillende implementatie scenarios. Er is een streven naar Europese adoptie.
iShare als stichting voert certificeringen uit van de (iShare) autorisatie registers. iShare is een vertrouwensraamwerk gericht op de markt. Deelnemers betalen een bijdrage aan de stichting.
Federatief
Aangezien iShare een niet geformaliseerde standaard is maar wel als oplossing voor data-delen gebruikt maakt van standaarden kan het een platform zijn dat een stelsel gebruikt om aansluiting te vinden bij een FDS.
TSG
Techniek
De TNO Security Gateway (TSG) is een open-source IDS-connectorimplementatie, ontwikkeld door TNO. De beproefde connector is sinds mei 2024 beschikbaar. De TSG faciliteert de koppeling tussen organisaties door voor te schrijven hoe het managementverkeer en het dataverkeer verloopt tussen API’s van organisaties.
Specificatiewerk gestart eind 2022 als subwerkgroep van de WG Architecture van IDSA. Governance is overgedragen aan de Eclipse stichting.
De TSG-componenten (als IDS implementatie) stellen je in staat deel te nemen aan een IDS-dataspace om informatie uit te wisselen met andere organisaties, met aandacht voor data-soevereiniteit. De broncode is open-source, beschikbaar onder de Apache 2.0-licentie.
De TSG richt zich voor authenticatie op het gebruik van verifiable credentials.
Gebruik
De TSG is meer een onderzoeksproject, niet gericht op productie en recent ontwikkeld. Binnen Digilab is de TSG in een uur werkend opgezet met hulp van TNO.
De IDS beschrijving geeft geen garantie dat een implementatie technische interoperabiliteit krijgt tussen verschillende IDS-connectoren. Er is veel keuzevrijheid bij de invulling van de IDS protocollen.
Vorm
IDS bestaat uit drie afzonderlijke protocollen, de TSG volgt dit in de implementatie:
Catalogusprotocol
Protocol voor contractonderhandelingen
Protocol voor gegevensoverdracht
Niet gespecificeerd in het Dataspace Protocol:
Identificatie, Authenticatie & Autorisatie
Intermediaire diensten
Federatief
Deze IDSA connector sluit aan bij het internationale initiatief. Het voornemen is het dataspace protocol te verheffen tot een standaard. Vanuit de Eclipse stichting werkt men hier aan. Het is geen initiatief vanuit een Europese organisatie, dit is een initiatief van de Eclipse stichting.
19 - Standaarden
Het programma realisatie FDS heeft een eerste lijst met standaarden opgesteld die partijen in eerste instantie moeten toepassen om federatief datadelen mogelijk te maken.
Deze notitie over standaarden in het federatief datastelsel is het vertrekpunt voor het gebruik van
standaarden. Het federatief model laat opslag en beheer van data lokaal aan bronhouders, maar
faciliteert datagebruik over bronnen heen, centraal door een interoperabel systeem van afspraken en
oplossingen op ontsluiting, toegang, annotatie en koppeling.
Context
Op een federatieve manier data delen is alleen maar mogelijk als partijen dezelfde standaarden
toepassen. Over de wijze waarop worden in het stelsel nadere afspraken gemaakt, alsook over de
invulling van de benodigde organisatorische stelselfuncties, financiering, etc.
Het programma realisatie-FDS heeft een eerste lijst met standaarden opgesteld die partijen in eerste
instantie moeten toepassen om federatief datadelen mogelijk te maken. deze lijst treft u aan in
bijlage 1. dit is een combinatie van bestaande standaarden recent ontwikkelde standaarden en
standaarden in ontwikkeling. er zijn meer standaarden nodig waar we in de loop van de tijd zicht op
zullen krijgen. deze eerste lijst wordt gepubliceerd om onze omgeving al vroegtijdig inzicht te
geven in relevante standaarden zodat men daar rekening mee kan houden.
Hoe worden de standaarden vastgesteld?
Voor het vaststellen van standaarden wordt gebruik gemaakt van het bestaande besluitvormingsproces.
Forum Standaardisatie toetst open standaarden en adviseert het Overheids-breed Beleidsoverleg
Digitale Overheid (OBDO) over het voorschrijven ervan aan publieke organisaties. Dit kan als
aanbeveling of volgens een ‘Pas toe of leg uit’-verplichting. Standaarden met een ‘Pas toe of leg
uit’-verplichting kunnen verzwaard worden met een streefbeeldafspraak of tot wettelijke
verplichting.
Standaarden worden vastgesteld via de bestaande procedure van het Forum;
De voor FDS relevante standaarden zijn ook (bestaande of beoogde) GDI-standaarden, daarvoor wordt
de bestaande governance van de GDI gebruikt;
De architectuurraad GDI adviseert de PGDI en IDO;
Bespreking van gebruik van standaarden voor FDS vindt plaats in het Tactisch Overleg FDS. Indien
relevant voor de CDO’s dan ook in de CDO-raad.
Het IDO fungeert als ‘voorportaal’ van het OBDO op het gebied van datavraagstukken en heeft een
regisserende en stimulerende rol (sponsor). Het IDO is geen besluitvormend overleg. Het OBDO
bekrachtigt de standaarden;
In het OBDO kunnen afspraken gemaakt worden over implementatie(ondersteuning) van standaarden.
Is er meer nodig dan opname van de standaarden op de ‘pas toe of leg uit’-lijst?
Het gebruik van standaarden is essentieel voor de werking van het FDS. Afnemers van data kunnen deze
alleen gebruiken als aanbieders en afnemers voldoen aan de afspraken die in het stelsel zijn
gemaakt. In veel gevallen zullen partijen zelf de meerwaarde van de toepassing van standaarden in de
eigen context zien en zullen deze in de loop der tijd gebruikt worden.
Dit zal echter niet opgaan voor standaarden waarvan de meerwaarde van het gebruik vooral tot uiting
komt op stelselniveau. Bovendien laat het verleden zien dat zonder flankerend beleid de adoptie van
dergelijke standaarden minstens 10 jaar duurt.
Voor het slagen van FDS is het van belang dat de prioriteit van het toepassen van de noodzakelijke
standaarden voor aanbieders en afnemers hoog is. Dat kan door een combinatie van maatregelen:
Gestructureerd, aan de hand van een meerjaren implementatie agenda, afspraken maken over
ontwikkeling en adoptie van standaarden;
Implementatie-ondersteuning voor deelnemers in het stelsel;
Het monitoren van de voortgang;
Het op termijn verplichten van de minimaal noodzakelijke standaarden in de Wet Digitale overheid.
FDS standaarden: de basis
Hieronder staan de standaarden beschreven die partijen in eerste instantie moeten toepassen om op de
FDS-manier te gaan werken. Daarnaast is een aantal standaarden benoemd die op dit moment ontwikkeld
wordt zodat daar nu al rekening mee kan worden gehouden en meegedaan kan worden bij de
totstandkoming als dat gewenst is. Standaarden die ook toegepast moeten worden maar meer generiek
van aard zijn (informatiebeveiliging) of zeer specifiek zijn (bijvoorbeeld geo-standaarden), zijn
niet opgenomen in dit document omdat die niet FDS-specifiek zijn.
Doel: Inzicht in het data-aanbod
Wat omvat de standaard
Standaard
Status van de standaard
Standaard voor het beschrijven van datasets: Welke datasets (gegevensverzamelingen) zijn beschikbaar, welk licentietype, toegangsregime is daarop van toepassing, wie biedt de dataset aan? Welke dataservices worden bij een dataset aangeboden?
Standaard voor het beschrijven van dataservices (gegevensdiensten): welke dataservices zijn beschikbaar, welk licentietype, toegangsregime is daarop van toepassing, wie biedt de dataservice aan? Op welke datasets opereert de dataservice?
Inzicht in de betekenis van begrippen en relaties met andere begrippen (bijv. uit andere sectoren)
SBB
In goedkeuring
SKOS
Verplicht (pas toe of leg uit)
Doel: Ontsluiten van data
Wat omvat de standaard
Standaard
Status van de standaard
API’s waarmee data direct kan worden bevraagd (dataservices) of waarmee functionaliteit wordt ontsloten (services)
REST API Design Rules
Verplicht (pas toe of leg uit)
Uitwisselen van berichten tussen applicaties over plaatsgevonden gebeurtenissen (notificaties)
CloudEvents
Internationale standaard
NL Gov CloudEvents
In goedkeuring
Het veilig en geautomatiseerd kunnen koppelen van services tussen verschillende organisaties
Sommige belangrijke open standaarden worden te weinig gebruikt, waardoor onze digitale samenleving
kwetsbaar, inefficiënt of niet toegankelijk is voor iedereen. Daarom geldt voor deze standaarden het
‘Pas toe of leg uit’-beleid. De verplichting geldt voor gemeenten, provincies, rijk, waterschappen
en alle uitvoeringsorganisaties. Voor alle andere organisaties in de publieke sector geldt het
gebruik van de ‘Pas toe of leg uit’-standaarden als een dringend advies.
Pas toe
‘Pas toe’ betekent dat op het moment dat u ICT aanschaft (een dienst of en product), u de ‘Pas toe
of leg uit’-lijst moet raadplegen. Wanneer de aanschaf valt onder een toepassingsgebied dat voorkomt
op deze lijst, moet u de standaard(en) toepassen.
Leg uit
Afwijken van het gebruik van de voorgeschreven standaarden mag alleen als een dergelijke dienst of
product in onvoldoende mate wordt aangeboden, onvoldoende veilig of zeker functioneert of om een
andere reden die van bijzonder gewicht is. De afwijking en de reden daarvan moeten beschreven worden
in de bedrijfsvoeringparagraaf van het jaarverslag. Dit is de betekenis van ‘leg uit’.
Streefbeeldafspraken en wettelijke verplichting
Voor sommige standaarden duurt het moment van een volgende aanschaf te lang, waardoor de publieke
dienstverlening te veel risico loopt. Er worden dan Streefbeeldafspraken gemaakt om de adoptie te
versnellen. En leiden ook deze afspraken tot onvoldoende resultaat, dan kan een standaard in
aanmerking komen voor wettelijke verplichting op grond van de Wet digitale overheid.
20 - Uit betrouwbare bron
Onderzoek naar de capabilities van een ‘bron’ om een betrouwbare datadienst te zijn in een federatief datastelsel.
In een federatief datastelsel wordt data aangeboden en afgenomen / gebruikt. Over het gebruik van de
data dient verantwoording te worden afgelegd. Niet alleen dát het gebruikt is en waarvoor, maar ook
ter onderbouwing van genomen besluiten. Als een afnemer een besluit baseert op een ‘extern gegeven’
is het wenselijk (noodzakelijk?) dat nagegaan kan worden welk gegeven dat was, welke zekerheid er
aan dat gegeven hangt, dat deze te reproduceren is, dat de oorspronkelijke herkomst duidelijk is,
eventuele correcties, etc, etc. Dit vraagt om uitgebreide capabilities van de datadienst die als
bron wordt gebruikt. Dit dient een betrouwbare bron te zijn. Wat maakt dat een bron als
betrouwbaar gekenmerkt kan worden? Welke capabilities zijn dat?
Project Uit betrouwbare bron
Het Project Uit betrouwbare bron is een project van VNG Realisatie
om uit te vinden welke capabilities een betrouwbare bron nodig heeft en wanneer we dus kunnen
spreken van een betrouwbare bron. Stelselfuncties als Modellen, Dataservices en
Traceerbaarheid zullen op een bepaalde manier ingevuld moeten worden om aan te sluiten op te
verwachten bevindingen vanuit betrouwbare bron. En dat zal ook inzicht geven in de richting waarin
de stelselfuncties van FDS (datadiensten) zich het beste kunnen ontwikkelen om aan te sluiten bij
behoeften van afnemers. Daarom is nauwe samenwerking met en opnemen van de uitkomsten van het
project Uit betrouwbare bron van grote waarde voor de vorming van het FDS.
Relatie tot FDS
Nauwe samenwerking en volgen van het Project Uit betrouwbare bron door het kernteam FDS.
2024 Q3 Project Uit betrouwbare bron uitnodigen voor presentatie in inhoudelijk blok
2024 Q3/Q4 actieve samenwerking met Project Uit betrouwbare bron door kennisdeling en
gezamenlijke sessies (met name FDS Architectenteam)
2025 Q1/Q2 update van Project Uit betrouwbare bron in inhoudelijk blok
21 - Rol van private datasets
Wat is voor het FDS een private dataset
Het Federatief Datastelsel (FDS) ontsluit alleen publieke datasets en geen private datasets.
Hieronder wordt uitgelegd wat hiervoor de reden is en wat precies het verschil tussen beide is.
Algemeen kader
Het FDS is een afsprakenstelsel dat voor de overheid het domeinoverstijgend (cross sectoraal)
datadelen faciliteert. Het FDS biedt de aangesloten overheidsafnemers toegang tot de data die ze
nodig hebben voor het uitvoeren van hun wettelijke taken. Kortom een stelsel van en voor de
overheid. Het FDS verschilt daarin van de EU datastelsels / dataspaces die zijn gericht op het
creëren van economische waarde: het mogelijk maken van een “data markt”, of het vereenvoudigen van
het economisch verkeer. Het FDS ondersteunt bovendien alleen het toepassen van het FDS-aanbod. Het
FDS bevat geen afspraken over de totstandkoming van daarvan: de inrichting van de relaties tussen de
(keten)partijen die betrokken zijn bij de inwinning en bijhouding.
Vanwege deze kenmerken biedt het FDS alleen publieke datasets aan en valt het aanbieden van private
datasets buiten de scope van het FDS.
Zie voor een uitleg van het verschil tussen private en publieke datasets de volgende hoofdstukken en
voor meer informatie over het FDS-kader de pagina wat is het FDS.
Wat is in de FDS-context een private dataset?
Een private dataset is een verzameling gegevens die voor rekening en risico van een private partij
is ingewonnen en waarvan een private partij daarom het eigendomsrecht kan claimen. Deze
data-eigenaar moet zich aan algemene kaders zoals de AVG houden, maar kan verder helemaal zelf
bepalen wat hij met zijn data doet en dus ook hoe hij deze aanbiedt. Hij kan zijn data onder een
standaard gebruikslicentie beschikbaar stellen, of hij kan met afnemers specifieke afspraken over
het beschikbaar stellen van de data maken. Deze afspraken zijn bij een private dataset de uitkomst
van een onderhandelingsproces tussen in formele zin gelijkwaardige partijen. De aanbieder is niet
verplicht om zijn data aan te bieden, de afnemer is niet verplicht om deze af te nemen. Wat ze
onderling willen regelen bepalen ze zelf en leggen ze in een overeenkomst vast. Bij datastelsels
waarin private data tussen private partijen wordt gedeeld vormen privaatrechtelijke contracten
tussen de betrokken stelseldeelnemers het formele kader voor de rechten en plichten van
data-aanbieders en data-afnemers
Wat is in de FDS-context een publieke dataset?
In een publiek datadeelstelsel zoals het FDS werkt het anders. Als hoeder van het publieke belang
hebben we als overheid de wet als instrument om zeggenschap over het datadelen af te dwingen. Met
wetgeving kunnen we de private data die we nodig hebben in het publiek domein trekken. Een voorbeeld
hiervan is de wettelijke verplichting voor netwerkbeheerders om gegevens over de ligging van hun
netwerk aan de door het Kadaster beheerde kabel- en leidingenregistratie te leveren. Zo kunnen we
als overheid ook gegevens die we niet zelf hebben ingewonnen (private gegevens) onderdeel van bij
wet ingestelde registratie maken. Het zijn daarmee publieke gegevens geworden. Bij het ontwerp van
het het FDS is aangenomen dat we als overheid het wettelijk instrumentarium toepassen om relevante
data voor overheidsgebruik te verkrijgen. Via wet- en regelgeving kan vervolgens het delen worden
beperkt, of juist worden verruimd (aanmerken als open data) en kunnen er eisen worden gesteld aan in
de dataset opgenomen gegevens, zoals het verplicht toepassen van voor de overheid belangrijke
identifiers (zoals bsn’s, kvk’nrs, bag-id’s). Het FDS ontsluit dus datasets die op grond van een wet
worden ontsloten, waarbij in wetgeving de rechten en plichten van data-aanbieders en data-afnemers
zijn vastgelegd. Bij die datasets is er geen sprake van de voor private data zo kenmerkende
contractvrijheid.
Belangrijk hierbij is dat het FDS-afsprakenkader alleen het domeinoverstijgend, datadelen tussen
overheden reguleert en niet de inwinning en bijhouding van de onder het FDS-regime aangeboden
datasets. Het is heel gebruikelijk dat een FDS data-aanbieder voor het vullen van een vanuit zijn
wettelijke taak aangeboden publieke dataset gebruik maakt van door private partijen ingewonnen
gegevens. Het inrichten van de daarvoor benodigde gegevensuitwisseling tussen private bronhouders en
de overheidsorganisatie die als FDS-data aanbieder optreedt, valt echter buiten het
FDS-afsprakenkader aangezien het hier sector/domeinspecifieke ketenprocessen betreft. Het reguleren
daarvan is de taak van het voor het domein verantwoordelijke beleidsdepartement.
Rationale: waarom worden private, niet op grond van een wettelijke taak aangeboden, datasets buiten de FDS-scope gehouden?
Privaat aanbod faciliteren vergroot de complexiteit en leidt tot extra kosten:
Bij het ontbreken van een wettelijke taak kan het onder het FDS-afsprakenstelsel ontsluiten van de
private dataset als een marktactiviteit worden beschouwd waarvoor de gedragsregels uit de Wet
Markt en Overheid gelden. In dat geval is de FDS-data-aanbieder bijvoorbeeld verplicht om alle met
de datadienst gemoeide kosten,inclusief BTW, aan de FDS data-afnemers door te berekenen.
Bij datadelen op grond van een publieke taak kan conformiteit met het FDS-afsprakenkader vanuit de
overheid verplicht worden gesteld. Daarmee worden rechten en plichten van data-aanbieders en
data-afnemers overkoepelend geregeld. Bij een zuiver privaatrechtelijk aanbod zal elke
data-afnemer zelf een contract met de data-aanbieder moeten afsluiten om de betreffende data te
kunnen afnemen.
Vanuit governance perspectief is een privaatrechtelijk gereguleerde ontsluiting ook ingewikkeld.
Er zijn dan geen beleidsopdrachtgevers die als stelselregisseur sturend kunnen optreden en
gezamenlijk bindende generieke stelselafspraken kunnen maken, bijvoorbeeld over het toepassen van
een nieuwe standaard of over de verrekening van de kosten. Zonder wettelijk basis kunnen private
data-aanbieders ook niet aan het stelseltoezicht worden onderworpen.
Bij een privaat, niet wettelijk gereguleerd, aanbod, zijn er ook meer continuïteitsrisico’s.
Contracten zijn eindig en de aanbiedende partij kan er mee stoppen als het voor hem niet meer
aantrekkelijk is en als de private partij failliet gaat, houdt het sowieso op.
Er wordt vooralsnog van uitgegaan dat het meeste data-aanbod dat gekwalificeerd is voor verantwoord
meervoudig, cross sectoraal datadelen voor het uitvoeren van overheidstaken voortkomt uit een door
de overheid gereguleerde registratie en dat de restgroep van zuiver privaat aanbod te klein is om de
meerkosten van opname in het FDS te rechtvaardigen.
Deze scopebeperking heeft overigens alleen betrekking op het data-aanbod vanuit het FDS (de
datasets). De interoperabiliteitsafspraken en -standaarden die in het FDS worden toegepast zijn ook
bruikbaar voor het binnen sectoren/ketens delen van (private) datasets die niet aan de
FDS-deelnamevoorwaarden voldoen.
22 - IMX
IMX maakt op een gestandaardiseerde wijze model-gedreven orkestratie mogelijk.
In een federatief datastelsel is het efficiënt benutten van informatie uit verschillende bronnen een behoorlijke uitdaging. Bronregistraties bevatten vaak complexe, hoog-genormaliseerde gegevens, uitgedrukt in sectorgebonden terminologie. Er is dan ook vaak specifieke domeinkennis vereist om gegevens correct te kunnen interpreteren en combineren binnen een bepaalde context. Gebruikerstoepassingen daarentegen, vereisen vaak een veel eenvoudiger en doelgerichter informatiemodel, gericht op het snel kunnen raadplegen van relevante en begrijpelijke informatie, zonder direct geconfronteerd te worden met de complexiteit van de achterliggende databronnen. Dit is waar orkestratie een cruciale rol speelt.
IMX is een set standaarden, ondersteund door een referentie-implementatie, die het mogelijk maakt om gegevens op een model-gedreven manier met elkaar te combineren en beschikbaar te stellen als een nieuw informatieproduct. De referentie-implementatie biedt daarbij een orkestratie-oplossing, die helpt om het combineren van gegevens en de interactie met achterliggende bronnen op een betrouwbare en efficiënte manier invulling te geven. Gegevens blijven daarbij herleidbaar naar hun authentieke bron(nen).
Model Mapping
De IMX Model Mapping standaard specificeert een taal waarmee een vertaalspecificatie (mapping) kan worden opgesteld om vanuit bestaande bronmodellen te transformeren naar een beoogd doelmodel (productmodel). Deze mappingtaal is opgesteld conform een aantal belangrijke basisprincipes:
Machine-leesbaar: Door de mapping uit te drukken in een machine-leesbaar (YAML-gebaseerd) formaat wordt het o.a. mogelijk om een orkestratie-oplossing aan te sturen en automatisch herkomst vast te leggen, zonder dat er specifieke programmatuur nodig is.
Implementatie-onafhankelijk: De taal is volledig onafhankelijk van technische implementaties, dataformaten of modelleringsstandaarden. Dit maakt een brede toepassing van de mapping mogelijk.
Declaratief: De vertaalregels worden beschreven vanuit de intentie van de mapping, zonder expliciet te beschrijven welke stappen hiervoor uitgevoerd dienen te worden. Dit geeft implementaties de vrijheid om zelf de meest optimale strategie te kiezen om gegevens te raadplegen en te combineren.
Model-gedreven: Om onafhankelijk te blijven van technische datamodellen en bijbehorende dataformaten, wordt de mapping uitgedrukt op logisch niveau. Een logisch datamodel definieert de structuur van gegevens en hun onderlinge relaties, maar is onafhankelijk van de technische implementatie ervan. Dit draagt bij aan de onafhankelijkheid van de mapping ten opzichte van implementaties.
Stapelbaar: Met stapelbaar wordt bedoeld dat het productmodel van een model mapping ook weer als bronmodel kan dienen in een daarboven gelegen orkestratie. Zo kan de ene organisatie een halffabrikaat leveren, wat weer door een andere organisatie als bron gebruikt kan worden binnen een andere orkestratie-context.
Zowel bron- als doelmodel dient te zijn gemodelleerd op logisch niveau. Dit correspondeert met het MIM beschouwingsniveau 3.
De mappingtaal leunt sterkt op het functional programming paradigma en ondersteunt o.a. de volgende patronen om gegevens te combineren en transformeren:
Pad-gebaseerde selectie van nodes in een model
Joinen op unieke sleutels of andere kenmerken (zoals geografische overlap)
Herschikken structuur (platslaan, of juist nesten)
Wanneer gegevens worden gecombineerd tot een nieuwe informatieproduct is het van belang dat inzichtelijk blijft welke authentieke brongegevens zijn gebruikt, en welke modificaties (bijv. algoritmes) er zijn gebruikt om tot het eindproduct te komen. Hierdoor is transparant, en kan worden verantwoord, op welke manier gegevens tot stand zijn gekomen. Het IMX Lineage Model is een logisch informatiemodel, waarin de herkomst van gegevens op een gestandaardiseerde manier kan worden uitgedrukt. Dit model is gebaseerd op de internationale open PROV-O ontologie.
De IMX orkestratie engine is een open source referentie-implementie die op basis van bron- en doelmodellen, gecombineerd met een model mapping, automatisch een orkestratie-service in de lucht brengt. Deze service stelt gegevens als API beschikbaar conform het beoogde doelmodel, waardoor gebruikers-applicaties slechts met 1 enkele service hoeven te interacteren en geen complexe nabewerking hoeven te doen op de brongegevens. Daarnaast houdt de engine tijdens het orkestratie-proces de herkomstgegevens bij en stelt deze beschikbaar conform het IMX lineage model.
De orkestratie-service haalt alle benodigde gegevens realtime op bij de bronnen, waardoor geen kopie benodigd is en gegevens altijd actueel en betrouwbaar zijn. Onder de motorkap worden daarbij diverse optimalisaties toegepast, om dit proces zo efficiënt als mogelijk uit te voeren, waaronder:
Fijnmazige selectie: Op basis van de selectie van de gebruiker worden alleen de daadwerkelijk benodigde gegevens bij de bronnen opgevraagd. Niet meer, niet minder.
Query planning: De engine berekent op basis van de gestelde vraag, de mapping en tussentijdse resultaten, wat het meest efficiënte plan is om gegevens bij de bronnen te raadplegen. Sommige stappen kunnen parallel en anderen juist niet, omdat er een onderlinge afhankelijkheid is.
Batching: Als meerdere gelijksoortige objecten benodigd zijn, en de bron batching ondersteunt, worden deze verzoeken gebundeld tot 1 enkele batch-bevraging.
De-duplicatie: Als een gegeven al eerder bevraagd is, en op een andere plek nogmaals benodigd is, wordt deze niet opnieuw geraadpleegd.
De orkestatie-engine is backend-onafhankelijk, wat betekent dat er verschillende soorten backend gekoppeld kunnen worden. Een aantal voorbeelden zijn: REST API’s conform de NL API Design Rules, OGC API Features, GraphQL, JSON-bestanden, etc. De implementatie biedt de mogelijkheid om zelf adapters toe te voegen om specifieke API-soorten te kunnen ondersteunen.
De IMX-beproeving in Digilab heeft aangetoond dat de technologie effectief is in het orkestreren van data uit verschillende bronnen zonder de noodzaak van data-kopieën.
Vanaf augustus ‘24 tot begin volgend jaar (2025) loopt er een vervolgonderzoek, dat zich richt op de uitbreiding van de IMX-methodologie naar niet-geo-registraties. Doel is om door middel van model-gedreven orkestratie gegevens uit verschillende registraties te combineren zonder de noodzaak voor data-kopieën. Belangrijke aspecten zijn het verbeteren van beveiligingsstandaarden (zoals authenticatie en autorisatie) en het aansluiten bij linked data. Dit onderzoek moet bijdragen aan bredere toepasbaarheid en draagvlak binnen de overheid, wat een toekomstbestendige oplossing biedt voor datadeling en integratie binnen het FDS.
Andere uitdagingen die in de toekomst nader onderzocht zouden kunnen worden:
Welke standaarden en capabilities zouden bronnen aan moeten voldoen om beter geschikt te zijn voor orkestratie?
Op welke manier past orkestratie binnen proces-geörienteerde applicaties?
Hoe om te gaan met kwaliteits-afwijkingen in een orkestratie-proces?
Hoe om te gaan met onbeschikbaarheid in een orkestratie-proces?
23 - Informatiekundige kern van het FDS
Uitleg concept informatiekundige kern
Uitleg van het doel en de inhoud van de informatiekundige kern van het FDS
Het onderkennen van een Informatiekundige kern is een belangrijk element binnen het ontwerp van het
Federatief Datastelsel (FDS). Het is echter ook een nieuw concept met het risico van
begripsverwarring en verkeerde toepassing. Hieronder wordt in verschillende stappen uitgelegd waarom
we een informatiekundige kern binnen het FDS onderkennen, wat het concreet inhoudt en hoe
stelselpartijen er mee om moeten gaan.
Wat maakt een stelsel tot stelsel?
Een setje losse datasets (registraties) wordt een datastelsel doordat gegevens in die datasets
betrouwbaar aan elkaar kunnen worden gerelateerd. Informatiekundig is het dan belangrijk dat je
zeker weet dat je het over hetzelfde of dezelfde hebt. Wat dan erg helpt is dat je afspreekt om
gebruik te maken van dezelfde identificerende gegevens. Het handigst zijn dan unieke nummers (‘id’s’
of ‘sleutels’). Er zijn immers heel veel Janssens, zelfs heel veel Jan Janssens en misschien zelfs
wel meerdere Jan Janssens die op 4 oktober 1956 zijn geboren, maar er is maar één Jan Janssen met
het BSN 123456789.
Hoe zit het nu? Identificerende nummers in het stelsel van basisregistraties
Binnen elk domein komen identificerende nummers voor van kadastrale object id’s tot kentekennummers
maar zoals de ‘Stelselplaat’ laat zien, worden vooral de identificerende nummers uit de
basisregistratie personen (BRP), het Handelsregister (HR) en de basisregistratie adressen en
gebouwen (BAG) gebruikt om relaties tussen registraties in verschillende domeinen te leggen. De
basisregistraties BRP, HR en BAG vormen daarmee in de praktijk de kern van het huidige stelsel.
Van veel gebruikte basisregistraties naar de informatiekundige kern van het FDS
Waarom zijn de BRP, BAG en HR ook de kern van het Federatief Datastelsel?
Bij het Federatief datastelsel (FDS), de opvolger van het stelsel van basisregistraties, willen we
meer data verbinden om die te gebruiken bij maatschappelijke opgaven. Daarvoor is het vrijwel
altijd nodig om te weten over wie het gaat en/of waar het zich afspeelt.
BRP en HR leveren de gegevens om eenduidig naar die ‘wie’ te verwijzen: de identificerende
gegevens van natuurlijke en niet-natuurlijke personen (organisaties).
De BAG levert de gegevens om eenduidig naar het ‘waar’ te verwijzen: de identificerende gegevens
van een locatie.
BRP, BAG en HR bevatten veel gegevens die wat zeggen over personen, organisaties en locaties, maar
slechts een beperkt deel daarvan is nodig om ze te kunnen identificeren. Die ‘identificerende
gegevens’, vormen de informatiekundige kern van het FDS.
Inhoud van de informatiekundige kern – de essentiële identificerende gegevens
De informatiekundige kern bestaat in elk geval uit de identificerende nummers die specifiek bedoeld
zijn om personen, organisaties en locaties te identificeren: BSN, KVK-nummer en het adresseerbaar
object-id. Deze vormen de essentiële inhoud van de informatiekundige kern. We bouwen een datastelsel
als we afspreken dat elke daarin op te nemen dataset (registratie) in elk geval één van deze nummers
gebruikt voor het vastleggen van gegevens over het wie en waar, oftewel een koppeling legt met de
informatiekundige kern. Binnen het huidige stelsel van basisregistraties is dit al de praktijk. Er
zijn echter meer dan 100 potentiële registraties met waardevolle gegevens over personen en locaties.
Dat zijn allemaal kandidaten voor het nieuwe Federatief Datastelsel. Maar deze registraties bevatten
nog niet allemaal deze identificerende nummers en kunnen of mogen die soms ook niet opnemen (geldt
voor het BSN). Hoe zorg je ervoor dat je ze dan toch al meteen in samenhang kunt gebruiken? Dit
kunnen we oplossen door een beperkt aantal andere gegevens toe te voegen die het mogelijk maken om
de inhoud van deze registraties toch al zinvol te verbinden terwijl ze de essentiële gegevens (nog)
niet kunnen toepassen.
De inhoud van de informatiekundige kern – aanvullende identificerende gegevens
Datasets (registraties) die niet de standaard identificerende nummers bevatten, bevatten vaak wel
andere gegevens uit de BRP, het HR en de BAG waarmee we personen, organisaties en locaties ook
betrouwbaar kunnen identificeren. Hier kunnen we gebruik van maken door deze gegevens ook toe te
passen om binnen het Federatief Datastelsel te koppelen. Je realiseert dan al waarde met deze data
zonder dat je hoeft te wachten tot overal ‘de essentie’ is geïmplementeerd. Om dit goed te laten
werken, moeten we wel duidelijk afspreken wat we precies willen gaan gebruiken: welke gegevens uit
BRP, HR en BAG vormen in eerste instantie samen vanuit informatiekundig perspectief de kern van
het Federatief Datastelsel?
Deze vraag is in 2023 opgepakt door de FDS-werkgroep Informatiekundige Kern. De volgende paragraaf
bevat hun voorstel voor de inhoud van deze kern.
Toepassing van de informatiekundige kern bij het realiseren en benutten van het FDS
Inhoudelijk vertrekpunt
De informatiekundige kern van het Federatief Datastelsel is dus in essentie een afspraak over een
set minimaal toe te passen identificerende gegevens. Daarbij wordt vooralsnog uitgegaan van de
volgende inhoud van deze set:
(Voorstel eind 2023 van de FDS-werkgroep Informatiekundige Kern)
Het werkend krijgen van het concept van de informatiekundige kern
Om te zorgen dat alle stelseldeelnemers de verplicht te gebruiken identificerende gegevens goed
kunnen benutten heeft de werkgroep een aantal ondersteunende functies benoemd.
Dit zijn in elk geval functies voor:
Het opzoeken van sleutels
Specifiek bij persoonsgegevens: het gebruik van pseudoniemen
En mogelijk ook functies voor het wisselen van sleutels, bijvoorbeeld van postcode/huisnummer naar
verblijfsobject-id en vice versa.
De afspraken over de invulling van deze ondersteunende functies moeten nog verder worden uitgewerkt.
Dat geldt ook voor enkele andere zaken die nodig zijn om de kern goed te kunnen toepassen
(bijvoorbeeld over de volledigheid en de kwaliteit van de daarin op te nemen gegevens). Hier gaat
het FDS-project de komende jaren verder mee aan de slag.
24 - Aanbod (metadata)
Registratie van het aanbod binnen het FDS met behulp van DCAT.
Mechanisme
Het aanbod beschrijft de aangeboden datasets en de dataservices die
toegang bieden tot deze datasets. Het aanbod is metadata en wordt
beschikbaar gesteld als linked data volgens de
DCAT standaard.
Hierbij zijn de Linked Data Design Rules
van toepassing.
Elke aanbieder publiceert via self-description zelf een bestand met
het aanbod van betreffende aanbieder. Dit bestand bevat een
DCAT
catalog met van daaruit verwezen alle door de aanbieder aangeboden
datasets en dataservices die voldoen aan de FDS criteria.
Elke deelname-administrateur publiceert een bestand met het volledige
aanbod binnen het FDS. Dit bestand bevat een
DCAT
catalog met van daaruit verwezen alle vanuit deelnemerkenmerken
verwezen DCAT
catalogs van aanbieders.
Indien beschikbaar worden vanuit de door de aanbieder beschreven
datasets en dataservices aanvullende metadata verwezen zoals
kwaliteitskenmerken (op basis van DQV),
begrippen (op basis van
SKOS en
NL-SBB)
en het gehanteerde informatiemodel (op basis van
MIM of
OWL).
Aanbod metadata via DCAT
Voorbeelden
Een voorbeeld van het volledige aanbod vanuit een administrateur
(in Turtle):
@prefix dcat: <http://www.w3.org/ns/dcat#>
@prefix dct: <http://purl.org/dc/terms/>
@prefix fds: <http://fds.example.org/ontology#>
@base <http://admin-a.example.org/fds/dcat/>
<fds-catalog>
dcat:contactPoint 'info@admin-a.example.org' ;
dct:title 'Het FDS aanbod'@nl-nl ;
dct:description 'Het volledige FDS aanbod van alle aanbieders binnen het FDS.'@nl-nl ;
dct:publisher <http://admin-a.example.org/fds/deelnemers/self#deelnemer> ;
dcat:catalog <http://deelnemer-x.example.org/fds/dcat#catalog> ,
<http://deelnemer-z.example.org/fds/dcat#catalog> .
Een voorbeeld van het het aanbod vanuit een aanbieder
(in Turtle):
@prefix dcat: <http://www.w3.org/ns/dcat#>
@prefix dct: <http://purl.org/dc/terms/>
@prefix fds: <http://fds.example.org/ontology#>
@base <http://deelnemer-x.example.org/fds/dcat#>
<catalog>
dcat:contactPoint 'info@deelnemer-x.example.org' ;
dct:title 'Het FDS aanbod van Deelnemer X.'@nl-nl ;
dct:description 'Het aanbod van Deelnemer X binnen het FDS.'@nl-nl ;
dct:publisher <http://admin-a.example.org/fds/deelnemers/organisatie-x#deelnemer> ;
dcat:service <service-a> ,
<service-b> ;
dcat:dataset <dataset-a> .
.... definitie van datasets en dataservices ....
Binnen FDS verwachten we gebruik te gaan maken van
DCAT-AP-NL 3.0. Op
basis van dit generieke applicatieprofiel wordt naar verwachting verder
aangescherpt in een FDS applicatieprofiel in de vorm van een aanvullende
OWL en/of
SHACL
definities.
De identificatie van een deelnemer binnen het FDS.
Identificatie van de deelnemer
Een deelnemer van het FDS heeft een Deelnemer-ID. Een deelnemer-ID kan als URL worden gebruikt om
een linked data (RDF) document op te
halen met Deelnemerkenmerken zoals het KvK-nummer, RSIN en/of OIN.
Het Deelnemer-ID is een LinkedDataURI. Op de deelnemer-ID
zijn de Linked Data Design Rules van toepassing. Zie voor meer informatie over
identiteiten de stelselfunctie Identiteit.
Mogelijk kan het Deelnemer-ID ook als Distributed Identity (DID)
gebruikt worden om uitwisseling als Verifiable Credentials (VC)
mogelijk te maken. In dat geval zou het document met Deelnemerkenmerken ook als
DID Document conform de standaard did-web
kunnen dienen. Dit is echter vooralsnog onvoldoende uitgewerkt om al concreet toe
te kunnen passen. Daarnaast is het nog onzeker of betreffende standaarden
passend zijn voor toepassing binnen FDS.
Registratie van kenmerken van deelnemers aan het FDS.
Mechanisme
De deelnemerkenmerken bestaan uit voor het FDS relevante kenmerken van een deelnemer.
De deelnemerkenmerken worden door de deelname-administrateur geverifieerd en
geregistreerd bij het uitvoeren van de deelnameprocessen. De
deelnemerkenmerken zijn metadata en worden beschikbaar gesteld als linked data. Hierbij zijn
de Linked Data Design Rules van toepassing.
De deelnemerkenmerken
De volgende deelnemerkenmerken worden geregistreerd:
De deelnemer wordt binnen de resource geïdentificeerd op basis van een
Deelnemer-ID.
Van de deelnemerkenmerken wordt een versiehistorie bijgehouden.
De deelnemerkenmerken
De grondslag
De grondslag op basis waarvan de organisatie is toegelaten tot het FDS betreft de
wettelijke taak op grond waarvan de organisatie gegevens kan aanbieden of afnemen
binnen het FDS. Deze grondslag bestaat uit een of meer verwijzingen naar het
BWB.
Betrouwbaarheid
De deelnemerkenmerken worden beschikbaar gesteld door de administrateur die
betreffende deelnemer heeft toegelaten. Dit impliceert dat de ‘hostname’ binnen
het Deelnemer-ID een hostname binnen een domein van deze
administrateur is. Door deelnemerkenmerken beschikbaar te stellen via een
domein van de administrateur verleent de administrateur autoriteit aan de
geleverde deelnemerkenmerken.
Een alternatief model is het door de deelnemer zelf ter beschikking stellen
van de deelnemerkenmerken. Dit vergt echter een bewijs van bijvoorbeeld
een administrateur dat de deelnemerkenmerken zijn geverifieerd. Dit
zou bijvoorbeeld kunnen door het mechanisme van
Verifiable Credentials (VC)
toe te passen, al dan niet in combinatie met een
did-web als
Identificatiemiddel.
In dat geval zouden de deelnemerkenmerken zo opgezet
kunnen worden dat ze de vorm krijgen van DID document zoals
voorgeschreven binnen de did-web
standaard. Dit is echter vooralsnog onvoldoende uitgewerkt om al concreet toe
te kunnen passen. Daarnaast is het nog onzeker of betreffende standaarden
passend zijn voor toepassing binnen FDS.
Voorbeelden
Een voorbeeld van een lijst met deelnemerkenmerken (in
Turtle):
Registratie van de deelnemers door de deelnameadministrateur(s).
Mechanisme
De deelnemerslijst bevat verwijzingen naar alle deelnemers van het FDS. De
deelnemerslijst wordt door de deelname-administrateur bijgehouden bij het
uitvoeren van de deelnameprocessen. De deelnamelijst
is metadata en wordt beschikbaar gesteld als linked data. Hierbij zijn
de Linked Data Design Rules van toepassing.
De deelnemerslijst bestaat uit twee delen:
alle wijzigingen (events) op de deelnemerslijst die hebben plaatsgevonden
de volledige lijst met deelnemers die uit deze wijzigingen voortvloeit
Elke administrateur houdt alle wijzigingen bij die deze administrateur doorvoert
(opname en verwijdering). Vervolgens stelt elke administrateur een resulterende
volledige lijst met deelnemers op gebaseerd op de lijsten met wijzigingen van
alle administrateurs in het stelsel.
Voor beide soorten lijsten wordt een versiehistorie bijgehouden.
Het mechanisme van de deelnemerslijst
Zowel de deelnamekenmerken van de administrateur verwijzen naar zowel de lijst met
deelnamewijzigingen als de deelnemerslijst.
De deelnamewijzigingen
Elke administrateur houdt bij welke deelnemers hij opneemt en verwijderd. Deze
wijzigingen worden toegevoegd aan een nieuwe versie van de lijst met
deelnamewijzigingen.
De allereerste wijziging bestaat uit het zichzelf toevoegen van de eerste
administrateur (bootstrapping). Deze eerste administrateur kan vervolgens
andere administrateurs en deelnemers (aanbieders en afnemers) toevoegen.
De deelnemerslijst
Uit de verschillende lijsten met deelnamewijzigingen van de verschillende
administrateurs wordt vervolgens de lijst met deelnemers samengesteld. De deelnemerslijst bevat verwijzingen naar de (versies) van de lijsten met
deelnamewijzigingen die zijn gebruikt om de deelnemerslijst samen te stellen.
Elke administrateur verzamelt periodiek de laatste versie(s) van de lijsten met
deelnamewijzigingen van alle administrateurs. Indien één van de lijsten
met deelnamewijzigingen is aangepast maakt elke administrateur
een nieuwe versie van de deelnemerslijst aan.
De deelnemerslijst
Welke organisatie(s) binnen het FDS deelnameadministrateur worden en of binnen
het FDS daadwerkelijk gebruik gemaakt gaat worden van meerdere administrateurs
is nog onderwerp van onderzoek.
Voorbeelden
Een voorbeeld van een lijst met deelnamewijzigingen (in
Turtle):
Design Rules voor het hanteren van Linked Data binnen het FDS.
Design Rules
Binnen het FDS wordt linked data gebruikt voor metadata. Voor de primaire data
kan linked data ook gebruikt worden. Linked data is een familie van standaarden
en best practices. Er zijn echter vele interpretatiemogelijkheden en vrijheden
die het effectief gebruik van linked data hinderen. Binnen het FDS hanteren
we daarom een aantal design rules voor het gebruik van Linked Data om de
uitwisseling van linked data binnen het FDS te harmoniseren.
De design rules dienen nog te worden uitgewerkt en betreffen bijvoorbeeld:
Follow your nose: een https-request met als url een object-id levert een
linked data document met betekenisvolle kenmerken van het betreffende
object (inclusief relevante verwijzingen naar andere objecten).
Linked data wordt in minimaal één van de volgende content types
aangeboden:
Indien er meer dan één content type wordt aangeboden, wordt het http
mechanisme voor content negotiation gebruikt om een linked data document te bieden
in een beschikbare gewenste syntax.
Dit houdt in dat in het request de gewenste syntax in de
‘Accept’ header
wordt meegegeven. Bij het retourneren wordt, indien beschikbaar, een
gewenste syntax teruggegeven.
Metadata wordt ontsloten via https.
Eventuele nog te bepalen richtlijnen met betrekking tot versionering
van linked data documenten.
Een object-id bevat https als protocol.
Een object-id bevat een #-tag en een fragment-naam om onderscheid te maken
tussen het aan te wijzen object en het linked data document waarin de triples
van betreffend object zijn opgenomen.
Een object-id bevat een hostname binnen een domein dat eigendom is van
een deelnemer van het FDS.
Een nog te bepalen lijst met standaard prefixes die kunnen worden gebruikt
binnen linked data documenten.
Aandachtspunten
Object-id’s worden gebruikt om entiteiten over organisaties heen te
verwijzen. Het is onwenselijk dat als gevolg van bijvoorbeeld een naamswijziging
van de registratie, de aanbiedende organisatie of het aangewezen object het
object-id zou moeten wijzigen. Bij het definiëren van object-id’s dient
hiermee rekening gehouden te worden. Indien het toch noodzakelijk is om
de object-id’s te wijzigen, kan de overgang worden gefaciliteerd door:
gebruik te maken van owl:sameAs
om aan te geven dat de oude en nieuwe object-id hetzelfde object betreffen.
bij een request op de oude object-id een redirect uit te voeren naar het
nieuwe object-id.
De administratie van de deelnemers aan het FDS als organisatie wordt ondersteund door de
operationele deelnameprocessen:
Toelaten tot het FDS als deelnemer
Wijzigen of corrigeren van deelnemerkenmerken
Beëindigen of intrekken van deelname
De deelnameprocessen borgen de beschikbaarheid van een actuele en vertrouwde lijst van deelnemers.
De uitvoering van de deelnameprocessen is de verantwoordelijkheid van een deelname-administrateur,
een deelfunctie van de stelselfunctie van regisseur.
Wil je deelnemen aan het FDS als organisatie? Lees dan
hier
hoe je kan deelnemen!
Toelaten tot het FDS als deelnemer
Voordat een organisatie de rol van aanbieder of afnemer kan aannemen binnen het FDS,
dient een organisatie deelnemer te worden van het FDS. Om deel te kunnen nemen dient
een organisatie te voldoen aan de deelnamecriteria.
de organisatie onderschrijft de uitgangspunten van het afsprakenstelsel in de
intentieverklaring
en volgt de afspraken die daaruit voortvloeien.
De deelnamecriteria worden getoetst door een deelname-administrateur. Bij toelating
wordt een deelnemer met zijn deelnemerkenmerken opgenomen op de lijst met deelnemers.
De lijst met deelnemers en de deelnemerkenmerken zijn beschikbaar als
Metadata. Zowel aanbieders als afnemers kunnen de
metadata raadplegen om te verifiëren of de andere partij deelnemer is.
Nadat een aanbieder is toegelaten als deelnemer dient de aanbieder het proces te doorlopen
om een dataset als aanbod in te brengen.
Nadat een afnemer is toegelaten kan de afnemer een een verzoek tot datadelen indienen bij
een aanbieder. De aanbieder kan in de deelnemerslijst nagaan of de afnemer een vertrouwde
partij is.
Een aantal aspecten zijn nog onderwerp van onderzoek:
Eventuele aanvullende deelnamecriteria.
Het hanteren van één of van verschillende niveau’s van vertrouwen. Meerdere
niveaus van vertrouwen vergt criteria om een niveau op te baseren. Daarnaast zal een deelname-
administrateur moeten toetsen op deze criteria bij het toelaten van een deelnemer.
Wijzigen, corrigeren, beëindigen en intrekken
Naast het toelaten ondersteunt de deelname-administrateur de processen om deelnemerkenmerken
te wijzigen of corrigeren en om een deelname te kunnen beëindigen of in te trekken.
Afnemers kunnen voor hun taken (sterk) afhankelijk zijn van door een aanbieder in
het stelsel ingebrachte data. Processen die potentieel leiden tot intrekken
en beëindigen van deelname zullen worden afgestemd op deze afhankelijkheid.
De deelname-administrateur
De deelname-administrateur ondersteunt de processen om de deelnemers binnen het FDS te administreren.
De deelname-administrateur is een deelfunctie van de stelselfunctie van regisseur.
De registratie van deelnemers is zodanig opgezet dat het mogelijk is om deelnameprocessen door verschillende
deelname-administrateurs uit te laten voeren. Dit maakt het mogelijk om bijvoorbeeld voor bepaalde sectoren een
sectorspecifieke deelname-administrateur aan te wijzen. Een sectorspecifieke deelname-administrateur
kan beter ingericht zijn om vast te stellen of een organisatie een wettelijke taak heeft binnen betreffende
sector (bijvoorbeeld voor zorg- of onderwijsinstellingen). Of we binnen het FDS daadwerkelijk gebruik
gaan maken van meerdere deelname-administrateurs is nog onderwerp van onderzoek.
30 - Handreiking FDS-datadiensten
Deze handreiking ondersteunt bij het opstellen van gestandaardiseerde dienstenniveaubeschrijvingen voor FDS-datadiensten.
Deze handreiking ondersteunt bij het opstellen van gestandaardiseerde dienstenniveaubeschrijvingen
voor FDS-datadiensten. Deze inhoud is het resultaat van samenwerking met onze omgeving in de
praktijk tijdens de FDS-werkgroep servicekwaliteit, hierbij werkten we samen met deelnemers vanuit
het Kadaster, TNO, Logius en het FDS-projectteam.
Context
Bij het werken conform het principe ‘data bij de bron’ worden data-afnemers voor hun bedrijfsvoering
afhankelijk van de datadiensten van FDS-data-aanbieders. Afnemers zullen daarom willen weten welk
dienstenniveau (service level) zij mogen verwachten zodat ze kunnen inschatten of dat in hun geval
afdoende is. Omdat in dezelfde bedrijfstoepassing veelal datadiensten van verschillende
data-aanbieders worden gecombineerd, is het wenselijk dat data-aanbieders afspreken om hun
dienstenniveau op een uniforme manier te beschrijven. In eerste instantie gaat het daarbij om
standaardisatie van de inhoud van de dienstenniveau beschrijving. Dit bestaat uit een afspraak over
de dienstenniveau aspecten die minimaal moeten worden beschreven, aangevuld met afspraken over de
daarbij te hanteren begrippen. Dat laatste zorgt voor de noodzakelijke ’eenheid van taal’: dat we
binnen het FDS in dienstenniveaubeschrijvingen dezelfde begrippen gebruiken en we daar ook dezelfde
betekenis aan geven. Op een later moment kan deze handreiking worden uitgebreid met afspraken om het
dienstenniveau zelf te gaan standaardiseren door binnen het FDS standaard niveaus (serviceklassen)
te definiëren waarin het FDS data-aanbod kan worden ingedeeld (bijvoorbeeld basis, plus en vitaal).
Uitgangspunten voor het opstellen van een FDS-conforme dienstenniveaubeschrijving
Het beoogd toepassingsdomein van de deze handreiking is het opstellen van
dienstenniveaubeschrijvingen voor FDS-conforme datadiensten bestemd voor tot het FDS toegelaten
data-afnemers. Deze afnemers zijn de organisaties die de aangeboden dienst daadwerkelijk in hun
bedrijfsprocessen gaan toepassen. Deze handreiking is dus niet van toepassing op beschrijvingen
die bedoeld zijn om aan opdrachtgevers/financiers duidelijk te maken wat er geleverd gaat worden.
Uitgangspunt binnen het FDS is dat in de metadata die hoort bij een datadienst er een relatie
wordt gelegd (wordt gelinkt) met het van toepassing zijnde (standaard) dienstenniveau. Het is dus
niet nodig om in de dienstenniveau beschrijving zelf op te nemen op welke diensten deze van
toepassing is.
Zoals de titel aangeeft heeft de beschrijving van het dienstenniveau betrekking op het beschrijven
van kwaliteitsaspecten van de dienstverlening m.b.t. het afnemen van FDS-conforme datadiensten.
Deze beschrijving is aanvullend op algemene FDS-deelnamevoorwaarden (de toetredingseisen) die
gekoppeld zijn aan de rol die een stelseldeelnemer vervult. Deze deelnamevoorwaarden bevatten
stelselbrede afspraken over zaken als de te implementeren standaarden, het toe te passen
beveiligingsniveau en het in te richten kwaliteitsmanagement. Deze elementen hoeven in de
dienstenniveaubeschrijving dus niet (opnieuw) te worden benoemd.
Verplichte inhoud dienstenniveaubeschrijving voor FDS-datadiensten
Hierna worden de minimaal op te nemen onderdelen beschreven. De onderdelen waarbij de exacte
betekenis van belang is, zijn in een tabel opgenomen. Deze tabel bevat de definitie van het
betreffende onderwerp aangevuld met een toelichting en een voorbeeld.
Bereikbaarheid data-aanbieder
Een beschrijving van de kanalen (telefoonnummers, e-mailadressen, url’s webformulieren, url’s
chatbots/digitale assistenten, sociale media etc.) die data-afnemers kunnen gebruiken om met de
data-aanbieder contact op te nemen voor :
Algemene vragen.
Het melden van verstoringen in de dienstverlening.
Het rapporteren van data fouten (terugmeldingen).
Het indienen van klachten.
Actuele informatie over de dienstverlening
Een link naar één of meerdere webpagina’s waar de data-afnemers in elk geval informatie kunnen
vinden over:
Actuele verstoringen.
Gepland onderhoud / geplande onbeschikbaarheid.
Voorgenomen wijzigingen.
Het gerealiseerde dienstenniveau (de beschikbare dienstenniveaurapportage).
Het is de bedoeling om op termijn dit soort informatie te standaardiseren zodat het op FDS-niveau
kan worden gebundeld en data-afnemers eenvoudig kunnen nagaan hoe het stelsel als geheel presteert.
Beschikbaarheid
Onderwerp
Toelichting
Niveau
Openingstijd Tijdvenster waarbinnen de dienst kan worden afgenomen
Bijvoorbeeld 7*24 uur
Servicetijd Tijdvenster waarbinnen gebruikersondersteuning wordt aangeboden en het functioneren van de dienst actief wordt bewaakt
Buiten de servicetijd is sprake van passieve bewaking, d.w.z. alleen automatisch herstel verstoringen (voor zover mogelijk).
Bijvoorbeeld Ma-Vr 7.00-18.00
Onderhoudsvenster Tijdvenster dat beschikbaar is voor het uitvoeren van onderhoud dat kan leiden tot tijdelijke onbeschikbaarheid van de dienst
Van tevoren aangekondigde inperking van de openingstijd.
Organisaties kunnen vaste onderhoudsvensters hanteren, maar het is vaak praktischer om onderhoud in te plannen zodra dat nodig is. Afnemers kunnen dan toch zekerheid krijgen door af te spreken dat het minimaal x dagen van tevoren wordt aangekondigd.
Bijvoorbeeld: Elke 2e zaterdag van de maand van 9.00 uur tot 23.00 uur
Geplande onbeschikbaarheid (gebruik van het onderhoudsvenster) wordt uitgevoerd buiten de servicetijd en minimaal 10 werkdagen van tevoren aangekondigd.
Beschikbaarheid Tijd dat de dienst binnen de servicetijd kon worden afgenomen als percentage van de totale openingstijd binnen een kalendermaand.
Gemeten op het aanbiedingspunt van de datadienst en exclusief gepland onderhoud binnen het onderhoudsvenster.
Bijvoorbeeld: 95%
Robuustheid: maximale uitvalduur
Maximum totaal aantal minuten per kalendermaand dat de dienst gedurende de servicetijd onbeschikbaar mag zijn.
Bijvoorbeeld: 360 minuten
Robuustheid: maximaal aantal langdurige verstoringen
Maximaal aantal verstoringen per kalendermaand met meer dan X aangesloten minuten onbeschikbaarheid binnen de servicetijd
Bijvoorbeeld maximaal 2 verstoringen van meer dan 60 minuten
Versie- en wijzigingsbeheer
Het versiebeheer en het daarmee verbonden wijzigingsbeheer moeten ervoor zorgen dat afnemers
zekerheid krijgen over de impact van gewijzigde datadiensten op hun eigen IT-diensten en de tijd die
voor hen beschikbaar is om deze impact te verwerken. In de dienstenniveaubeschrijving moet worden
aangegeven of op de aangeboden dienst wel of geen formeel proces van toepassing is voor het
introduceren van gewijzigde versies van de aangeboden datadienst en wat daarvan de belangrijkste
kenmerken zijn. Hierbij moet onder andere gespecificeerd worden hoe ‘versioning’ wordt ingevuld en
hoeveel (majeure) versies er gelijktijdig worden ondersteund. Voor API-gebaseerde datadiensten moet
daarbij van onderstaande standaard voor versienummering worden uitgegaan:
Toepassing van dit model conform de Nederlandse API
Strategie is een
minimumvereiste om bij dit onderdeel een ‘ja’ te mogen invullen. Het model voorziet in
standaardisatie van de opbouw van het versienummer dat de afnemer inzicht geeft in de impact van de
wijziging en stelt aanvullende eisen aan het versiebeheer zoals het publiceren van een ‘change log’.
Optionele onderdelen
Dit zijn onderwerpen die in de dienstenniveaubeschrijving wel moeten worden benoemd, maar waarop FDS
data-aanbieders geen actief beheer hoeven te voeren. Er hoeft alleen te worden aangegeven of er wel
of niet sprake is van een gegarandeerd niveau. Oftewel of er sprake is van meer dan een
inspanningsverplichting (‘best effort’). Aan de claim van een gegarandeerd niveau worden soms wel
voorwaarden gesteld, maar het staat de organisatie verder vrij om dit niveau naar eigen inzicht te
beschrijven. Hier is voor gekozen omdat organisaties dit zo verschillend invullen dat
standaardisatie niet mogelijk is.
Performance- en capaciteitsbeheer
Het performancebeheer moet er voor zorgen dat de afnemers van een stabiele performance ervaren. In
de dienstenniveaubeschrijving moet worden gespecificeerd of de afnemers een gegarandeerde
performance kan worden geboden. Bij een positief antwoord is het belangrijk dat het voor de afnemer
duidelijk is wat het referentiepunt is (waar wordt er gemeten?) en of er randvoorwaarden gelden
zoals een maximale capaciteitsvraag. Verder is het van belang om te specificeren of er bij het
toekennen van capaciteit en het borgen van de performance prioritaire afnemers kunnen worden
onderkend. Dit is van belang voor afnemers die op dit gebied zekerheid zoeken, zoals de meldkamers
van politie en hulpdiensten.
Calamiteitenbeheer
Een beschrijving van eventuele specifieke voorzieningen die zijn getroffen om de gevolgen van
calamiteiten op te vangen. Een calamiteit wordt hierbij gedefinieerd als een zeldzaam voortkomende
gebeurtenis die kan leiden tot een omvangrijke en langdurige verstoring van de dienstverlening van
de data-aanbieder en waarvan niet van tevoren te voorspellen is of en wanneer deze gebeurtenis zich
zal voordoen. Van oorsprong waren het fysieke ‘rampen’ (in het Engels ‘acts of God’) zoals het
afbranden en overstromen van het rekencentrum met ‘uitwijk’ als maatregel, maar tegenwoordig kunnen
ook bepaalde succesvolle cyberaanvallen, zoals een ransomware attack, als een calamiteit worden
beschouwd.
In de dienstenniveaubeschrijving moet worden aangegeven of voor de aangeboden dienst wel of geen
maatregelen zijn getroffen om de gevolgen van calamiteiten op te vangen. Bij een positief antwoord
moet in de dienstbeschrijving worden toegelicht welk niveau er wordt geboden. Bijvoorbeeld wat de
maximale uitvalduur is, wat het maximale dataverlies is en wat na een calamiteit nog de maximaal
beschikbare capaciteit is. Om te kunnen claimen dat in calamiteitenbeheer is voorzien moet de
dienstaanbieder in elk geval een functionerende ‘consignatiedienst’ hebben ingericht.
Consignatiedienst (synoniem ‘piketdienst’ of ‘crisisdienst’)
Een permanent ingericht geheel van organisatorische en technische maatregelen om ook buiten de servicetijd te kunnen constateren dat er (waarschijnlijk) een calamiteit is opgetreden en direct de van toepassing zijnde beheerprocedure te kunnen starten.
De invulling is vrij. Organisaties kunnen bijvoorbeeld een specifieke IT-consignatiedienst instellen, maar kunnen ook een algemene bereikbaarheidsdienst voor noodgevallen instellen.
31 - Data bij de bron
Gebruik van transparante en actuele gegevens
De zin ‘data bij de bron’ is veelgebruikt en kent meerdere betekenissen. Op deze pagina wordt de
uitwerking van wat data bij de bron betekent voor het Federatief Datastelsel telkens concreter
uitgewerkt én worden de relaties naar andere betekenissen onderhouden. Zo wordt en blijft hopelijk
duidelijk wat er allemaal te zeggen valt over data bij de bron.
In het kort
Data bij de bron betekent in het kort dat data opgehaald wordt bij een bron.
Opgehaald duidt op het gebruik van API’s, Application Programming Interfaces. Afnemers hebben
zelf geen kopie van de data van anderen die zij nodig hebben. In plaats daarvan wordt de data
opgehaald op het moment dat die data nodig is. En die data wordt ook niet langer bewaard dan voor
het gebruik nodig is. Dat betekent dus dat er geen kopieën van datasets meer nodig zijn.
Een of de bron duidt op de plek waar de data vandaan opgehaald wordt. Voor het Federatief
Datastelsel is dat de Aanbieder. Dat hoeft echter niet dezelfde te zijn als de ‘Bronhouder’, ‘data
eigenaar’ of ‘inhoudelijk verantwoordelijke’. Per registratie of datasets kunnen hier specifieke
(sector/domein)afspraken over bestaan. Ook de wet stelt in sommige gevallen welke gegevens door
welke organisatie (verantwoordelijk) gebruikt dienen te worden; dit worden authentieke gegevens
genoemd. Van belang is dat in ieder geval bekend en bij voorkeur ook traceerbaar moet zijn van
welke bron gegevens afkomstig zijn.
Zowel over opgehaald als data zelf als over de bron zijn veel meer afwegingen te maken. Maar
bovenstaande is in het kort de richting voor het Federatief Datastelsel.
Bronnen in het FDS
Er bestaan verschillende definities van ‘bron’ binnen de overheid. Voor het Federatief Datastelsel
zijn daar afwegingen te maken:
“de plaats of organisatie waar bepaalde informatie is ontstaan en/of beschikbaar wordt gesteld,
of de documenten waarin die informatie is vervat”.
Belangrijk element in deze definitie is dat de ‘bron’ zowel de plaats van ontstaan als de plaats
van beschikbaarstelling kan zijn. In het kader van een datastelsel is dat relevant, want in een
stelsel kunnen dit verschillende partijen zijn. Volgens de NORA-definitie kunnen elk van die
partijen claimen ‘de bron’ te zijn binnen zo’n stelsel.
Voorbeeld van BGT
Dit is bijvoorbeeld het geval binnen het huidige stelsel van basisregistraties. Zo staat in artikel
23 van de wet basisregistratie grootschalige topografie (BGT):
“Indien een bestuursorgaan bij de vervulling van zijn publiekrechtelijke taak een gegeven nodig
heeft dat krachtens deze wet als authentiek gegeven in de basisregistratie grootschalige
topografie beschikbaar is, gebruikt het dat authentiek gegeven”.
In artikel 2 van die wet staat:
“De basisregistratie grootschalige topografie wordt gehouden door de Dienst”.
Hieruit zou kunnen worden afgeleid dat met het gebruik van de door deze Dienst (het Kadaster)
beschikbaar gestelde BGT-data conform ‘data bij de bron’ wordt gewerkt. Met andere woorden: de
Landelijke Voorziening is dé bron.
In diezelfde wet is echter in artikel 10 aan allerlei andere overheidsorganisaties de status van
‘bronhouder’ toegekend, waarbij deze bronhouder volgens artikel 11 zorgt draagt:
“voor het bijhouden van de geografische gegevens in de basisregistratie grootschalige topografie
door levering van de gegevens, bedoeld in de artikelen 7, tweede en derde lid, en 8 aan de
Dienst”.
Gebruik van de term ’levering’ geeft aan dat de BGT-data afkomstig is uit andere registraties, dus
dat het hier in feite kopiedata betreft. Het juist toepassen van het werken volgens ‘data bij de
bron’ zou dus ook zo geïnterpreteerd kunnen worden dat niet de LV-BGT, maar de door deze partijen
bijgehouden bronregistraties moeten worden gebruikt. Dit is immers de plaats waar het gegeven voor
de eerste keer is vastgelegd. Met andere woorden: de bronhouders zijn dé bron.
Ook andere registraties kennen dit soort toeleveringsketens. Soms kan zelfs verdedigd worden dat
burgers en bedrijven de eigenlijke bronnen zijn en dat toepassen van ‘data bij de bron’ dus inhoudt
dat zij altijd zélf bepaalde gegevens moeten gaan verstrekken. Dat laatste staat dan weer op
gespannen voet met een ander richtinggevend principe binnen het huidige stelsel van
basisregistraties, namelijk eenmalige uitvraag en meervoudig gebruik (het niet vragen naar de
bekende weg).
Als het gaat om het ‘ontstaan’ of inwinnen van data geldt ook nog dat een inwinnende
(overheids)organisatie veelal enige vorm van validatie toepast, zodat enige vorm van zekerheid kan
worden ontleend aan het door de overheidsorganisatie ingewonnen gegeven. Er is bijvoorbeeld een
bewijsstuk overlegd, welke is gecontroleerd door een ambtenaar. Of het betreft een eigen verklaring
van de betrokkene, maar de ambtenaar heeft wel de identiteit van de betrokkene gevalideerd.
Daarnaast zijn er gegevens die niet (extern) worden ingewonnen, maar ontstaan bij
overheidsorganisaties, bv gegevens mbt de besluiten die organisaties nemen. Zie ook
Concept data-ecosysteem Nederlandse overheid.
Digitale Overheid
In de definitie van data bij de bron op
digitaleoverheid.nl wordt op een andere manier
naar ‘bron’ gekeken:
“Data bij de bron houdt in dat gegevens van burgers en bedrijven alleen in bronsystemen zoals de
basisregistraties worden geregistreerd, en niet gekopieerd of verstuurd. Zo zorgen we ervoor dat
de overheid altijd transparante en actuele gegevens gebruikt.”
In deze definitie wordt de bron (het bronsysteem) niet gedefinieerd, maar wordt alleen een voorbeeld
gegeven en verder de nadruk gelegd op het doel (transparant en actueel) en wat dit in de weg staat
(het kopiëren of versturen van gegevens).
Federatief Datastelsel
Binnen het Federatief Datastelsel (FDS) wordt eveneens een pragmatische aanpak voor het bepalen van
bronnen gevolgd. Het FDS hanteert daarvoor geen algemene definitie, maar vereist voor elke in het
FDS opgenomen dataset en datadienst stelselconforme metadata. Op grond van deze context kan de
data-afnemer zelf eenvoudig kan vaststellen of en in welke context, deze als ‘bron’ kan of moet
worden beschouwd. Daarbij geldt binnen het FDS de afspraak dat er alleen sprake is van verplicht
gebruik van een bron als in deze metadata naar een verifieerbare grondslag wordt verwezen. Dat kan
een bestuurlijke afspraak zijn die alleen bepaalde partijen bindt, maar het kan ook een wet zijn die
alle partijen in een sector verplicht, of zelfs de gehele overheid. Zo bevatten de wetten van de
huidige basisregistraties voor bepaalde ‘authentieke data’ een gebruiksverplichting voor alle
organisaties die een publiekrechtelijke taak uitvoeren waarbij de betreffende data een rol speelt.
De voorlopige richting van het FDS is dat het domein kiest wat moet worden beschouwd als ‘de bron’.
Daarbij draagt het FDS bij aan het ondersteunen van een grote gemene deler om, in het belang van
zowel afnemer en aanbieder, eisen en bijbehorende oplossing(srichtingen) in ieder geval voor een
deel te harmoniseren/standaardiseren.
In het FDS is ‘de bron’ wel altijd een expliciete keuze die gemaakt is binnen de governancestructuur
van het domein waar deze bron betrekking op heeft. Bij deze keuze staat het belang van de
data-afnemer centraal. Deze benadering betekent dat de implementatie in de tijd ook kan wijzigen. Zo
is het mogelijk dat er vanuit het oogpunt van gebruiksgemak of efficiency ervoor wordt gekozen om
data die door verschillende partijen wordt bijgehouden, in een centrale registratie of landelijke
voorziening te bundelen en deze vervolgens juridisch als ‘bron’ te bestempelen. Maar het is ook
mogelijk dat veranderingen in technologie het mogelijk maken om te ‘ontbundelen’ en data als een
voor de data-afnemers logisch geheel te presenteren terwijl deze fysiek bij verschillende partijen
staat. In de beschreven context in de metadata dient dit duidelijk te zijn voor elke dataset in het
FDS. Belangrijk daarbij is dat dubbelingen worden vermeden. Er kan binnen het FDS geen aanbod zijn
van dezelfde data met hetzelfde toepassingsbereik/zelfde gebruikscontext. Voor FDS-afnemers moet
altijd duidelijk zijn wat de ‘bron van de waarheid’ is en dat is er altijd maar één.
Betrouwbare bronnen
Bij het gebruik van bronnen door een afnemer is het ook van belang wat een afnemer met die
brondata doet. Over dat gebruik dient de afnemer verantwoording af te kunnen leggen. Over het
algemeen zal dat gebruik een structureel karakter hebben en dan spelen er ook nog andere zaken een
rol bij het gebruik. Niet alleen de verantwoording van dat gebruik op een bepaald moment, maar ook
de traceerbaarheid, de uitlegbaarheid en de herhaalbaarheid daarvan. Dat stelt ook eisen aan
bronnen. Om betrouwbaar gebruik te kunnen maken van bronnen, zullen deze bronnen capabilities
moeten hebben om aan die eisen te kunnen voldoen. Welke capabilities dat precies zijn, staat nog
niet vast. Gedacht kan worden aan historische bevragingen, herstel en correctie ook terug in de
tijd, gegevens die ‘in onderzoek’ zijn oftewel die niet per se als waar gekenmerkt kunnen worden.
Deze capabilities dragen allemaal aan de hiervoor genoemde eisen.
In het FDS is er (dus) vrijheid voor domeinen om te kiezen wat ‘de bronnen’ zijn. De eisen aan al
die bronnen zullen wel generiek zijn. Welke capabilities betrouwbare bronnen precies moeten hebben
en hoe deze te realiseren zijn, wordt onderzocht in het project Uit betrouwbare bron.
Overig gebruik van Data bij de Bron
Zoals hierboven al eerder is benoemd, wordt ‘data bij de bron’ veelvuldig gebruikt en met
verschillende ’lading’. Hieronder een opsomming en enige overwegingen hoe deze ’lading’ zich
verhoudt tot het FDS.
Door de digitale overheid
Data bij de bron is niet ondubbelzinnig duidelijk. Data bij de
Bron wordt als uitgangspunt genoemd bij de
Digitale Overheid:
Data bij de bron is een belangrijk uitgangspunt voor de digitale transformatie van de Nederlandse
overheid. Data hoort zo veel mogelijk op één logische plek te staan, bij de eigenaar van die
gegevens.
Eén logische plek is echter niet zo logisch als een basisregistratie een verzameling is van de
‘stukjes’ basisregistratie die bij meerdere bronhouders liggen. Dat is namelijk niet één plek. Dat
is wél de eigenaar. Maar wat is er nu belangrijker bij dit uitgangspunt: ‘één logische plek’ of ‘bij
de eigenaar van die gegevens’?
Om hier een uitweg in te vinden, worden extra oplossingen ingebracht zoals Landelijke Voorzieningen.
Op zichzelf zijn deze ook nuttig en van toegevoegde waarde, maar in het kader van data bij de bron
zijn deze ingewikkeld.
Wat is nu de bron?
Wat is eigenaarschap in dit uitgangspunt?
De oorspronkelijke bronhouder? Die is in ieder geval niet ontslagen van haar verantwoordelijkheid op
de juistheid van de data
Al deze principes zijn erop gericht om duidelijkheid en begrip te kunnen verschaffen aan personen en
bedrijven daar waar het over hen gaat. Daarvoor is het noodzakelijk om te weten waar welke data is
en wordt gebruikt, zeker in geval van persoonsgegevens.
FDS overwegingen
Draagt bij aan het FDS, omdat het aandacht vraagt voor verantwoord datagebruik
Draagt bij aan het FDS, omdat het (indirect) vraagt naar begrip en oorsprong van data, maar
maakt dat niet expliciet. Het stelt meer een voorwaarden aan de capabilities van betrouwbare
bronnen
Draagt niet bij aan het FDS, omdat het gericht is op regie vanuit de burger en dat is niet de
scope van FDS (voor dit moment)
“Maak bij de dienst gebruik van gegevens die afkomstig zijn uit een bronregistratie.”
Voor betrouwbare dienstverlening is het hergebruik van de juiste informatie en documenten van
cruciaal belang. Om de kwaliteit over de juistheid van een gegeven te borgen, moet duidelijk zijn
welke organisatie bepaalt wat de juiste informatie is. Uitgangspunt is dat er voor gegevens waar
de overheid gebruik van maakt, altijd één bron bestaat, die leidend is.
Wat een ‘bronregistratie’ is, wordt hierboven al beschreven bij Bronnen in het FDS | NORA.
Dat betreft (dus) de plaats of organisatie waar de informatie ontstaat en/of beschikbaar wordt gesteld.
Draagt bij aan het FDS, als ‘informeer bij de bron’ uitgelegd wordt als ‘maak gebruik van API’s’
Draagt bij aan het FDS, omdat het hergebruik van gegevens bevordert
Draagt niet bij aan het FDS, omdat het onduidelijkheid over laat over wat nu een bron precies moet zijn
…
Basis Data Infrastructuur (in logistiek)
De Basis Data Infrastructuur (BDI) is het afsprakenstelsel waarmee je volledig digitaal en geautomatiseerd zaken doet in de logistiek. Op een efficiënte, veilige en vertrouwde manier. Zo zorgen we voor optimaal goederenvervoer. In Nederland en internationaal.
“Als data-eigenaar bepaal je zelf wie er toegang heeft tot welke gegevens via de BDI, en onder welke voorwaarden. Dit noemen we ook wel ‘gegevenssoevereiniteit’. Zo hou je als bron volledige controle over de toegang tot data”
Voor de BDI geldt dat zij dit principe verbinden met authenticatie en autorisatie:
“Het gevolg van deze ‘data bij de bron’-aanpak, is dat er een min of meer gemeenschappelijk identificatie-, authenticatie-, vertrouwensbeoordelings- en autorisatiemechanisme nodig is. Dit mechanisme moet naadloos integreren met een “Zero Trust” API of interface, wil je veilige en gecontroleerde gegevensuitwisselingen waarborgen. De BDI biedt zo’n mechanisme.”
FDS overwegingen
Draagt bij aan het FDS, als in een vergelijkbaar principe in ‘data bij de bron’
Draagt bij aan het FDS, omdat het hergebruik van gegevens bevordert
Draagt niet bij aan het FDS, omdat het specifiek logistiek betreft
Draagt niet bij aan FDS, omdat de mechanismen te weinig gestandaardiseerd zijn
32 - Lock-Unlock
Onderzoek van Kadaster DataScience Team over autorisatie in en als Linked Data
Dit is de samenvatting van en perspectief vanuit het federatief datastelsel op het onderzoeksproject
Lock-Unlock. Deze samenvatting geeft een globaal beeld van de resultaten van het onderzoeksproject
en ligt de focus op de voor het FDS belangrijkste uitkomsten. Er is daarbij geprobeerd vakjargon te
vermijden. Het Lock-Unlock project heeft echter veel meer opgeleverd dan wat in deze
FDS-samenvatting aan bod komt. De hiernavolgende hoofdstukken bevatten de volledige
onderzoeksresultaten, met gebruik van de juiste vaktechnische termen.
In het Federatief Datastelsel (FDS) worden generieke functies ingericht met afspraken en standaarden
waarmee data eenvoudig in samenhang kan worden gedeeld tussen organisaties uit verschillende
sectoren. Linked Data standaarden zijn speciaal ontworpen om data in samenhang te ontsluiten. Daarin
zijn de Linked Data standaarden met name gericht op open data. Voor afgeschermde data zijn er geen
aangenomen standaarden en is er weinig onderzoek gaande. In het Lock-Unlock project heeft het Data
Science Team van het Kadaster onderzocht welke mogelijkheden er zijn om in deze lacune te voorzien,
zodat in het FDS ook afgeschermde Linked Data kan worden toegepast. Hiervoor is desk research
uitgevoerd en zijn de gevonden mogelijke oplossingen in de praktijk beproefd door een werkende
‘demonstrator’ te realiseren. Daarbij is voortgebouwd op het project
Integrale Gebruiksoplossing (IGO)
waarmee in 2021 voor open data al de toegevoegde waarde van het toepassen van Linked Data is verkend.
In het Lock-Unlock project is tevens aandacht besteed aan het met Linked Data implementeren van wat
in de visie van het FDS bekend staat als ‘
informatiekundige kern’
, het toepassen van identificerende gegevens (‘unieke sleutels’) om betrouwbaar data die betrekking
hebben op Wie (personen en organisaties) en Waar (locatie) te combineren.
Noodzakelijke afscherming
Bij een federatieve bevraging zijn diverse vormen van afscherming van belang. Autorisatie
oplossingen zouden de volgende afschermingspatronen moeten ondersteunen:
Verticale subsets (de ‘kolommen’ in een tabel): bepaalde kenmerken/attributen van de daarin
voorkomende objecten zijn afgeschermd. Voorbeeld: in een dataset met gegevens over kadastrale
percelen mag je van percelen wel de koopsom opvragen, maar niet de eigenaar.
Horizontale subsets (de ‘rijen’ in een tabel): bepaalde objecten (voorkomens) zijn afgeschermd,
maar van de objecten waar je wel toegang toe hebt, mag je alle beschikbare kenmerken/attributen
opvragen. Voorbeeld: je krijgt als Gemeente X wel alle perceelgegevens, maar alleen van die
percelen die binnen jouw gemeente liggen.
Afscherming relatie-richting: het opvragen van informatie in een bepaalde richting is mogelijk,
maar het opvragen van de omgekeerde richting is niet mogelijk. Voorbeeld: je mag van een perceel
de naam van de eigenaar opvragen, maar je mag niet op basis van de naam van een eigenaar opvragen
welke percelen deze allemaal bezit.
Aggregatie: gebruikers mogen geen toegang krijgen tot de gedetailleerde gegevens, maar mogen wel
geaggregeerde gegevens opvragen. Voorbeeld: niet de verkoopprijzen van een individueel perceel,
maar wel de gemiddelde verkoopprijs binnen een postcodegebied.
Vrije query mogelijkheden ondersteunen: de kracht van Linked Data is dat je zonder een vooraf
gedefinieerd inrichtingsschema de data kunt bevragen. Die optie van makkelijk ‘vrij’ door de data
kunnen zoeken, wil je blijven behouden.
De onderzochte oplossing: het toepassen van een Linked Data ‘autorisatietaal’
In het project is voor de verschillende manieren van afschermen een autorisatietaal ontwikkeld
waarmee op een gestandaardiseerde wijze de te implementeren autorisatie kan worden beschreven. Deze
beschrijving is eveneens machineleesbaar en voldoet aan de Linked Data standaarden. De in deze taal
opgeschreven autorisatieregels vormen daarmee zelf ook een Linked Data set die op de Linked Data
manier kan worden bevraagd. Vervolgens is ook beproefd of autorisaties op basis van deze
autorisatieregels daadwerkelijk afgedwongen zou kunnen worden. Werkt het ook echt?
Het is een innovatieve manier van het vastleggen van autorisaties die tot nu toe in de Linked Data
wereld niet bestond en die de potentie heeft om tot een toekomstige standaard uit te groeien.
Conclusies op basis van de uitgevoerde praktijkproef
Voor de ontwikkelde autorisatietaal is een praktijkproef (‘proof of concept’) uitgevoerd waarbij
deze taal in een lab-omgeving is toegepast om de hiervoor genoemde vormen van afscherming te
realiseren. Er zijn twee implementaties gemaakt die verschillende strategieën beproeven in het
toepassen van de autorisatieregels. Uiteraard gebruiken beiden dezelfde autorisatieregels in de
ontwikkelde autorisatietaal. In de lab-omgeving zijn daartoe met zelf gegenereerde (synthetische)
testdata en relevante onderdelen van de informatiekundige kern, het FDS gesimuleerd met een
federatieve bevraging over meerdere basisregistraties. Er is gekozen voor een testopstelling van de
basisregistraties BRK, de BRP, de BAG en het HR, aangevuld met een dataset die nog niet in het
stelsel is opgenomen, de ‘ANBI’ dataset van de Belastingdienst met gegevens over algemeen nut
beogende instellingen.
Vereenvoudigd Informatie Model als Linked Data (bron)
Op basis van deze praktijkproef kunnen de volgende conclusies worden getrokken:
De bedachte oplossing is uitvoerbaar. Het is in de praktijk mogelijk om (geavanceerde)
autorisatieregels vast te leggen in Linked Data met behulp van een autorisatietaal die aansluit op
al bestaande Linked Data concepten.
Met deze autorisatietaal en de twee implementatiestrategieën kunnen de horizontale en verticale
subsets afscherming gerealiseerd worden. (Voor het afschermen van de richting was te weinig tijd
beschikbaar.)
Als de gegevenscatalogus van een dataset volgens linked data standaarden is opgebouwd, kan deze
gebruikt worden om in de autorisatietaal de autorisatieregels te beschrijven direct gekoppeld aan
de elementen van de dataset(beschrijving) zelf.
Er zijn meerdere implementatie strategieën mogelijk die gebruik maken van de autorisatietaal om de
autorisatieregels af te dingen. Bij het onderzoek zijn er twee strategieën uitgewerkt en
geïmplementeerd. De verschillende strategieën hebben verschillende voor- en nadelen.
Ook in Linked Data is een goed gebruik van identificerende sleutels van belang om betrouwbare
relaties tussen data uit verschillende datasets te kunnen leggen. Door van de betreffende data
Linked Data te maken, is het toepassen van het concept van de informatiekundige kern wel veel
eenvoudiger. Zo heeft de proef aangetoond dat speciale diensten voor ‘sleutelwisselingen’
(bijvoorbeeld van KvK-nr naar RSIN) niet nodig zijn omdat het Linked Data concept hiervoor
standaard oplossingen biedt.
Bij de eerdere IGO-proef is al gedemonstreerd, dat het op de Linked Data manier ontsluiten het ook
voor niet professionele gebruikers mogelijk maakt om heel flexibele de data ‘te bevragen’. Hiermee
is het een goede aanvulling op de standaard (REST) API manier om data te ontsluiten, omdat daarbij
de vragen van tevoren gedefinieerd moeten zijn (ze zijn voorgeprogrammeerd). Met Lock-Unlock is
aangetoond dat de data-aanbieder de door Linked Data geboden flexibiliteit, ook kan inperken,
waardoor deze methode ook voor gesloten data kan worden toegepast.
Binnen de tijd die voor Lock-Unlock beschikbaar was, kon maar een
beperkte diepgang worden bereikt en was het ook niet mogelijk om na te gaan hoe de onderzochte
Linked Data manier past binnen de overige mogelijke FDS-standaarden. Voor de volgende onderwerpen is
daarom nader onderzoek gewenst:
Het is ook bij Linked Data mogelijk om het bevragen van de data gedetailleerd te loggen en de
logbestanden vervolgens voor analyse te gebruiken. Bijvoorbeeld om achteraf vast te stellen of een
bepaalde vraag wel legitiem was. Hoe deze manier van loggen zich verhoudt tot de beoogde manier om
in het FDS de verwerking van data te registreren (op basis van de ‘verwerkingenlogging standaard),
moet nader worden onderzocht.
Hetzelfde geldt voor de relatie tussen in Lock-Unlock ontwikkelde Linked Data autorisatietaal en
andere manieren om ‘policy based acces control’ te implementeren.
Er was geen tijd meer beschikbaar om de afscherming op relatie – richting te beproeven. Het is
wenselijk om hiervoor een vervolgonderzoek uit te voeren.
Hoewel voor de wel onderzochte afschermingspatronen de benodigde toegangsbeperking werd geboden,
is diepgaander onderzoek nodig om met meer zekerheid vast te stellen dat dit niet omzeild kan
worden. Dit is lastig te meten en ook daarvoor is meer onderzoek nodig. • De oplossingen zijn in
lab-condities beproefd op kleine test datasets. Aspecten die van belang zijn bij grootschalige
toepassing, zoals performance, vielen buiten de scope van het onderzoek. Hoewel er geen indicaties
zijn dat opschaling niet mogelijk is, zijn verdere beproevingen in een daarvoor geoptimaliseerde
proefomgeving nodig om ook hierover meer zekerheid te krijgen. Dit heeft vooral impact en relatie
tot performance van federatieve bevragingen én daar bovenop de toevoeging van de autorisaties
daarin en daarvan.
Het heeft voordelen om de relaties waaruit de informatiekundige kern is opgebouwd met behulp van
Linked Data te verduurzamen (als een ‘upper ontology’ in Linked Data vaktaal). Het lijkt de moeite
waard om de kosten en baten hiervan verder te verkennen.
De FSC-standaard uniformeert de wijze waarop koppelingen worden gerealiseerd, waardoor deze
beheersbaar, veilig en betrouwbaar zijn. Het maakt ze eenvoudiger beheersbaar, doordat ze eenvoudig
en snel kunnen worden gerealiseerd, gewijzigd, gecontroleerd of opgeheven. Daarnaast worden
aanvullende waarborgen gerealiseerd voor de veiligheid en betrouwbaarheid van data. Denk aan het
automatiseren van controles op basis van beleids- en toegangsregels, gebaseerd op transparantie
zodat ook achteraf helder is waarom bepaalde gegevens gebruikt zijn en bepaalde beslissingen genomen
zijn. Zo speelt de FSC-standaard een cruciale rol in het realiseren van een betaalbare, beheersbare,
veilige en betrouwbare gegevensuitwisseling in de komende jaren.
Veilige uitwisseling van gegevens
Het systeem moet garanderen dat gegevens veilig worden overgedragen en opgeslagen, met gebruik van
versleuteling, authenticatie en autorisatie, zodat de vertrouwelijkheid en integriteit van gegevens
beschermd zijn.
FSC beschrijft hoe de identiteit van een organisatie betrouwbaar kan worden vastgesteld en hoe een
organisatie op een transparante manier namens een andere organisatie kan handelen. Elke organisatie
werkt onder haar eigen identiteit. Dit maakt het voor een organisatie vele malen eenvoudiger om te
voldoen aan wetgeving als AVG. Het is de basis van een veilig vertrouwensstelsel waarin
onomstootbaar vaststaat wie, wat, wanneer en waarom uitgewisseld heeft. De identiteit wordt gebruikt
bij het ondertekenen van een FSC contract en vervolgens bij de daadwerkelijke gegevensuitwisseling
op basis van dat contract.
Decentrale samenwerking
In plaats van afhankelijk te zijn van één centraal systeem, kunnen organisaties direct met elkaar
communiceren. Dit maakt het mogelijk om snel en flexibel samen te werken, terwijl de
verantwoordelijkheid voor de gegevens lokaal blijft.
FSC is federatief by design en heeft geen centrale autoriteit of systeem nodig om koppelingen tussen
organisaties te leggen en gegevens uit te wisselen. Iedere organisatie is daardoor alleen
verantwoordelijk voor zichzelf. Dit maakt het stelsel robuust want er is geen centrale kwetsbaarheid
die bij calamiteiten het hele stelsel lam legt. Het maakt het stelsel schaalbaar, want er is niet
één centrale hub die een bottleneck kan vormen. Centrale stelselfuncties kunnen indien wenselijk
boven op FSC geplaatst worden. Hierbij kan bijvoorbeeld gedacht worden aan een centrale
ledenadministratie die gebruikt wordt als drempel bij het vastleggen van afspraken in een FSC
contract en het uitwisselen van data.
Beheersbaar door uniforme standaarden
Het systeem moet gebruik maken van gestandaardiseerde protocollen en systemen en er zo voor zorgen
dat elke organisatie op dezelfde manier data kan delen en ontvangen. Hierdoor kunnen systemen van
verschillende organisaties naadloos samenwerken.
De FSC standaard beschrijft hoe interne en externe koppelingen tussen afnemers en aanbieders
georganiseerd kunnen worden. FSC standaardiseert het tot stand brengen, beheren en gebruiken van
koppelingen, waardoor deze processen geautomatiseerd kunnen worden. Dit zorgt voor een efficiënte
werkwijze die de explosieve groei van het aantal API koppelingen, mede onder invloed van het ‘data
bij de bron’ principe, helpt beheersbaar te maken.
Synergie met andere standaarden
Door de standaardisatie van koppelingen tussen organisaties biedt FSC een solide basis voor andere
standaarden die nodig zijn voor het organiseren van vertrouwd datagebruik. Door bijvoorbeeld de
transactie logging van FSC te koppelen aan de inhoudelijke logging van een applicatie, worden
audits aanzienlijk eenvoudiger en effectiever. Dit kan bijvoorbeeld door de FSC standaard te
combineren met de standaard Logboek dataverwerkingen.
Een ander voorbeeld is het federatief organiseren van de toegangscontrole waardoor de beslissing
om data op te vragen of uit te leveren op de juiste plek belegd kan worden. Deze
uitwisselingsstandaarden kunnen gebruik maken van wat FSC al biedt.
Deze uitwisselingsstandaarden zijn bewust gescheiden van elkaar zodat iedere standaard zich kan
richten op 1 aspect van het verantwoord gegevensdelen. Dit maakt het geheel van standaarden
flexibeler en organisaties wendbaarder. De scope van FSC is dataverkeer tussen organisaties en
machine to machine.
Beheer van toegangsrechten
Elke organisatie bepaalt zelf wie toegang krijgt tot welke data. Dit gebeurt via federatieve
authenticatie, wat betekent dat gebruikers bij hun eigen organisatie inloggen, maar toch toegang
kunnen krijgen tot gegevens van andere partijen.
Voordat een verzoek tot data een organisatie verlaat, wordt eerst gecontroleerd of dit verzoek wel
voldoet aan de afspraken rondom deze dataset. FSC levert hieraan de eerste controle of de
organisatie überhaupt toestemming heeft om de dataset te bevragen. Door FSC te koppelen aan de
toegangsverleningsstandaard worden veel specifiekere controles mogelijk. Individueel zijn beide
standaarden waardevol, maar gezamenlijk bieden ze synergie en maken ze het verdelen van de
verantwoordelijkheid mogelijk.
Controleerbaar
Het systeem houdt bij wie toegang heeft gehad tot welke data, wat zorgt voor transparantie en
controleerbaarheid. Dit is vooral belangrijk in overheidsomgevingen waar naleving van regels en
veiligheid essentieel is.
Iedere uitwisseling levert een FSC transactie logrecord op zowel bij de vragende organisatie als bij
de aanbieder van data. Beide logrecords hebben hetzelfde unieke kenmerk zodat de transactie bij
beide organisaties herleidbaar is. Audits binnen een organisatie kunnen hierdoor ook over de
organisatiegrenzen doorgaan in samenwerking met de andere organisatie. In samenwerking met de
logboek dataverwerkingen standaard (nog in de maak) wordt de controleerbaarheid nog krachtiger; door
het unieke transactie kenmerk op te nemen in de inhoudelijke logging is een audit nog beter uit te
voeren want het is dan niet alleen bekend welke organisaties, wat, wanneer uitgewisseld hebben, maar
de organisatie heeft ook vastgelegd welk proces de uitwisseling startte en welke medewerker daarbij
betrokken was.
Position paper Policy Based Access Control voor een Federatief Datastelsel
It’s PBAC-time
Belang en scope
Identity- and Access Management
Identity- and Access Management (IAM) is vrij vertaald het beheer om ervoor te zorgen dat de juiste
identiteiten, vooral personen of systemen, voor de juiste redenen en op het juiste moment toegang
krijgen tot de juiste faciliteiten. IAM is zowel nodig voor het kunnen leveren van diensten als om
te voorkomen dat er aan de verkeerde persoon wordt geleverd, en is van belang voor zowel de
dienstaanbieder als de -afnemer. IAM zorgt voor drie belangrijke voorwaarden voor digitale
dienstverlening1:
Identificatie zorgt er voor dat we weten wie je bent. Dit is je identiteit of een van je digitale
identiteiten (accounts);
Authenticatie zorgt er voor dat we met een bepaalde zekerheid weten dat je ook echt degene bent
die je zegt te zijn;
Autorisatie zorgt er voor dat we weten wat je dan mag (toegang) of juist niet mag. I n dit
document bespreken we Autorisatie.
Scope
Dit document focust op autorisatie en bespreekt de onderwerpen identificatie en authenticatie alleen
in context van autorisatie. Bijvoorbeeld wanneer het autorisatiemechanisme eisen stelt aan deze twee
onderwerpen. Voor uiteindelijke implementatie is een goede uitwerking van al deze onderwerpen in samenhang een
vereiste.
De scope van dit document is vastgesteld op datasamenwerking tussen overheden (overheidsorganen).
Voor deze position paper is dat voldoende. Bij uiteindelijke besluitvorming over autoriseren (en de
ander zaken omtrent identity- and access management) wordt ook de uitwisseling tussen private
partijen en tussen overheid en private partijen meegenomen.
Tot slot is de reikwijdte van dit paper datasamenwerking tussen overheidsorganen om datatoegang te
verlenen voor het uitvoeren van eigen werkzaamheden. De data-uitwisseling tussen een overheidsorgaan
en haar verwerker behandelen we niet. Hiermee bedoelen we: partij A kan zelf (om wat voor reden dan
ook) zelf geen data verwerken, geeft partij B toegang tot hun data en laat partij b deze verwerken.
De uitwisseling tussen deze partij en verwerker hoort niet bij dit autorisatiedeel.
Belang voor een Federatief Datastelsel
Het doel van deze position paper over Policy Based Access Control (PBAC) voor het Federatief
Datastelsel is om deze manier van autoriseren te onderzoeken en evalueren. Voor het Federatief
Datastelsel is een schaalbare, beheerbare en beheersbare wijze van toegang verlenen tot
data(-diensten) nodig. De traditionele methode en de manier waarop er momenteel wordt geautoriseerd,
voldoen niet aan de eisen en standaarden die het Federatief Datastelsel stelt, zoals het principe
dat Data bij de Bron blijft. Ook sluit PBAC beter dan andere
alternatieven aan bij het bestuursrecht en uitgangspunten die gelden voor de uitwisseling van
gegevens tussen overheden. PBAC lijkt daarom een kansrijke methode om datatoegang in een Federatief
Datastelsel te regelen.
Autorisatiemechanismen en PBAC
Verschillende autorisatiemechanismen
Toegangscontroles kunnen op meerdere manieren plaatsvinden. Het kiezen van de juiste methode is
afhankelijk van bijvoorbeeld de complexiteit van het I-landschap, de beheersbaarheid en de
schaalbaarheid. In alle gevallen geldt: een subject (medewerker, burger, organisatie) wil toegang
tot een object (databron, systeem, applicatie). Om een beeld te geven van verschillende manieren van
autoriseren worden hier kort de populairste methoden uitgelegd, op volgorde van simpel tot
geavanceerd:
Access Control List (ACL). Deze methode kun je vergelijken met een gastenlijst. Staat jouw
(digitale) identiteit op de controlelijst? Dan krijg je toegang, anders niet. Deze methode kost
weinig moeite om op te zetten (voor één databron of applicatie) en vraagt vooral een goed
identiteitenbeheer. Deze methode is moeilijk schaalbaar (want elke databron heeft een aparte
controlelijst nodig) en lastig beheersbaar. Daarnaast is er geen onderverdeling in soorten toegang
te maken: eenmaal binnen, kun je overal bij.
Figuur 1: Access Control List
Role Based Access Control (RBAC). Dit is de ‘klassieke’ manier van autoriseren waarbij
toegangsrechten worden gekoppeld aan rollen en aan deze rollen worden gebruikers toegewezen.
Meerdere toegangsrechten worden dus geclusterd tot 1 rol. De logica van het toekennen van rollen is
vooral gebaseerd op de functie van de medewerker. Een voorbeeld van een toegangsregel is: alle
medewerkers met de rol ‘Functioneel beheerder Sharepoint’ mogen bepaalde toegangsrechten in de
applicatie Sharepoint. Het beheer voor deze autorisatiemethode is op meerdere plaatsen belegd. Aan
de kant van de organisatie moeten de juiste mensen worden toegewezen aan de juiste rollen, en aan de
kant van de applicatie moeten de juiste rechten worden gekoppeld aan de juiste rollen. RBAC is veel
beter beheersbaar en schaalbaar dan ACL, en is een goed systeem voor toegang van medewerkers tot
applicaties en databronnen binnen dezelfde organisatie of hetzelfde I-landschap. Dit wordt lastiger
met identiteiten van buiten de organisatie. Daarnaast kan het aantal rollen enorm toenemen naarmate
de tijd vordert, en blijft het grootste gedeelte van deze methode handmatig werk (toevoegen van
medewerkers aan rollen).
Figuur 2: Role Based Access Control
Attribute Based Access Control (ABAC). Attributen zijn stukjes informatie over een persoon,
object of situatie. Gebruikersattributen geven context over een medewerker, zonder dat de volledige
identiteit wordt gegeven. Dit kunnen bijvoorbeeld haar afdeling, rang, rol, of afgeronde opleidingen
zijn. Bronattributen geven context over een databron, zoals wie de eigenaar is, het type bestand, of
rubriceringsniveau. Bij ABAC worden specifieke attributen van de medewerker gekoppeld aan specifieke
attributen van de databron of applicatie, en deze combinatie geeft wel of geen toegangsrechten.
Naast attributen van een persoon of object, bestaan er ook omgevingsattributen zoals tijd, locatie
en apparaattype, die gebruikt kunnen worden als extra restrictie in de toegangsregel. Je kunt
bijvoorbeeld de autorisatieregel krijgen: “elke medewerkers van afdeling X mag toegang tot data met
attribuut afdeling X, op werkdagen tussen 08.00 en 20.00 uur”. In vergelijking met RBAC is ABAC
flexibel, nog beter beheersbaar en schaalbaar, en daarnaast privacyvriendelijker, omdat alleen de
attributen van een medewerker gebruikt worden, die nodig zijn voor de toegangsregel. Ook neemt ABAC
handwerk weg: in plaats van handmatig medewerkers aan rollen toe te moeten voegen (RBAC), krijgt de
medewerker automatisch (proactief) toegang als deze de juiste attributen heeft. Voor ABAC is wel een
geavanceerder landschap nodig, met verschillende registraties voor de attributen, met goed geregeld
eigenaarschap en een geavanceerd autorisatieregelmechanisme.
Policy Based Access Control (PBAC)2. RBAC en ABAC maken gebruik van ‘statische’ elementen,
namelijk de rollen en attributen. Deze elementen staan in registraties in het landschap en worden
alleen veranderd als er iets wijzigt bij het subject (de medewerker) of het object (applicatie of
databron). PBAC gebruikt een dynamische, contextgebaseerde aanpak. Net als ABAC gebruikt PBAC ook
attributen voor het maken van toegangsregels, maar PBAC gaat hierbij nog een stap verder door deze
te combineren met policies, oftewel beleidsregels. Door het gebruik van policies wordt het systeem
dynamischer, omdat het sneller kan worden aangepast aan veranderende omstandigheden. Daarnaast
zorgt PBAC (specifiek: het gebruik van policies) ervoor dat het gemakkelijker is om
omgevingsattributen mee te nemen in de autorisatiebeslissing. Je krijgt bijvoorbeeld alleen toegang
als je via een geregistreerd device op een bepaalde manier toegang verzoekt. Naleving van
regelgeving wordt op deze manier ingebouwd. Het grootste voordeel van PBAC is dat het goed werkt in
een complexe structuur van verschillende organisaties. Zie hiervoor het hoofdstuk hierna Hoe werkt
PBAC.
PBAC maakt het mogelijk om alle voorwaarden voor toegang op één plaats inzichtelijk te hebben (in
het Policy Administration Point, afgekort PAP). Bij ABAC kan dat ook, maar implementaties zijn vaak
beperkt tot een beperkt aantal attributen. Bij RBAC is het vaak niet meer inzichtelijk of er nog
contextgerelateerde beperkingen zijn.
Kortom, het gebruik van PBAC in een samenwerking met meerdere organisaties biedt een gestroomlijnde,
veilige en goed beheerde aanpak voor het beheren van toegangsrechten en het handhaven van
beveiligingsstandaarden over alle organisatorische eenheden heen. Door deze afspraken te publiceren
wordt de samenwerking tevens transparant voor alle belanghebbenden gemaakt.
Hoe werkt PBAC
Figuur 3: Een autorisatieaanvraag in PBAC (XACML)
Datatoegang wordt via PBAC als volgt geregeld. Een gebruiker (het subject) wil graag toegang tot de
data (het object). Een autorisatieverzoek wordt ontvangen door het Policy Enforcement Point (PEP).
Dit punt is de slagboom van het systeem en verleent toegang of niet. Het PEP stuurt het verzoek naar
het Policy Decision Point (PDP). Dit punt neemt de uiteindelijke beslissing of het verzoek leidt tot
toegang of weigering. Om deze beslissing te maken heeft het punt informatie nodig: de
autorisatieregels die gelden voor deze situatie en de informatie over subject (wie doet het verzoek),
object (waartoe wordt toegang verzocht) en omgeving (onder welke omstandigheden wordt toegang
verzocht). Het PDP stuurt het verzoek door naar het PIP en het PAP. Het Policy Administration Point
(PAP) levert de juiste voorwaarden voor datatoegang en het Policy Information Point (PIP) de juiste
informatie over subject, object en omgeving. Het PDP clustert de informatie en maakt de beslissing
of de geleverde informatie volstaat om aan de voorwaarden van toegang tot de data te voldoen. Indien
ja, dan geeft het PDP een signaal aan het PEP om de toegang te verlenen. Zo nee, dan geeft het PDP
een signaal aan het PEP dat de slagboom dicht blijft. Zie bovenstaande figuur voor een schematische
weergave.
Samengevat:
Policy Enforcement Point (PEP)
Policy Decision Point (PDP)
Policy Administration Point (PAP)
Policy Information Point (PIP)
Hoe werkt PBAC over verschillende organisaties in een Federatief Datastelsel
Wanneer PBAC als autorisatiemechanisme wordt toegepast over verschillende organisaties ziet dat er
ongeveer zo uit als in figuur 4. Het verzoek tot data van het subject wordt eerst getoetst bij de
eigen organisatie. Deze bekijkt voor dit specifieke toegangsverzoek aan de hand van het vooraf
afgesproken afsprakenstelsel welke policies er gelden (PAP) en welke informatie van het subject en
de omgevingsfactoren van toepassing zijn (PIP). De PDP (nog steeds bij de datavragende organisatie)
bepaalt of het verzoek wordt goedgekeurd op basis van de beschikbare informatie en stuurt het
goedgekeurde verzoek door via de eigen PEP naar de PEP van de dataleverende partij3. In deze
goedkeuring staat beschreven dat er volgens de datavragende partij wordt voldaan aan de vooraf
opgestelde eisen voor datatoegang, en voor welke vooraf afgesproken data dit van toepassing is.
Wanneer de PDP van de datavragende partij het verzoek van het subject afkeurt, wordt er geen verzoek
naar de dataleverende partij gestuurd.
De PEP van de dataleverende partij ontvangt de informatie van de datavragende partij en bepaalt of
deze goedkeuring nog steeds geldt met de informatie die de datavragende partij zelf heeft. Het
verzoek gaat langs via de PEP naar de PDP en deze vult het verzoek aan met eigen informatie, vooral
informatie en context over de data. De PDP legt de vooraf afgesproken policies uit de PAP, de
(data)informatie uit de PIP naast het binnengekomen verzoek en besluit of de datatoegang wordt
toegekend. Indien ja, dan krijgt de PEP het signaal dat het subject van de datavragende partij
toegang mag krijgen tot het object van de dataleverende partij. Zo niet, dan wordt het
oorspronkelijke verzoek tot data alsnog afgekeurd en wordt er geen toegang verleend.
Zowel datavragende als dataleverende partij voeren policies uit om het verzoek goed of af te keuren.
Hoewel de policies onderdeel uit maken van het afsprakenstelsel tussen beiden partijen, zijn dit
doorgaans niet dezelfde policies. De datavragende partij voert de checks uit aan de subjectkant,
bijvoorbeeld: behoort de medewerker tot de mensen die data mag opvragen, of mag de organisatie deze
data bij de dataleverende partij opvragen? De dataleverende partij voert policies uit als check aan
de datakant, bijvoorbeeld: onder welke omstandigheden mag deze data worden opgevraagd, of: is deze
data gelabeld als data die gedeeld mag worden?
Hier ligt ook een sterke relatie met de andere onderdelen van IAM, voornamelijk Identity Management.
Welke gegevens moet een organisatie vastleggen om met dit stelsel te kunnen werken en welke gegevens
hiervan komen terug in de policies? Hoe de identiteit4 eruit komt te zien is een ander vraagstuk
dat verdere uitwerking vraagt.
Figuur 4: PBAC over meerdere organisaties
De poortwachter van het Federatief Datastelsel heeft ook een belangrijke rol in dit mechanisme.
Vanuit het Federatief Datastelsel worden de stelselpolicies gedeeld met de organisaties. Deze
stelselpolicies bestaan uit de standaarden vanuit het Federatief Datastelsel en de
samenwerkafspraken tussen de organisaties. Zie hoofdstuk [De poortwachter binnen het Federatief
Datastelsel](#de-poortwachterfunctie-binnen-het-Federatief Datastelsel) met meer informatie over
deze Poortwachter.
Tot slot, deze situatie beschrijft een tussenfase. Uiteindelijk, bij een goed opgezet en
functionerend stelsel, en bij bevraging tussen twee overheidsorganen, zal het zwaartepunt van het
uitvoeren van de checks met behulp van policies gaan liggen bij de datavragende partij.
Uitgangspunten
Eigenaarschap en verantwoordelijkheid op de juiste plaats
Wanneer datatoegang op de traditionele manier, zoals het veelgebruikte RBAC, is ingericht, wordt er
veel gevraagd van de aanbieders van data. Deze partij moet immers kunnen toetsen of degene die
toegang vraagt ook daadwerkelijk toegang mag krijgen, en moet daardoor allerlei checks doen op basis
van eigen objectinformatie (de informatie over de data) en de subjectinformatie van de aanvrager (de
informatie over degene die toegang wil, als deze al op de juiste manier wordt gedeeld). In de
praktijk betekent dit, dat een groot gedeelte van het werk om de data-aanvraag te toetsen voor
rekening van de dataleverende partij komt.
Door gebruik te maken van een generiek systeem, opgesteld vanuit het Federatief Datastelsel, op
basis van PBAC, is het mogelijk om de beheerlast te verschuiven naar de vrager van data. De
datavragende partij laat dan zien, op basis van eigen informatie en vooraf afgesproken informatie
van de data, dat deze voldoet aan de policy om toegang te krijgen tot de data van de dataleverende
partij.
Het lijkt dan misschien alsof er veel verantwoordelijkheid bij de afnemer gelegd wordt, maar de
dataleverende partij heeft de verantwoordelijkheid om te zorgen dat de voorwaarden compleet zijn.
PBAC heeft het voordeel dat het toegang verlenen beheersbaar, uitbreidbaar, en responsief houdt,
vanuit een dataeigenaar-perspectief. Op deze manier wordt de werklast voor datatoegang verdeeld over
de datavragende en dataleverende partij en ligt de verantwoordelijkheid voor het aantonen van
verschillende delen informatie bij de juiste partijen.
Kortom, door gebruik te maken van PBAC worden eigenaarschap en verantwoordelijkheid op de juiste
plek belegd.
Zero trust
PBAC voldoet aan het Zero trust5 principe, dat uitgaat van het grondbeginsel never trust, always
verify. Vroeger was de beveiliging primair gericht op het plaatsen van beveiligingsmaatregelen op
de “de buitenste” laag van de infrastructuur. Het zero trust principe gaat daarentegen uit van
segmentering. Er ontstaat dus een opdeling van bijvoorbeeld meerdere kleine beveiligde netwerken
genaamd implied trust zones. Deze implied trust zones helpen bij het structureren van een of
meerdere functionaliteiten door het implementeren van een set aan beveiligingseisen. Als eenmaal is
voldaan aan deze eisen, volgt toegangsverlening. Toegang tot deze implied trust zones gaat gepaard
met sterke authenticatie en autorisatie en het monitoren hierop. Door de structurering in PBAC is
dit autorisatiemechanisme een manier om aan deze autorisatie-eis te voldoen. Dit impliceert ook dat
er in dit systeem dezelfde controles worden gedaan bij zowel interne als externe bevragingen van
data, in plaats van alleen op externe bevragingen in traditionele niet-zero-trust-systemen.
Datasoevereiniteit
PBAC voldoet aan het principe Datasoevereiniteit. Doordat er met PBAC gebruik wordt gemaakt van een
afsprakenstelsel met geautomatiseerde besluitvorming, wordt er dus vooraf aan de samenwerking
besloten aan welke voorwaarden beide partijen moeten voldoen om data te kunnen uitwisselen. De
dataleverende partij hoeft op het moment van de aanvraag niet meer te besluiten of de
datavragende partij toegang krijgt of niet. Dit gebeurt namelijk aan de voorkant in plaats van op
het moment van data-aanvraag en de datatoegang wordt automatisch geregeld. Dit maakt het vooraf
transparant wanneer data tussen deze partijen mag worden gedeeld en biedt tegelijkertijd de vrijheid
om deze afspraken flexibel te wijzigen wanneer er een verandering in de samenwerking ontstaat.
Vooraf toetsen van afspraken gebeurt tegenwoordig al in veel gevallen waarin persoonsgegevens en de
AVG een rol spelen. Een afnemer kan bij een aanbieder persoonsgegevens aanvragen om te mogen
gebruiken, waarvoor de afnemer een wettelijke taak heeft als grondslag. De aanbieder toetst hierbij
ook vooraf of dit legitiem is en neemt een autorisatiebesluit. Het verschil tussen de huidige
situatie en de toekomstige situatie met PBAC, is dat er een structureel systeem wordt neergezet
waarbij er veel kan worden geautomatiseerd. Het handmatige werk van het checken van legitimiteit en
het nemen van een autorisatiebesluit, wordt door PBAC aan de voorkant goed geregeld zodat er
real-time geen lange doorlooptijden meer zijn en er minimaal handwerk is. Het autorisatiebesluit is
geen handmatig besluit meer, wat bijdraagt aan datasoevereiniteit.
Policies vooraf en audits achteraf
De datavragende partij controleert aan de hand van de policies (vooraf gemaakte afspraken) en de
context van de aanvraag of zij deze aanvraag moet goedkeuren of afkeuren. De dataleverende partij is
géén toezichthouder en zal niet checken of het subject aan alle eisen voor het aanvragen van data
voldoet (en mag dat ook vaak niet). De dataleverende partij ontvangt een goedgekeurd verzoek en
controleert vervolgens of de context van de data ook voldoet aan de gestelde policies. Dit betekent
niet dat de datavragende partij ‘zomaar’ al hun eigen dataverzoeken kan goedkeuren! Of de vooraf
gemaakte afspraken daadwerkelijk worden nageleefd kan achteraf worden gecontroleerd op elke plaats
waar keuzes worden gemaakt (zie paragraaf Zero Trust). Via een logboek
dataverwerkingen kan worden aangetoond of de datavragende partij correct heeft gehandeld. Deze audit
kan worden uitgevoerd in opdracht van een toezichthouder op dezelfde manier als dat momenteel al
wordt gedaan. De grondslag voor de datatoegang is de combinatie van de policies van beide partijen.
Door autorisatie op deze manier in te regelen wordt de focus van de standaarden (van het Federatief
Datastelsel) gericht op de datavragende partij: zij moeten kunnen verantwoorden waarom ze toegang
tot de data moeten krijgen. Het correct handelen van de datavragende partij is geen
verantwoordelijkheid van de dataleverende partij.
Privacy
Bij het gebruik van Role Based Access Control (RBAC) moet voor elke datatoegang een identiteit
gekoppeld worden aan een rol. Deze rol wordt vervolgens gekoppeld aan rechten voor datatoegang. Dit
betekent dat als een medewerker van partij A toegang wil tot data van partij B, er in de organisatie
van partij B een digitale identiteit (account) aangemaakt moet worden zodat deze gekoppeld kan
worden aan rollen. Voor partij B is dan precies inzichtelijk wie deze persoon is en dit voldoet niet
aan de vereiste van dataminimalisatie.
Bij het gebruik van Attribute Based Access Control (ABAC) wordt het besluit voor datatoegang gemaakt
door de autorisatieregels en bijbehorende attributen te vergelijken. Dit betekent dat als een
medewerker van partij a toegang wil tot data van partij b, dat de attributen van deze medewerker
(subjectattributen) moeten worden gedeeld met partij b. Hoewel dit minder informatie geeft dan de
volledige identiteit die wordt gedeeld bij RBAC, geven deze attributen nog steeds informatie over de
identiteit van de medewerker. Voor partij B is dan deels inzichtelijk wie deze persoon is en ook
dit voldoet niet aan de vereiste dataminimalisatie.
Bij PBAC worden geen identiteiten of attributen gedeeld met de partij B. Er wordt slechts gedeeld
aan welke policies het subject van partij A voldoet en voor welke data van partij B deze policies
van toepassing zijn. Op deze manier wordt er minimale informatie uitgewisseld over de
identiteit van de medewerker en voldoet de autorisatie aan het vereiste van dataminimalisatie.
PBAC is in lijn met kaderstellers
Diverse partijen binnen de overheid omarmen deze manier van autoriseren. De VNG geeft aan dat
gemeenten steeds meer op deze manier zouden moeten autoriseren. Ook de architecten vanuit CIO Rijk
bewegen in de richting van PBAC en stellen steeds meer standaarden op om hieraan op een goede manier
te voldoen. In het domein Zorg geeft Nictiz, het Nederlandse kenniscentrum voor landelijke
toepassingen van ICT in de zorg, ook aan dat PBAC de gewenste manier van autoriseren is. Daarnaast
werken er steeds meer Europese projecten met PBAC in plaats van de traditionele
autorisatiemechanismen en ook RVO geeft het signaal dat dit steeds meer de gewenste manier van
autoriseren is.
Implementatie
De poortwachterfunctie6 binnen het Federatief Datastelsel
De poortwachterfunctie zorgt voor een transparant beslisproces. Het toetst, autoriseert en
registreert koppelingsverzoeken tussen bronnen, toetst op conformiteit met de AVG en de aansluit- en
gebruiksvoorwaarden van het stelsel. De toetsing zal veelal neerkomen op het afwegen van strijdige
belangen, waarbij bijvoorbeeld noodzaak, privacy, ethiek en conformiteit met aansluit- en
gebruiksvoorwaarden van het Federatief Datastelsel een rol spelen. Vooral dat laatste heeft een
sterke relatie met PBAC. Het toetsen gebeurt in een transparant beslisproces met mogelijkheden voor
bezwaar en beroep. De uitkomst van dit proces wordt vastgelegd in een openbare registratie
(gegevensstroom-boekhouding). Deze registratie heeft de volgende functies. Per functie wordt de
relatie met PBAC uitgelegd:
Opname van een datadeelrelatie in het register legitimeert de datadeling door daarvoor een
juridische grondslag te bieden. Deze grondslag is een verwijzing naar een toepasselijk
wetsartikel of een positief besluit van het toetsingscomité.
PBAC: Voor elke autorisatieregel, dus een beperking op datadeling, geldt dat deze herleidbaar
moet zijn naar een juridische grondslag. Deze autorisatieregels inclusief grondslagen worden
vastgelegd in de policies van PBAC (zie Policy Administration Point (PAP)).
Het maakt op één plek inzichtelijk welke stelseldata, met welke partijen, voor welk doel mogen
worden gedeeld en wat daarvoor de juridische grondslag is. Hiermee kan ook periodiek worden
getoetst of eerder genomen beslissingen nog steeds valide zijn. Daarnaast ontstaat inzicht op
welke gebieden aanpassing van wetgeving nodig is om oordelen van het toetsingscomité juridisch
sterker te verankeren.
PBAC: De policies inclusief herleiding naar juridische grondslag worden vastgelegd in de Policy
Administration Point (PAP). Door deze transparant te publiceren en te zorgen dat die via één plek
inzichtelijk is, kan hieruit het inzicht verkregen worden op welke gebieden aanpassing van
wetgeving nodig is.
Op het Federatief Datastelsel aangesloten data-aanbieders kunnen op basis van de gegevens in het
register eenvoudig, geautomatiseerd, vaststellen of ze een datadeel-verzoek van een tot het
stelsel toegelaten afnemer mogen honoreren. Ze hoeven dus niet meer zelf een juridische toets uit
te voeren.
PBAC: Door voor het autoriseren het mechanisme PBAC te gebruiken, worden er voorafgaand aan de
datasamenwerking voorwaarden gesteld aan het delen van data. Het maken van het besluit of iemand
toegang krijgt tot data wordt geautomatiseerd gedaan door het Policy Decision Point (PDP) op
basis van de opgestelde policies. De juridische toets, maar ook afwegingen op het vlak van
ethiek, privacy, maatschappelijke wenselijkheid en belang, zijn vooraf al gedaan en hoeven niet
plaats te vinden tijdens het proces van datadelen.
Vastlegging in het centrale register van datadeelrelaties, in combinatie met de toelating tot
het stelsel (het voldoen aan de aansluitvoorwaarden) vervangt de bilaterale contracten die nu nog
vaak nodig zijn om de datadeling tussen partijen te legitimeren.
PBAC: Door PBAC als voorwaarde vanuit het Federatief Datastelsel te stellen wordt op een eenduidige en
gestructureerde manier datadeling geregeld. Een datavragende partij kan gestandaardiseerd toegang
verkrijgen en er hoeft dus geen bilateraal contract nodig te zijn.
Hoe PBAC precies een deel van de poortwachterfunctie kan invullen vereist een uitvoerige
vervolgstudie, bij voorkeur aan de hand van Use Cases.
Voorbeelden
SUWINET is een goed voorbeeld om te kunnen laten zien hoe het gebruik van PBAC uitdagingen kan
oplossen en verbeteren. Bij dit voorbeeld heeft de dataleverende kant veel verantwoordelijkheid en
daardoor wordt er informatie buiten het systeem om uitgewisseld. Dit is niet de gewenste situatie en
door het gebruik van PBAC kan dit worden verbeterd.
Vanuit CIO-Rijk zijn enkele voorbeelden aangeleverd van policies:
Deze dienst mag alleen via een door ons vertrouwd netwerk gebruikt worden.
De persoon moet geauthentiseerd zijn door een door ons vertrouwde IDP op het juiste niveau
De persoon moet handelen namens een door ons vertrouwd bedrijf.
De persoon mag alleen data zien voor het bedrijf namens welke de persoon werkt.
Uitdagingen
Naast de voordelen van het gebruik van PBAC bestaan er ook enkele uitdagingen in de huidige
context van het Federatief Datastelsel en de overheid:
Vooraf weet je niet precies door wie of waarom de data gebruikt gaat worden, dus bij het
aansluitproces van een afnemer zal er constant gecheckt moeten worden of de policies die er zijn
wel toereikend zijn én of ze geen gaten laten vallen bij de nieuw situatie. Dit hoort bij het
principe Zero Trust.
Binnen de overheid wordt PBAC (volgens CIO-Rijk) nog niet echt ergens geïmplementeerd. Bij grote
Tech bedrijven of financiële instellingen is het gebruikelijker.
Dit document geeft een eerste concept voor hoe de structuur van PBAC binnen een Federatief
Datastelsel eruit kan komen te zien. De technische implementatie kent echter nog veel
verschillende smaken. Hier zullen goede afwegingen in gemaakt moeten worden.
Complexiteit vanuit een landschapsperspectief: het overheidsorgaan is eigenaar van veel plekken
waar de data staat:
Er zijn meerdere plekken waar de data staat, want de data staat bij de bron;
Er zijn meerdere afnemers van de data;
Het hele landschap wijzigt ook voortdurend.
Daarnaast moet toegang tot data eenvoudig en snel toegekend te worden. Dit is waarom er vaak een
voorkeur is voor policies en niet een RBAC-model.
Stappen voor vervolg
Naast een discussiestuk (dit document) hebben het project Federatief Datastelsel en
Digilab het voornemen om PBAC in een concrete proefopstelling te
tonen, om tastbaar te maken wat policies zijn en wat ervoor ingeregeld moet worden. Vervolgstappen
worden in een separaat document uitgewerkt en zal de volgende onderwerpen bevatten:
Casusbeschrijving en uitwerking van een use case met concrete policies en attributen;
Onderzoek naar of XACML (of ODRL) nog steeds de standaard is;
Verhouding PBAC met mechanismen van iSHARE, en met andere technieken;
Uitwerking relatie PBAC en de poortwachterfunctie;
Onderzoek naar het maken van specifieke endpoints voor specifieke klanten;
Gebruik van FSC (VNG), verbinding moet verder worden uitgewerkt;
Noraonline.nl – Nederlandse Overheid Referentie Architectuur ↩︎
Stelselfunctie voor het onderhouden van de stelselarchitectuur en het faciliteren van de communities waarin kennis en ervaring over het stelsel wordt gedeeld. Het kennisnetwerk.
biedt eerstelijnsondersteuning van gebruikers en geregistreerden.
Status
Deze functie wordt samen met het kenniscentrum van de Interbestuurlijke Datastrategie (IBDS)
vormgegeven en groeit mee met de behoeften van aanbieders en gebruikers.
Achtergrond
// TODO
FDS context & positionering
// TODO
Inhoudelijke verdieping
// TODO
Standaardisatie
// TODO
37 - Marktmeester
Stelselfunctie voor het verbinden van vraag en aanbod. Ondersteunt bij het inzichtelijk maken van het potentieel en het realiseren van nieuwe gebruikerswensen.
verbindt vraag en aanbod van data voor sectoroverstijgend,
meervoudig gebruik.
Helpt het gebruikspotentieel van het Federatief Datastelsel inzichtelijk te maken en ondersteunt
stelselgebruikers bij het inbrengen van hun eisen en wensen omtrent data voor maatschappelijke
opgaven.
Status
Er is een inrichtingsvoorstel gemaakt voor de invulling van de Marktmeester functie tijdens de
projectfase waarbij er een centraal aanspreekpunt is. Dit voorstel is besproken in het Tactisch
Stelseloverleg van 30 mei
2023.
Met deze tijdelijke invulling wordt de komende tijd ervaring opgedaan in samenwerking met het
project Data in maatschappelijke opgaven. Deze praktijkervaring wordt gebruikt om later een
voorstel voor de definitieve inrichting van deze stelselfunctie te doen.
Achtergrond
// TODO
FDS context & positionering
// TODO
Inhoudelijke verdieping
// TODO
Standaardisatie
// TODO
38 - Poortwachter
Stelselfunctie voor toetsing, autorisatie en registratie van koppelingsverzoeken. Toetst op conformiteit met de AVG en de stelsel aansluit- en gebruiks-voorwaarden en zorgt daarbij voor een transparant beslisproces.
Toetst, autoriseert en registreert koppelingsverzoeken tussen bronnen. Toetst op conformiteit met
de AVG en de stelsel aansluit- en gebruiksvoorwaarden.
Zorgt voor een transparant beslisproces.
Status
Er is een startnotitie gemaakt.
In de tweede helft van 2023 is de beschrijving van de werking verdiept langs een aantal dimensies:
functies, standaarden, voorzieningen en wettelijk inbedding. Dit als opmaat naar demonstrators en
experimenten in het Digilab om de feitelijke werking zo concreet mogelijk te maken.
Achtergrond
// TODO
FDS context & positionering
Kernelement van het federatief datastelsel is dat datagebruik in overeenstemming is met publieke
waarden. Om dit waar te maken, is het nodig dat ontwerp en realisatie van het FDS vanuit dit
perspectief worden gestuurd. Daartoe zijn de volgende ontwerpelementen passend:
Poortwachtersfunctie.
Dataminimalisatie.
Regie op Gegevens.
Het stelsel voorziet in gecontroleerde toegang tot gevoelige data. Voor het toegang bieden en
afnemen van data die niet gevoelig zijn, volstaan veelal algemene toegangsregels, bijvoorbeeld bij
een bron die als open data is aangemerkt. Voor gevoelige stelseldata zoals persoonsgegevens, waarbij
gebruikt wordt gemaakt van het BSN als identificatie en koppelingssleutel, is meer nodig. Deze data
passeren eerst de stelselfunctie Poortwachter.
De poortwachters is de functie binnen het Federatief Datastelsel die op basis van een formeel
vastgesteld toetsingskader bepaalt of de combinatie data - gebruikersgroep - gebruiksdoel kan worden
toegestaan. Dit is een drempel om ervoor te zorgen dat er een zorgvuldige afweging wordt gemaakt
tussen de vaak tegenstrijdige maatschappelijke belangen bij nieuwe vormen van sector overstijgend
datagebruik.
Door de verantwoordelijkheid voor deze toetsing op stelselniveau te beleggen, kan kennis over
verantwoord datagebruik worden gebundeld en ontstaan er meer mogelijkheden om de afweging
transparant en controleerbaar te maken. Dit maakt het proces efficiënter doordat individuele
data-aanbieders worden ontzorgd omdat ze op uitvoeringsniveau geen belangenafweging meer hoeven te
maken die eigenlijk op het politieke niveau thuishoort.
Onderdeel van het toetsingskader is het benutten van de verschillende opties die het stelsel biedt
om verantwoord data te delen. Zo ondersteunt het toekomstig stelsel dataminimalisatie waarbij de
verstrekkers van stelseldata privacy enhancing technologies toepassen of intelligente
bevragingsdiensten leveren die gericht antwoord geven op een gestelde informatievraag (bijvoorbeeld
is deze persoon jonger dan 18?).
In een aantal gevallen is het dan niet meer nodig om (privacy)gevoelige data te delen. Een andere
mogelijkheid die het stelsel ondersteunt is het faciliteren dat de burger of het bedrijf zelf
toestemming geeft om persoonlijke of bedrijfsdata via het federatief datastelsel met anderen te
delen.
De Poortwachtersfunctie zorgt voor toetsing, autorisatie en registratie van verzoeken om data te
delen1 . De toetsing zal veelal neerkomen op het afwegen van strijdige belangen, waarbij de volgende
zaken een rol spelen:
Noodzaak (er zijn geen alternatieven, digitaal werken is nodig, het gaat om tot de persoon
herleidbare of concurrentiegevoelige gegevens).
Het maatschappelijke belang
Het recht op bescherming van de persoonlijke levenssfeer (bescherming privacy).
Juridische toelaatbaarheid.
Ethische toelaatbaarheid.
Maatschappelijke wenselijkheid.
Conformiteit met aansluit- en gebruiksvoorwaarden van het federatief datastelsel.
Dit gebeurt in een transparant beslisproces met mogelijkheden voor bezwaar en beroep. De uitkomst
van dit proces wordt vastgelegd in een openbare registratie (gegevensstroom boekhouding). Deze
registratie heeft de volgende functies:
Opname van een datadeelrelatie in het register legitimeert de datadeling door daarvoor een
juridische grondslag te bieden. Deze grondslag is een verwijzing naar een toepasselijk wetsartikel
of een positief besluit van het toetsingscomité.
Het maakt op één plek inzichtelijk welke stelseldata, met welke partijen, voor welk doel mogen
worden gedeeld en wat daarvoor de juridische grondslag is. Hiermee kan ook periodiek worden
getoetst of eerder genomen beslissingen nog steeds valide zijn. Daarnaast ontstaat inzicht op
welke gebieden aanpassing van wetgeving nodig is om oordelen van het toetsingscomité juridisch
sterker te verankeren.
Op het federatief datastelsel aangesloten data aanbieders kunnen op basis van de gegevens in het
register eenvoudig, geautomatiseerd, vaststellen of ze een datadeel verzoek van een tot het
stelsel toegelaten afnemer mogen honoreren. Ze hoeven dus niet meer zelf een juridische toets uit
te voeren.
Vastlegging in het centrale register van datadeel relaties, in combinatie met de toelating tot het
stelsel (het voldoen aan de aansluitvoorwaarden) vervangt de bilaterale contracten die nu nog vaak
nodig zijn om de datadeling tussen partijen te legitimeren.
De Poortwachtersfunctie is één van de structurele stelselfuncties die het project Federatief
Datastelsel de komende jaren zal realiseren. Bij de realisatie wordt gebruik gemaakt van de
resultaten van andere onderdelen van het programma Realisatie Interbestuurlijke Datastrategie
(Adviesfunctie verantwoord datagebruik, het organiseren van datadialogen) en de uitkomsten van
relevante externe trajecten zoals het wetgevingswerk van de Regeringscommissaris
Informatiehuishouding.
De eerste stap is het ontwerp van deze functie, vergelijkbaar met de wijze waarop de inrichting van
de stelselfunctie Marktmeester is beschreven. Daarna zal de feitelijke inrichting via use
cases / praktijksituaties plaatsvinden. Het tempo hangt daarmee af van de snelheid waarmee geschikte
use cases zich voordoen. Parallel wordt de technische functionaliteit van de Poortwachtersfunctie
beproefd (m.b.v. de Integrale Gebruiksoplossing, de IGO) in de Innovatiewerkplaats.
Standaardisatie
// TODO
39 - Regisseur
Stelselfunctie voor de coördinatie van beheer en (door)ontwikkeling van het stelsel.
Deze functie bestaat al in het huidige Stelsel van Basisregistraties. Deze rol wordt over het
algemeen ingevuld door de verantwoordelijk opdrachtgever voor de registratie. Dit wordt op termijn
en in samenspraak met omgevormd tot een passende toezichtfunctie voor het FDS.
Achtergrond
// TODO
FDS context & positionering
// TODO
Inhoudelijke verdieping
// TODO
Standaardisatie
// TODO
41 - FDS Catalogus
Inzicht bieden in het aanbod van data en dataservices.
Achtergrond
De in- en overzichtfunctie is één van de stelselfuncties van het te realiseren Federatief
Datastelsel (FDS). Deze stelselfunctie maakt het mogelijk om vanuit verschillende perspectieven een
totaalbeeld te krijgen van de inhoud van het FDS: welke data conform het FDS-afsprakenkader wordt
gedeeld, waarvoor deze data kan worden gebruikt, welke partijen betrokken zijn bij dit gebruik en
hoe deze zich binnen de federatie tot elkaar verhouden.
FDS context & positionering
Dit wordt mogelijk omdat is afgesproken dat alle componenten van het FDS (deelnemers, datasets en
datadiensten) van betekenisvolle beschrijvende gegevens (metadata) worden voorzien die op een
gestandaardiseerde manier openbaar beschikbaar worden gesteld. Hiermee ontstaat een virtuele open
(meta)dataset, een ‘catalogus’, die op verschillende manieren kan worden ontsloten en doorzocht.
Zo kan bijvoorbeeld worden opgezocht welke gegevens er in de basisregistratie WOZ zijn opgenomen,
wat de betekenis en de kwaliteit daarvan is en met welke datadiensten dit aanbod is ontsloten.
Hoewel de in- en overzicht functie op zich alleen zaken passief toont (overzicht biedt), levert dit
wel het inzicht dat nodig is om op een verantwoorde manier actief met het datapotentieel aan de slag
te kunnen gaan.
Omdat de gekozen afspraken en standaarden het mogelijk maken om ‘alles met alles’ te verbinden en de
FDS-metadata zelf ook een volgens de FDS-standaarden ontsloten (virtuele) dataset is, kan iedereen
naar eigen behoefte met de open FDS-metadata aan de slag. Zo is het bijvoorbeeld mogelijk om een
catalogus te bouwen waarin wetgevingsjuristen eenvoudig kunnen zoeken of een bepaald begrip al in
bestaande FDS-data voorkomt, welke definitie het daar heeft en aan welke juridische grondslag (wet,
regeling) deze definitie is ontleend. Gebruikers die bijvoorbeeld met het thema energietransitie aan
de slag willen, kunnen op basis van daarmee verbonden trefwoorden zoeken welke data daarvoor in het
FDS beschikbaar is en of deze voor hen bruikbaar zijn (qua toegang, kwaliteit, betekenis etc.) Dat
zoeken kan in de eigen catalogus van het FDS, maar het is ook mogelijk om de FDS-metadatadiensten in
een eigen energiecatalogus te integreren die ook niet-FDS-data ontsluit om zo de gebruikers een
totaalbeeld van het energiedata-aanbod te geven. Omdat de FDS afspraken en standaarden voor het
ontsluiten van meta data het mogelijk maken om op begrippen te zoeken, ondersteunen ze ook het
oppakken van semantische harmonisatie en andere acties om verschillende databronnen beter op elkaar
te laten aansluiten en om wetgeving en data beter met elkaar te verbinden. Ze maken het namelijk
mogelijk om een overzicht te krijgen van begrippen met een verschillende naam, maar dezelfde
betekenis (synoniemen), van begrippen met dezelfde naam maar juist een verschillende betekenis
(homoniemen), of van begrippen die zijn opgebouwd uit een combinatie van een aantal andere begrippen
(concepten).
De in- en overzichtfunctie is daarmee een belangrijk instrument voor het creëren van waarde met de
in het FDS opgenomen data.
De in- en overzichtfunctie is ook vanuit een ander perspectief van belang. Omdat iedereen de
metadata kan raadplegen (het is immers open data), wordt de inhoud van het FDS volledig transparant,
waardoor dit ook onderwerp kan zijn van publiek debat. Dit is een bewuste keuze omdat bij het FDS de
publieke waarden centraal staan. Deze openheid betreft uiteraard alleen de beschrijvende data (de
metadata) en niet de data zelf. De individuele gegevens binnen de datasets zijn en blijven alleen
toegankelijk voor degenen die daartoe zijn geautoriseerd.
Beoogde werking
Voor het aanbieden van de metadata gelden dezelfde principes als voor andere FDS-data. Dit betekent
dat degene die data in het stelsel aanbiedt zelf de kenmerken van deze data beschrijft en zelf
diensten levert om deze metadata ‘bij de bron’ te kunnen bevragen. Door aan te sluiten bij gangbare
wereldwijde, Europese en nationale standaarden voor het generen, vastleggen en ontsluiten van
metadata wordt deze meervoudig bruikbaar. Data-aanbieders hoeven dit in principe slechts één keer te
doen om hun aanbod in alle voor hen relevante datastelsels (dataspaces) voor mensen en machines
vindbaar te maken. Het op het FDS toegesneden data-aanbod kan hieruit gedestilleerd worden door in
de metadata een ‘FDS-label’ op te nemen als in het aansluitproces is vastgesteld dat aan de
FDS-kwaliteitseisen wordt voldaan. Door voor dit labelen een stelseloverstijgende standaard af te
spreken, kunnen data-aanbieders op uniforme wijze in de metadata laten zien aan welke
afsprakenstelsels ze voldoen, dus in welke datastelsels hun data gebruikt kunnen worden. Met deze
aanpak wordt de variëteit in het datagebruik ondersteund en worden tevens groeipaden gefaciliteerd.
Open overheidsdata waarvan de metadata al wel op orde is, maar die bijvoorbeeld alleen nog maar als
download beschikbaar is, kan al meteen op data.overheid.nl worden aangeboden terwijl deze pas later,
nadat bijvoorbeeld door het toevoegen van een API het FDS-label is verdiend, ook in de FDS-catalogus
verschijnt.
Van visie naar werkelijkheid: het realisatietraject
In de kop van de vorige paragrafen werd het woord “beoogd” gebruikt. Dat illustreert dat er nog het
nodige te doen valt voordat we zover zijn. Soms betreft dit ontwikkeling omdat de benodigde metadata
standaarden er nog niet zijn, soms betreft dit het kiezen uit verschillende concurrerende
standaarden en soms is de standaard duidelijk maar moet deze nog op de Nederlandse situatie worden
toegespitst of moet er worden afgesproken hoe je de standaard precies gaat gebruiken.
Zelfs als dit alles achter de rug is, moet er nog ervaring worden opgedaan met het in onderlinge
samenhang toepassen van deze standaarden om het verlangde inzicht en overzicht op FDS-(totaal)niveau
te krijgen. Als elke FDS-deelnemer zelf het wiel uit moet vinden, zijn we vele jaren verder voordat
deze essentiële stelselfunctie voldoende bruikbaar is. Het FDS-realisatieproject zal daarom
ondersteuning bieden om de realisatie en implementatie te versnellen. Daarbij wordt de volgende
aanpak gehanteerd:
Vertrekpunt is het denkwerk dat al binnen de Nora-community is gedaan (zie de bijlage onderaan dit
hoofdstuk).
Het FDS-project onderneemt in samenwerking met de verantwoordelijke beheerders van bestaande
metadata voorzieningen en de (potentiële) data-aanbieders actie om de hierna genoemde
voorzieningen verder te ontwikkelen. Dit als tijdelijke overbrugging naar de uiteindelijke
oplossing van een op afspraken en standaarden gebaseerd federatief werkend virtueel geheel, met
voor het FDS mogelijk nog een eigen ‘catalogus’ ingang om eenvoudig een overzicht te krijgen van
het data aanbod dat aan de eisen van het FDS-afsprakenstelsel voldoet.
Voor het beschrijven van datasets is dit nu data.overheid.nl. De relevante standaard hiervoor is
DCAT.
Voor het beschrijven van de in data opgenomen gegevens is dit nu de stelselcatalogus. Relevante
standaarden hiervoor zijn SKOS, MIM en de standaard voor het beschrijven van begrippen (SBB).
Voor het beschrijven van dataservices (API’s) is dit developer.overheid.nl.
Voor nieuwe elementen zoals het beschrijven van de stelseldeelnemers en de kwaliteit van data en
-diensten (het inhoud geven aan het FDS-label) ontwikkelt het FDS-project in samenwerking met
kennisinstituten zoals Geonovum nieuwe standaarden die in het Digilab worden beproefd om te
verifiëren of ze praktisch werkbaar zijn.
Het FDS zorgt voor het ontwikkelen van afspraken en standaarden voor het betekenisvol verbinden
van de verschillende metadatabronnen, waarbij met in het Digilab te ontwikkelen
referentietoepassingen beproefd wordt of deze op een werkbare manier het beoogde totaalbeeld
opleveren. Hierbij wordt aansluiting gezocht bij proeven en pilots die voor de EU of sectorale
dataspaces worden gedaan.
Als is aangetoond dat het werkt en werkbaar is, worden koplopers gezocht die de componenten van de
FDS in- en overzichtfunctie voor (een deel van) hun aanbod willen implementeren. Hiermee wordt
duidelijk wat er nodig is om het samenhangend geheel van bestaande en nieuwe meta data standaarden
in de uitvoeringspraktijk toe te passen en komen er ervaringscijfers beschikbaar waarmee geraamd
kan worden hoeveel tijd en geld er nodig is om ze stelselbreed toe te gaan passen.
De opgedane praktijkervaring wordt vervolgens benut om de formele besluitvorming over de
opschaling in gang te zetten, met behandeling van de voorstellen in het Interbestuurlijk Data
Overleg (IDO) en het Overheidsbreed Beleidsoverleg Digitale Overheid (OBDO) en een openbare
consultatie van volgens de bestaande procedures van het Forum Standaardisatie.
Als de formele besluitvorming succesvol is afgerond zal het FDS-project de adoptie aanjagen door
de stelselpartijen te ondersteunen bij de implementatie van de (nieuwe) metadata-afspraken en
-standaarden. Hierbij kan gedacht worden aan het beschikbaar stellen van validators, het
faciliteren van proefimplementaties en het delen van voorbeelden en best practices.
Standaardisatie
In de NORA wordt gewerkt aan het beter in samenhang duiden van onderwerpen die nu afzonderlijk zijn
beschreven. Daartoe is in de NORA gebruikersraad van september 2023 een opzet besproken van
onderwerpen die raken aan het thema Semantiek en Gegevensmanagement.
42 - Capabilities
Capabilities (bekwaamheden) is een term die in het verleden is gebruikt, maar nu is vervangen door de term stelselfuncties.
De term capabilities wordt niet meer gehanteerd, stelselfuncties en capabilities zijn samengevoegd tot
stelselfuncties.
Deze stelselfunctie beschrijft hoe de uitwisseling van gegevens via services kan
worden gestandaardiseerd. Dit heeft betrekking op de wijze waarop Application
Programming Interfaces (API’s) worden vormgegeven. Het standaardiseren van
API’s vergemakkelijkt het uitwisselen van gegevens, in het bijzonder voor
afnemers die gegevens van verschillende aanbieders combineren.
Als een afnemer processen uitvoert die gegevens vergen van de aanbieder, kan de afnemer een bevraging
uitvoeren naar een dataservice van de aanbieder. Als antwoord op deze bevraging ontvangt de afnemer
de gevraagde gegevens zodat de afnemer deze kan verwerken. Voor het uitvoeren van sommige processen zullen
echter afnemers een signaal nodig hebben dat aangeeft dat er een gebeurtenis heeft plaatsgevonden,
zoals de geboorte van een kind. Een afnemer kan periodiek bevragen of er wijzigingen hebben plaatsgevonden (‘polling’), maar over het algemeen is het effectiever als de aanbieder een signaal verstuurt naar
de afnemer. Het door de aanbieder aan de afnemer versturen van een signaal noemen we notificeren. De
patronen bevragen en notificeren zijn de basisuitwisselpatronen binnen FDS.
Bevragen binnen FDS
Bevraging heeft betrekking op het ophalen van kenmerken van entiteiten zoals personen, organisaties, locaties
etc, maar ook op kenmerken van gebeurtenissen zoals een geboorte, een correctie of de vaststelling
van een jaarinkomen. Vanuit het oogpunt van dataminimalisatie dient de afnemer in te kunnen (laten) perken welke
entiteiten en welk kenmerken van deze entiteiten het ontvangt. Inperking kan door deze in de
gestelde vraag op te nemen, door de inperking in de Toegang in te richten, of
door een combinatie van deze twee methodes.
Bevraging kent diverse verschijningsvormen, zoals:
‘sleutelbevraging’: kenmerken van een entiteit ophalen op basis van een sleutel (zoals het bsn van een persoon).
‘zoekbevraging’: het vinden van een entiteit op basis van kenmerken die het object (potentieel)
niet uniek identificeren (bijvoorbeeld de voornamen, de geslachtsnaam en de geboortedatum van een persoon).
‘bulkbevraging’: het ophalen van kenmerken van verschillende entiteiten in één keer. Een variant van
een bulkbevraging is de ‘selectie’ waarbij in één keer de kenmerken van een (potentieel omvangrijke)
groep entiteiten worden opgehaald. Vanwege de benodigde verwerkingstijd om een selectie samen te stellen
kan het noodzakelijk zijn een ‘selectie’ asynchroon samen te stellen. In dat geval kan de aanbieder de afnemer
notificeren zodra de selectie is samengesteld en kan worden opgehaald, bijvoorbeeld via de
Digikoppeling Koppelvlakstandaard Grote Berichten.
Notificeren binnen FDS
Naast het bevragen van gegevens is het van belang dat de afnemer pro-actief op de hoogte kan worden
gebracht van gebeurtenissen. Dit pro-actief op de hoogte brengen noemen we notificeren. Een notificatie kent
een soort gebeurtenis (wat is er gebeurd) en een subject (wie of wat betreft het). Denk aan de geboorte
van een kind, of de correctie van een belastbaar inkomen. De standaard
NL GOV Profile voor Cloudevents
is geschikt als standaard voor het notificeren.
Bijzondere aandacht verdient het notificeren van correcties. Een afnemer kan rechtsgevolgen verbinden
aan opgevraagde gegevens. In dat geval is het van belang dat de afnemer op de hoogte wordt gebracht van
correcties op deze gegevens, zodat het de rechtsgevolgen kan herzien. Dit betekent enerzijds dat de
aanbieder notificaties moet kunnen sturen van correcties op eerder geleverde gegevens, en anderzijds dat
de afnemer op basis van deze notificaties moet kunnen bepalen welke verwerkingen met rechtsgevolgen
potentieel herzien moeten worden.
Een variant van notificeren is het leveren. Bij leveren worden berichten veelal voorzien van de (gewijzigde)
gegevens zelf. Dit levert echter een kopie van de bron op die ten tijde van verwerking inmiddels kan zijn
verouderd. Zuiverder is daarom om de notificatie alleen te gebruiken als ’trigger’ van een verwerkingsproces,
en de voor de verwerking benodigde actuele gegevens via bevraging op te halen. Dit vereenvoudigt tevens de
dataminimalisatie doordat per verwerkingsstap om minimale data kan worden gevraagd, in plaats dat bij een
aanbieder op voorhand bekend dient te zijn wat de minimale set gegevens is die de afnemer nodig heeft voor
de verwerking.
Ten behoeve van leveren is de
ebMS standaard in
Digikoppeling opgenomen. EbMS is
echter een redelijk ‘zware’ en complexe standaard om te implementeren. Met de introductie van
NL GOV Profile voor Cloudevents
komt er een modernere en eenvoudigere standaard beschikbaar om leveren
te vervangen door notificeren.
Een aanbieder stuurt notificaties vanuit een ‘abonnement’ dat aangeeft voor welke soorten gebeurtenissen
en voor welke populatie een afnemer notificaties wenst te ontvangen. Vanuit het principe van
dataminimalisatie is het onwenselijk dat een afnemer notificaties ontvangt waarop de afnemer geen
verwerking hoeft te laten volgen. Dit raakt aan het inperkende functionaliteit zoals omschreven in de
stelselfunctie Toegang.
De stelselfunctie Identiteit betreft het vermogen om de identiteit van bijvoorbeeld een systeem,
persoon of organisatie met afdoende zekerheid vast te stellen. Dit vindt plaats door gebruik te
maken van identificerende kenmerken (zoals een identificatienummer) en een identificatiemiddel
(zoals een digitaal versleuteld certificaat). Identificatiemiddelen worden gebruikt om de identiteit
van iets of iemand met zekerheid vast te kunnen stellen.
Identificerende kenmerken en identificatiemiddelen kunnen worden beheerd in een Identity Management
(IM) oplossing. Voorbeelden van open-source oplossingen zijn de Keycloak-infrastructuur, het Apache
Syncope IM-platform, het open-source IM-platform van het Shibboleth Consortium en het Fiware
IM-framework.
Het binnen Europa uitgeven van publieke identificatiemiddelen valt onder de
eIDAS regulering.
Binnen het FDS vindt uitwisseling van gegevens plaats tussen een aanbieder en een afnemer. Bij een
uitwisseling binnen het FDS zijn zowel de afnemer als de aanbieder deelnemer van het FDS. Een
deelnemer van het FDS is een organisatie met een publieke taak. Een organisatie kan als deelnemer
worden toegelaten tot het FDS als deze is ingeschreven in het handelsregister als publiekrechtelijk
of privaatrechtelijke rechtspersoon. Daarbij dient een privaatrechtelijke rechtspersoon een
expliciet benoemde wettelijke taak te hebben. Zowel publiekrechtelijke als privaatrechtelijke
rechtspersonen zijn ingeschreven in het handelsregister.
Binnen het FDS kan de deelnemer de daadwerkelijke uitwisseling plaats laten vinden door een
verwerker. Een verwerker is een door de deelnemer aan te wijzen organisatie die de daadwerkelijke
uitwisseling uitvoert. Een verwerker is een Nederlandse rechtspersoon, maar hoeft geen deelnemer te
zijn aan het FDS en hoeft geen publieke taak te vervullen. Een verwerker wordt door de deelnemer
aangewezen in een overeenkomst. Het aanwijzen vindt plaats door het benoemen van een uniek identificerend
kenmerk dat kan worden vastgesteld bij het leggen van de verbinding voor de gegevensuitwisseling.
Bij het uitwisselen van gegevens dient over en weer betrouwbaar vastgesteld te kunnen
worden wat de identiteit van de andere uitwisselende deelnemer is. Indien een verwerker optreed
namens een deelnemer, dient daarbij zowel de identiteit van de verwerker als de identiteit van de
deelnemer vastgesteld te kunnen worden. Een uitzondering hierop vormt Open Data waarbij de
afnemer niet door de aanbieder wordt geïdentificeerd. Of, en in welke mate, binnen het FDS sprake
kan of moet zijn van het uitwisselen van data als anoniem benaderbare Open Data (bijvoorbeeld bij
metadata) dient nog te worden bepaald in te maken afspraken.
Het deelnemen aan het FDS door een organisatie-onderdeel van een rechtspersoon is nog onderwerp van
onderzoek (bijvoorbeeld de Belastingdienst is een organisatie-onderdeel van de publiekrechtelijke
rechtspersoon Ministerie van Financiën).
Identificerende kenmerken
Binnen het FDS toepasbare identificerende kenmerken voor een deelnemer zijn:
De in een uitwisseling te hanteren identificerende kenmerken worden bepaald door de aanbieder.
Binnen het stelsel kunnen echter afspraken worden gemaakt om dit te beperken. Een
deelnemer kan binnen het FDS verschillende identificerende kenmerken hanteren, zolang ze maar
dezelfde organisatie identificeren. Bijvoorbeeld een RSIN, een KvK-nummer, een OIN gebaseerd op
een RSIN en een OIN gebaseerd op een KvK-nummer. Een deelnemer heeft altijd (ook) een
FDS Deelnemer-ID. Binnen het stelsel is een functie voorzien om vanuit
een identificerend kenmerk de Deelnemerkenmerken op te vragen,
waaronder overige door de deelnemer gehanteerde identificerende kenmerken.
Het faciliteren van verschillende identificerende kenmerken maakt het mogelijk om verschillende
soorten identificatiemiddelen binnen het FDS toe te passen. Dit maakt ook bijvoorbeeld migratie
naar nieuw opkomende identificatiemiddelen mogelijk.
In een overeenkomst kunnen andere identificerende kenmerken worden toegepast om de deelnemer of een
door de deelnemer aangewezen verwerker te identificeren, zoals een hostname, public-key thumbprint
of een certificaat-thumbprint.
Certificaten als Identificatiemiddel
Een deelnemer identificeert zich binnen het FDS met behulp van een identificatiemiddel.
Potentieel binnen het FDS toepasbare identificatiemiddelen bij het leggen van een verbinding zijn:
Momenteel worden vooral PKIoverheid certificaten gebruikt met een alleen binnen Nederland gehanteerde
methode om een OIN op een certificaat op te nemen. Binnen Europa begint de generieke standaard
ETSI EN 319 412-1
meer toegepast te worden. Deze methode is ook binnen PKIoverheid toegestaan. Mogelijk is een
migratie naar ETSI EN 319 412-1 een gewenste beweging om binnen FDS te maken.
Een eIDAS QWAC certificaat wordt standaard vertrouwd door de browser. Voor toepassing binnen het FDS
is het wel van belang dat het certificaat een geschikt identificerend kenmerk bevat (zoals het OIN of een
Kvk-nummer). Hierdoor biedt een eIDAS QWAC certificaat mogelijkheden om content hybride
aan te bieden: content die vertrouwd machineleesbaar is, maar ook via een standaard browser
te benaderen is. Dit maakt bijvoorbeeld mogelijk om
Metadata hybride (zowel interpreteerbaar door mensen als door machines)
aan te bieden via de RDFa standaard.
Mogelijk worden ook binnen PKIoverheid in de toekomst eIDAS QWAC certificaten opgenomen.
PKIoverheid kent een transparante besturing en programma van
eisen. Hoe dit is vormgegeven bij andere QWAC certificaten die hierbuiten vallen is nog
volop in beweging, en daarmee ook de mate van vertrouwen die eraan kan worden ontleend.
Binnen het FDS is het mogelijk gegevens uit te wisselen onder een digitale (leverings)overeenkomst.
In een digitale (leverings)overeenkomst is aangegeven wie namens een afnemer of aanbieder gegevens
uitwisselt binnen het FDS. Daarbij kan eventueel een alternatief identificerend kenmerk zoals
een hostname, public-key thumbprint of een certificaat-thumbprint worden toegepast om een deelnemer
te identificeren. Zie hierover ook de stelselfunctie Veiligheid.
Mogelijke identificatiemiddelen voor het ondertekenen van digitale (leverings)overeenkomsten:
Een PKIoverheid Services certificaat tbv ondertekening van digitale documenten is altijd een
eIDAS Qualified eSeal. Andersom is dit niet altijd het geval, er worden (Nederlandse) eIDAS
Qualified eSeals uitgegeven die géén PKIoverheid certificaat zijn.
Of bij het leggen van een verbinding, als een (leverings)overeenkomst wordt toegepast, naast
eIDAS QWAC of
PKIoverheid Services
X.509 certificaat alternatieve,
minder vertrouwde certificaten kunnen worden ingezet is nog onderwerp van onderzoek. Dit
geldt ook voor het toepassen van het
ACME Protocol voor
het geautomatiseerd afgeven van certificaten.
Alternatieve identificatiemiddelen
Certificaten bieden een vertrouwde en beproefde methode om partijen te identificeren. Naast
het toepassen van certificaten om te identificeren zijn er alternatieve
methodes denkbaar:
het toepassen van een API key om toegang te verlenen.
het toepassen van een Self-Souvereign Identity (SSI).
Een API key biedt een authenticatiemechanisme, maar omhelst nog geen standaard
methode om deze te koppelen aan een identiteit. Dit zou kunnen worden ondervangen door
bij het uitgeven gebruik te maken van bijvoorbeeld eHerkenning
om een identiteit te koppelen aan een API key. Deze toepassing biedt echter minder
vertrouwenswaarborgen dan de toepassing van een certificaat. Of binnen het
FDS gebruik gemaakt kan worden van API-keys (al dan niet voor bepaalde categorieën
gegevens) is nog niet beoordeeld.
Bij Self-Souvereign Identities (SSI) controleert een deelnemer zelf zijn digitale identiteit.
Dit principe wordt bijvoorbeeld toegepast bij de
EU Wallet.
Naast wallets voor privé-personen worden in deze context ook wallets voor organisaties
gereguleerd. Het EDI programma houdt zich bezig met de
implementatie in Nederland.
Een voorbeeld van een veel toegepaste standaarden voor SSI is de
Decentralized Identifier (DID) in combinatie
met Verifiable Credentials (VC) en
OpenID for VC.
Binnen de DID standaard dient een (authenticatie)methode te worden geselecteerd
zoals did:web waarbij de houder via
het internet een publieke sleutel ter beschikking stelt of
did:ebsi
waarbij de Europese publieke blockchain
EBSI wordt
gebruikt om de houder te authenticeren.
Alleen authenticeren met een DID is echter niet voldoende om een deelnemer binnen
het FDS te identificeren. Daarvoor dient de deelnemer een bewijs
te presenteren met een aangewezen identificerend kenmerk zoals een KvK-nummer
of OIN, bijvoorbeeld als Verifiable Credential (VC).
Dit bewijs dient te zijn afgegeven door een binnen het FDS vertrouwde partij. Het
afgeven en presenteren van een Verifiable Credentials (VC)
vindt bijvoorbeeld plaats via OpenID for VC. Mogelijk
kunnen de binnen het FDS te hanteren Deelnemerkenmerken
zo worden opgezet dat ze als did:web en/of
als Verifiable Credentials (VC) voor een
identificerend kenmerk kunnen dienen.
Er is veel ontwikkeling op het gebied van Self-Souvereign Identities (SSI), in
het bijzonder als gevolg van de vernieuwing van eIDAS om
Wallets
te reguleren. Een koploper hierbinnen is de ontwikkeling van het Europese
digitale rijbewijs
(NEN-ISO/IEC 18013-5).
Deze ontwikkelingen bieden in de toekomst wellicht mogelijkheden om SSI ook
toe te passen binnen FDS. Dit vergt echter enerzijds dat er voldoende vertrouwen
is in de veiligheid van de authenticatiemethode, en anderzijds dat er een infrastructuur
van vertrouwde partijen ontstaat die een bewijs met een binnen het FDS
bruikbaar identificerend kenmerk kunnen afgeven.
Om data effectief te kunnen gebruiken moet duidelijk zijn in welke context en met welk doel de data
is ontstaan en wat de betekenis ervan is. Om te kunnen weten en begrijpen wat bepaalde data
betekent, beschrijven we deze met metadata.
De NORA definieert metadata (metagegevens) als:
’Gegevens die context, inhoud, structuur en vorm van informatie en het beheer ervan door de tijd heen
beschrijven.‘ Metadata vormt een essentieel fundament onder de werking van het Federatief Datastelsel. De metadata beschrijft onder andere:
welke data binnen het stelsel beschikbaar zijn,
wat de betekenis (semantiek) van die data is,
wat de grondslag is voor het verzamelen van data,
voor welke context de data oorspronkelijk zijn bedoeld,
welke partijen betrokken zijn,
wat de rollen en verantwoordelijkheden zijn van de betrokken partijen,
hoe de data is vormgegeven (onder andere syntax),
hoe de data beschikbaar is (API’s bijvoorbeeld),
wat de kwaliteit van de data en datadiensten is (denk aan juistheid, actualiteit, etc.),
voor wie de data beschikbaar is en onder welke condities.
De metadata geeft potentiële afnemers inzicht in wat, voor wie en onder welke condities binnen
het stelsel beschikbaar is.
De publicatie van metadata in een catalogus is onderdeel van de stelselfunctie
Publicatie.
Binnen het FDS wordt metadata als Linked Data uitgewisseld. Linked data omvat een hele familie aan standaarden en
best practices. Om binnen het FDS effectief Linked Data toe te passen, worden binnen het FDS
Linked Data Design Rules gehanteerd.
Op de volgende vlakken beschrijft FDS de te hanteren structuur van metadata:
Deze stelselfunctie beschrijft hoe gegevens- en informatiemodellen worden gehanteerd
en geven daarmee betekenis en onderlinge samenhang aan de data die wordt uitgewisseld
via Dataservices. De betekenis van gegevens wordt ook wel
uitgedrukt als de semantiek van gegevens. Gegevens- en informatiemodellen
zijn een vorm van Metadata.
Om het potentieel van gegevens optimaal te benutten dienen de betekenis en
onderlinge samenhang van gegevenselementen inzichtelijk te zijn. Het is daarom
cruciaal dat het gegevensmodel van FDS aanbod inzichtelijk is voor (potentiële)
afnemers. Dit gaat verder dan het benoemen van de gegevenselementen en de
onderlinge samenhang. Elk gegevenselement dient voorzien te zijn van
een duidelijke definitie en de context waarbinnen het gegeven is ingezameld. Deze
informatie is essentieel voor afnemers om goed te kunnen beoordelen hoe bruikbaar
gegevens zijn voor hun beoogde doel.
Informatiemodellen zijn op te delen in een aantal beschouwingsniveaus, zo is
er onderscheid te maken tussen een model van begrippen, een conceptueel
informatiemodel, een logisch informatie- of gegevensmodel en een fysiek of
technisch gegevens- of datamodel.
Model van begrippen
Een model van begrippen bevat een begrippenkader waarbinnen begrippen van
betekenis en onderlinge samenhang worden voorzien. Een begrippenkader wordt uitgedrukt
met behulp van de standaard
NL-SBB op basis van op de
internationale standaard SKOS.
Conceptueel informatiemodel en logisch informatie- of gegevensmodel
Een conceptueel informatiemodel geeft een zo getrouw mogelijke beschrijving van die werkelijkheid
en is in natuurlijke taal geformuleerd. Een conceptuele informatiemodel richt zich specifiek op
de semantiek van dingen en hun eigenschappen. Het conceptuele informatiemodel richt zich op het ‘wat’.
Een logisch informatie- of gegevensmodel beschrijft hoe concepten gebruikt worden bij de interactie
tussen systemen en hun gebruikers en tussen systemen onderling. Het gaat hierbij, in tegenstelling tot
een conceptueel model, dus veel meer om het ‘hoe’.
De standaard MIM
biedt handvatten om invulling te geven aan een conceptueel informatiemodel
en een logisch informatie- of gegevensmodel. Binnen
MIM kunnen deze
modellen worden uitgedrukt met ‘klassieke’ modelleertechnieken zoals
UML en
ERD,
die veel worden toegepast bij objectgeoriënteerd modellen en
relationele modellen. Deze modelleertechnieken zijn echter sterk
geënt op het in isolatie modelleren van gegevens en bieden weinig handvatten
om informatiemodellen onderling met elkaar te verbinden.
Grote potentie zit echter in het onderling verbinden van datasets die
traditioneel alleen in silo’s beschikbaar zijn. Het concept van linked
data geeft invulling aan deze behoefte via een vorm van modelleren
waarbij onderlinge verbondenheid in de basis is verwerkt. Bij linked data
loopt het conceptuele informatiemodel en het logische informatiemodel in
elkaar over. Linked data kent de volgende elkaar aanvullende standaarden
voor het vormgeven van informatiemodellen:
RDF,
RDFS,
OWL en
SHACL.
UML en
ERD enerzijds
en de set aan linked data standaarden anderzijds zijn niet eenvoudig
naar elkaar om te zetten. Dat maakt het een uitdaging binnen FDS om
modellen uitgedrukt in
UML of
ERD
te verbinden met elkaar of met linked data modellen. Overigens
definieert MIM hoe een
MIM(UML)-model als linked data kan worden uitgedrukt en uitgewisseld. Dat maakt het
uitgedrukte MIM-model echter nog geen linked data model, het betreft geen
vertaling van UML of ERD naar OWL
en/of SHACL (of vice versa). Het
betreft een UML-model dat kan worden gelezen als linked data, zoals elk
verzameling van informatieobjecten in principe kan worden uitgedrukt als linked data.
Technisch gegevens- of datamodel
De uiteindelijke gegevensuitwisseling vindt plaats via een API. Het gegevensmodel
dat de API hanteert is het technische gegevens- of datamodel. Voor REST-API’s
wordt dit uitgedrukt met de
Open API Specification.
Indien de REST-API gegevens uitwisselt in de vorm van
JSON-LD, kan dit direct worden
gekoppeld aan een informatiemodel uitgedrukt in linked-data.
Voor andere vormen van koppeling, bijvoorbeeld aan een model uitgedrukt
in UML, is
verder onderzoek en/of verdere standaardisatie nodig.
Informatiemodellen en traceerbaarheid
In de stelselfunctie Traceerbaarheid wordt de behoefte
aan traceerbaarheid geformuleerd. Ook deze traceerbaarheid wordt uitgedrukt in
gegevens die vormgegeven worden in een informatiemodel, uitgedrukt in aspecten
als gebeurtenissen, correcties, verantwoording, twijfel, onderzoek en periodes
van registratie en geldigheid. Op dit vlak is nog veel onderzoek te doen.
Binnen het project Uit betrouwbare bron
wordt getracht patronen en definities op te stellen die ondersteunen
bij het opzetten van een effectief informatiemodel dat recht doet aan deze
aspecten.
Informatiekundige kern
De ambitie van FDS is om de verschillende gegevensbronnen onderling aan elkaar te koppelen.
In feite de stap om van datasilo’s naar onderling verbonden ’linked’ datasets te gaan. Dit
gaat verder dan de te hanteren modelleertechnieken. Deze verbinding komt namelijk alsnog
niet tot stand als voor identificatie benodigde sleutelwaarden zoals een BSN
niet afdoende aanwezig zijn in de betreffende datasets.
Een belangrijke stap naar het koppelbaar maken van datasets bestaat uit de
Informatiekundige kern van het FDS.
De mate van koppelbaarheid wordt bepaald door overeenkomstige data-elementen
in verschillende bronnen. Hoe hoger de zekerheid dat data-elementen qua semantiek
en feitelijke waarden overeenkomen hoe hoger de koppelbaarheid.
De informatiekundige kern draagt hieraan bij door afspraken over te maken over
de koppelbaarheid. De informatiekundige kern stelt dat binnen het FDS wordt
afgesproken hoe de kernobjecten persoon, organisatie en locatie worden geïdentificeerd.
Veel sectorregistraties
bevatten informatie over personen, organisaties en/of locaties. Het harmoniseren van de
identificatie van personen, organisaties en locaties ondersteunt het onderling
aan elkaar koppelen van al deze datasets.
Om het aanbod van databronnen en -diensten onder gedefinieerde voorwaarden te ondersteunen, moeten
inzichtelijk zijn wat beschikbaar is. Deze stelselfunctie ondersteunt de publicatie van het aanbod
zodat een afnemer het aanbod kan vinden en kan beoordelen of het zinvol kan en mag worden afgenomen.
Het aanbod van het FDS wordt gepubliceerd in een catalogus. Er is één officiële FDS-catalogus
die het volledige aanbod binnen het FDS ter beschikking stelt aan geïnteresseerden. Daarnaast
kunnen er alternatieve catalogi zijn die (delen van) het FDS aanbod publiceren, zoals sectorale
en/of international catalogi die het FDS aanbod opgenomen hebben als onderdeel van een breder
(informatie)aanbod.
Een catalogus is niet zelf de bron van de gepubliceerde metadata, maar verzamelt het aanbod
vanuit door aanbieders gepubliceerde linked data bestanden met metadata zoals beschreven in
Aanbod (metadata). De aanbieder is verantwoordelijk voor
het aanbieden van het bestand met metadata volgens de richtlijnen van het FDS (self-description).
Deze bestanden vormen de bron voor catalogi.
De FDS-Catalogus
Via de FDS-catalogus is het aanbod inclusief de daarover beschikbare Metadata
publiek inzichtelijk voor geïnteresseerden (voor zover het geen individuele uitwisselingen
betreft). Dit betreft het doorzoekbaar en beschikbaar maken in een voor geïnteresseerden
passende vorm, zowel richting systemen als personen.
Ten behoeve van personen wordt een webapplicatie aangeboden. Informatie ontsloten naar personen
wordt ook machine-interpreteerbaar aangeboden (met behulp van
RDFa), naar behoefte al dan
niet aangevuld met alternatieve linked data formaten (zoals
Turtle, JSON-LD
en/of RDF-XML)
en een SPARQL API ten behoeve van het vrij
kunnen bevragen van de beschikbare metadata.
De FDS-catalogus is een vertrouwde vindplaats van FDS metadata. Dit impliceert onder
andere het toepassen van https en een binnen het FDS vertrouwd certificaat. Daarnaast
dient de catalogus alleen geverifieerde metadata ter beschikking te stellen vanuit
vertrouwde bronnen. De FDS-catalogus kan ander (niet-FDS) aanbod bevatten. Het onderscheid
met niet-FDS aanbod dient echter duidelijk aanwezig te zijn.
De FDS-catalogus is actueel en compleet. Binnen het FDS worden afspraken gemaakt welke
metadata via de catalogus wordt gepubliceerd. De catalogus publiceert alle volgens de
FDS-criteria valide metadata die binnen deze afspraken valt. Daarnaast worden
binnen het FDS afspraken gemaakt met betrekking tot de actualiteit van de gepubliceerde
metadata.
Deze stelselfunctie bepaalt of, en in welke mate, toegang wordt verleend tot aangeboden gegevens.
Zowel de aanbieder als de afnemer implementeert mechanismen voor datatoegang om misbruik van
gegevens te voorkomen. Toegang vertrouwt op betrouwbaar geïdentificeerde partijen zoals omschreven
in de stelselfuncties Identiteit en Veiligheid.
De stelselfunctie toegang ondersteunt de organisatorische stelselfunctie van
poortwachter.
Toegangsverlening kent beperkingen op verschillende niveau’s:
Het bepalen of een verbinding wordt aangegaan
Het bepalen of een gegevensvraag mag worden gesteld
Het bepalen of gegevens betreffende een entiteit worden geleverd
Het bepalen welke gegevens van een entiteit worden geleverd
Implementatie van deze beperkingen kan worden uitgedrukt in bijvoorbeeld Policies. Voor
de FSC standaard is een extensie in ontwikkeling om policies met FSC te combineren.
Zowel de aanbieder als de afnemer hebben een verantwoordelijkheid bij een zorgvuldige levering.
Beide partijen dienen daar waar nodig beperkingen toe te passen. Wie welke beperkingen toepast is
onderhevig aan onderlinge en stelselbrede te maken afspraken.
In het bijzonder bij persoonsgegevens worden beperkingen dusdanig ingericht dat alleen de minimaal
ten behoeve van de grondslag benodigde gegevens worden uitgewisseld (dataminimalisatie).
Er is een beperkt aantal standaarden met betrekking tot toegangsverlening, bijvoorbeeld
ODRL en
XACML. Welke standaarden
geschikt zijn in de context van FDS is nog onderwerp van onderzoek. Zie in dit kader ook de
resultaten van de projecten Lock-Unlock en Federatieve
toegangsverlening.
De stelselfunctie Traceerbaarheid biedt de middelen voor tracering en tracking in het proces van
dataverstrekking en dataverbruik/gebruik. Het biedt daardoor de basis voor een aantal belangrijke
functies, van identificatie van de lijn van gegevens tot auditbestendige logboekregistratie van
transacties.
In de context van traceerbaarheid worden ook termen als lineage en provenance gebruikt. Deze drie
termen hebben subtiel verschillende betekenissen die allen betrekking hebben op de inzichtelijkheid
in de herkomst, totstandkoming en het gebruik van data. Traceerbaarheid richt zich op het volgen van
van gegevens door ketens, lineage richt zich meer op de bewerkingen die de data hebben ondergaan en
provenance richt zich meer op de betrouwbaarheid en authenticiteit van gegevens. Binnen FDS maken
we geen onderscheid tussen traceerbaarheid, lineage en provenance en vatten we elk van deze vormen
onder de stelselfunctie Traceerbaarheid.
Een standaard voor traceerbaarheid (gericht op provenance) is de PROV
familie van standaarden.
Afnemers binnen het FDS maken gebruik van gegevens die ze verkrijgen via FDS om wettelijke taken
uit te voeren. Om te kunnen verantwoorden welke gegevens zijn gebruikt, dient uitwisseling binnen
het FDS traceerbaar te zijn. Concreet kan dit betekenen dat voor een verantwoorde verwerking
nodig is dat:
Inzichtelijk is wanneer welke gegevens zijn afgenomen en voor welke verwerking de afnemer deze
gegevens heeft gebruikt.
De aanbieder inzichtelijk maakt hoe geleverde gegevens tot stand zijn gekomen en welke zekerheden
er aan de gegevens zijn te ontlenen, bijvoorbeeld dat geboortegegevens van een persoon zijn ontleend
aan een Nederlandse geboorteakte of aan een eigen verklaring door de betrokkene.
Inzichtelijk is welke eerder geleverde gegevens zijn gecorrigeerd. Indien gegevens bij een
aanbieder worden gecorrigeerd, dient een afnemer effectief te kunnen bepalen of hij betreffende
gegevens heeft gebruikt in handelingen (in het bijzonder handelingen met rechtsgevolgen). De
afnemer dient deze handelingen immers mogelijk te herzien. Zie ook notificeren onder de stelselfunctie
Dataservices.
Voor een betrokken persoon dient inzichtelijk te zijn welke (persoons)gegevens
wanneer door een aanbieder aan welke afnemer is geleverd, in welke verdere verwerkingen de
gegevens zijn gebruikt, voor welk doel (doelbinding) en onder welke
grondslag.
De mate van het benodigde inzicht is afhankelijk van het soort verwerking. Voor welke termijn
het genoemde inzicht beschikbaar dient te blijven is afhankelijk van het gebruik.
Aanbieder en afnemers stemmen dit met elkaar af daar waar ze van elkaar afhankelijk zijn.
Mogelijk kunnen binnen FDS afspraken worden gemaakt om bijvoorbeeld gradaties of typeringen
van traceerbaarheid te onderscheiden en/of de mate van traceerbaarheid te standaardiseren.
Daar waar sprake is van de inzet van een verwerker zoals benoemd in de stelselfunctie
Identiteit is dit inzichtelijk.
Voor traceerbaarheid benodigde gegevens worden, onder andere, geregistreerd in logboeken.
Beschikbare standaarden voor deze logboeken zijn:
Een centrale rol binnen de traceerbaarheid vormt de datadeelrelatie die wordt
gebruikt om de gegevens uit te wisselen:
Traceerbaarheid binnen FDS
Om beschikbaar te hebben welke gegevens zijn gebruikt in een verwerking kunnen
afnemers een kopie bijhouden van door een aanbieder geleverde gegevens, bijvoorbeeld
in een berichtenlog. Veelal biedt een aanbieder niet de mogelijkheid om gegarandeerd
exact eerder geleverde gegevens opnieuw op te kunnen vragen, bijvoorbeeld
omdat er geen afdoende gegarandeerde bewaartermijn is of omdat na een correctie
eerder geleverde gegevens niet meer reproduceerbaar zijn. Indien daar behoefte
aan bestaat kunnen binnen FDS mogelijk afspraken worden gemaakt om inzichtelijk te
maken of en hoe dataservices van de aanbieder kunnen worden ingezet om
eerder geleverde gegevens te reproduceren.
Deze stelselfunctie faciliteert de vertrouwde data-uitwisseling onder deelnemers, waardoor deelnemers in
een data-uitwisselingstransactie geruststellen dat die andere deelnemers echt zijn wie zij beweren
te zijn en dat zij voldoen aan gedefinieerde regels/overeenkomsten. Dit kan worden bereikt door
organisatorische maatregelen (bijv. certificering of geverifieerde referenties) of technische
maatregelen (bijvoorbeeld attestatie op afstand).
Binnen het FDS worden gegevens uitgewisseld over een beveiligde verbinding (zoals
HTTPS) waarbij zowel de
aanbieder als de ontvanger worden geïdentificeerd met behulp van een betrouwbaar
identificatiemiddel.
Voor zowel de aanbieder als de ontvanger geldt dat deze een verwerker de daadwerkelijke uitwisseling
kan laten uitvoeren. Deze verwerker dient in dat geval een eigen
identificatiemiddel te gebruiken die
betreffende verwerker identificeert. Een verwerker hoeft geen deelnemer te zijn binnen FDS. Wel
dient betrouwbaar navolgbaar te zijn namens welke deelnemer de verwerker gegevens uitwisselt.
Daarnaast dient er een overeenkomst te bestaan waaruit onomstotelijk kan worden afgeleid dat de
deelnemer aangeeft dat de verwerker onder verantwoordelijkheid van de deelnemer gegevens mag
uitwisselen.
Of binnen het FDS ook informatie wordt uitgewisseld waarbij de afnemer anoniem kan blijven (Open
Data) is nog onderwerp van onderzoek. Indien gegevens worden aangeboden aan zich identificerende
afnemers, sluit dit niet uit dat deze aanbieder de gegevens ook als Open Data aanbiedt. Het is
echter nog onderwerp van onderzoek of dit aanbod als Open Data binnen het FDS kan vallen.
Het netwerk dat de aanbieder gebruikt om gegevens aan te bieden dient inzichtelijk zijn in de
metadata van het aanbod. Een aanbieder kan binnen het FDS gegevens aanbieden
via het internet, via DigiNetwerk, of beide.
Veiligheid met FSC
Bij FSC worden zowel verzender als ontvanger geïdentificeerd met een digitaal
certificaat (mutual TLS). Daarbij vindt
binnen FSC uitwisseling plaats onder een digitaal contract. In dit contract zijn
identificerende kenmerken van beide uitwisselende partijen opgenomen, voor de aanroepende partij via
een ‘public key thumbprint’ en voor de aangeroepen partij via een ‘hostname’ van het API endpoint.
In de context van FDS wordt het FSC-contract digitaal ondertekend door zowel de aanbieder als de
afnemer. Dit identificeert de aanbieder en de afnemer op een betrouwbare manier. In het contract
zijn identificerende kenmerken opgenomen die (via de gebruikte certificaten) leiden tot het
betrouwbaar identificeren van de feitelijk uitwisselende partijen. Dit betreft de aanbieder of
afnemer zelf of de door de aanbieder of afnemer ingeschakelde verwerker.